







转载自一线码农-博客园 原文地址Sql Server之旅——第三站 解惑那些背了多年聚集索引的人
主要根据博文中的内容在本地的数据库上操作,同时添加一些零散的内容,以作记录。
树结构中比较简单的是二叉树,查找的效率和树的高度相关,但是在插入操作时,树的高度可能无法保持最小高度,甚至会退化成链表。
为了限制树的高度,引入了平衡二叉树,每次增删节点时进行一些调整操作,以保持查找的效率。
而在数据库系统中,比较常用的索引存储结构就是B树,每个节点中存储尽量多的键值,以降低树的高度。
B树的简单示意图:
节点中的键值为子节点中的最小值,所以查找时需要找到节点中最后一个小于或者等于当前查找值的键值,然后根据它的指针再到子节点中继续查找,重复以上过程,直到找到查找的记录行为止。
1.当前的数据量比较少,从根节点可以直接找到节点的指针,然后再浏览数据页节点,找到对应的记录行
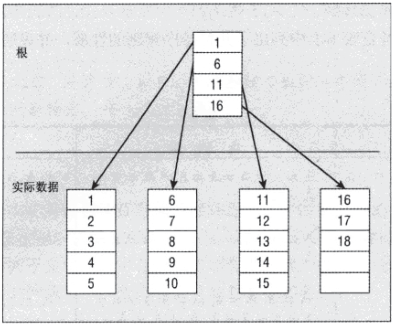
2.在数据量比较大的情况下,会有多层的非页级节点
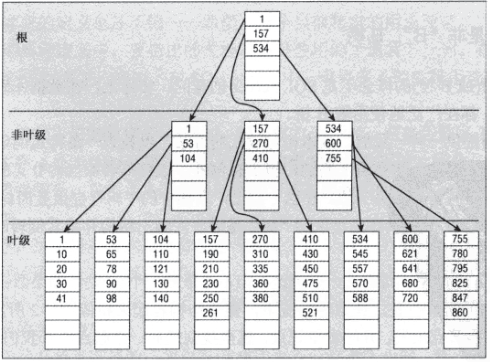
查看数据库中指定表的数据页记录的内容需要用到page命令
--page命令的参数信息:page ( {'dbname' | dbid}, filenum, pagenum [, printopt={0|1|2|3} ])
--开启3604跟踪
DBCC TRACEON(3604)
--查看指定数据页内容
DBCC PAGE(Ctrip,1,78,2)聚集索引中比较关键的是页级节点就是数据页本身,数据页尾部的槽位数组已经按照页中记录行的聚集索引列排过序,类似上图中所示,也因此每个表最多只能有一个聚集索引。
如果是非页级节点或者是根节点,则只需要记录子页的ID和子页中索引列的最小值,对于这一类索引页,可以用另外的格式显示其中的key值和子页的ID。
--查看指定非页级索引页内容
DBCC PAGE(Ctrip,1,78,3)由于聚集索引中页节点的记录本身是有序的(物理上不一定有序,但是数据页尾部的槽位数组会进行排序),所以在新增记录的时候,如果当前页已满并且新纪录的键值大概是当前页的中间值,则会引起页拆分,新增一个数据页,同时还要把旧数据页中的一般记录复制过来。在页拆分的过程中,也可能会产生一些级联的操作,子页的拆分导致父页中也要进行页拆分,一直向上传递,最终引起根节点的拆分。所以页拆分操作对性能会有比较大的影响。
如果需要频繁地对表进行一些修改或者插入操作,而且插入操作是不连续的时候,就需要考虑不使用聚集索引了。















 1377
1377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









