






首先构造一个语料库,由6句话组成,每句话3个字。
corpus = '她很香 她很菜 她很好 他很菜 他很好 菜很好'.split()
构造一个字典,存储一元的字数
Count1={}
遍历语料库,把每个字出现的次数存储在字典中。
for sentence in corpus:
for word in sentence:
if word in Count1:
Count1[word]+=1 #如果word在字典中存在
else:
Count1[word]=1 #否则就新建一个字典项,键为word,值为1
结果如下:
Count1
{'她': 3, '很': 6, '香': 1, '菜': 3, '好': 3, '他': 2}
再构造一个字典P1存储一元概率。
P1={}
total=0 #语料库总字数
for key in Count1:
total+=Count1[key]
语料库中的总字数
total
18
每个字的出现的次数除以语料库总字数
for key in Count1:
P1[key]=Count1[key]/total
P1
{'她': 0.16666666666666666, '很': 0.3333333333333333, '香': 0.05555555555555555, '菜': 0.16666666666666666, '好': 0.16666666666666666, '他': 0.1111111111111111}
至此,一元概率已完成。下面计算二元的次数。
把字典中的字按照row,col排成二维的,纵横交叉处即为该两两组合出现的次数。
需要注意的是,这里的两两组合区分先后,例如,“她很”出现了3次,而“很她”出现了0次。
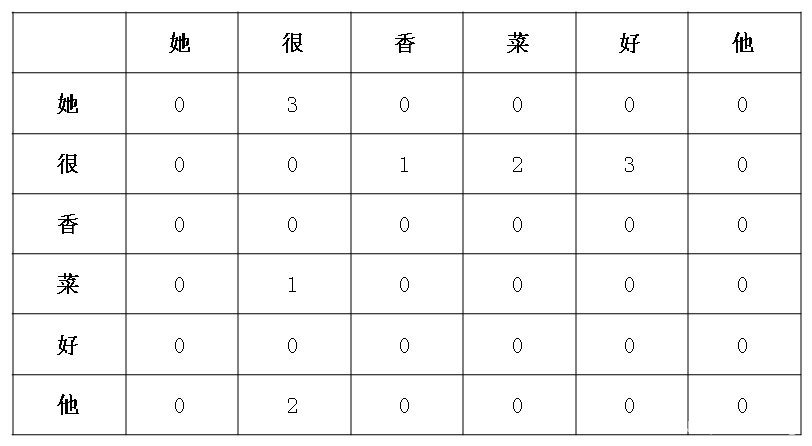
dictionary=list(Count1.keys()) #字典转化成列表
Count2={}
for row in dictionary:
for col in dictionary:
Count2[row+col]=0
for sentence in corpus:
Count2[row+col]+=sentence.count(row+col) #统计字符串中某子串出现的次数
Count2
{'她她': 0, '她很': 3, '她香': 0, '她菜': 0, '她好': 0, '她他': 0, '很她': 0, '很很': 0, '很香': 1, '很菜': 2, '很好': 3, '很他': 0, '香她': 0, '香很': 0, '香香': 0, '香菜': 0, '香好': 0, '香他': 0, '菜她': 0, '菜很': 1, '菜香': 0, '菜菜': 0, '菜好': 0, '菜他': 0, '好她': 0, '好很': 0, '好香': 0, '好菜': 0, '好好': 0, '好他': 0, '他她': 0, '他很': 2, '他香': 0, '他菜': 0, '他好': 0, '他他': 0}
下面计算二元概率:
P2={}
V=len(Count1) #字典数
for row in dictionary:
for col in dictionary:
P2[row+col]=(Count2[row+col]+1)/(Count1[row]+V)#平滑处理
结果如下:
P2
{'她她': 0.1111111111111111, '她很': 0.4444444444444444, '她香': 0.1111111111111111, '她菜': 0.1111111111111111, '她好': 0.1111111111111111, '她他': 0.1111111111111111, '很她': 0.08333333333333333, '很很': 0.08333333333333333, '很香': 0.16666666666666666, '很菜': 0.25, '很好': 0.3333333333333333, '很他': 0.08333333333333333, '香她': 0.14285714285714285, '香很': 0.14285714285714285, '香香': 0.14285714285714285, '香菜': 0.14285714285714285, '香好': 0.14285714285714285, '香他': 0.14285714285714285, '菜她': 0.1111111111111111, '菜很': 0.2222222222222222, '菜香': 0.1111111111111111, '菜菜': 0.1111111111111111, '菜好': 0.1111111111111111, '菜他': 0.1111111111111111, '好她': 0.1111111111111111, '好很': 0.1111111111111111, '好香': 0.1111111111111111, '好菜': 0.1111111111111111, '好好': 0.1111111111111111, '好他': 0.1111111111111111, '他她': 0.125, '他很': 0.375, '他香': 0.125, '他菜': 0.125, '他好': 0.125, '他他': 0.125}
测试两个新文本的概率:
P1['菜']*P2['菜很']*P2['很香']
0.006172839506172839
P1['香']*P2['香很']*P2['很他']
0.0006613756613756613
以下是函数形式的测试:
def P(txt):
res=P1[txt[0]]
for i in range(len(txt)-1):
res*=P2[txt[i]+txt[i+1]]
return res
P('菜很香')
0.006172839506172839
P('香很他')
0.0006613756613756613














 1241
1241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









