






一、三种算法的联系和区别
做完了线性回归和逻辑回归案例之后,我们这次做一个简单的决策树案例,首先我们先来看看这三者之间有什么联系和区别:
任务类型:
线性回归:用于回归任务,预测连续变量。例如,预测房价、温度等。
逻辑回归:用于二分类任务,预测类别标签(0/1)。例如,预测某个客户是否会购买产品。
决策树:可以用于分类任务,也可以用于回归任务。分类任务中输出类别(如是否游玩),回归任务中输出连续值(如房价预测)。
模型结构:
线性回归:线性模型,其形式是线性函数:
![]()
逻辑回归:本质上是线性模型的一种,但通过Sigmoid函数将线性组合映射到0到1之间的概率值,适用于分类任务:

最终输出是样本属于某个类别的概率。
决策树:树形结构,通过根据不同特征的取值递归地划分数据集,生成节点和分支,直到最终得到叶节点。决策树不依赖线性关系,能捕捉特征的非线性相互作用。
联系:
都可以用于解决分类问题(线性回归用于回归,逻辑回归和决策树用于分类)。 都是监督学习算法,都需要标签数据进行训练。 逻辑回归和线性回归本质上都属于线性模型,而决策树属于非线性模型。
区别:
模型的本质不同:线性回归和逻辑回归都是线性模型,决策树是非线性模型。 特征的处理方式不同:线性回归和逻辑回归关注所有特征的线性组合,而决策树是基于单个特征的分割,不需要所有特征参与。 可解释性与灵活性:决策树的可解释性更强,但容易过拟合;线性回归模型简单且易于解释,逻辑回归适合处理二分类问题。
二、决策树的简单案例
本文将模拟一个根据今日天气指标来判断是否适合出游任务:
1、准备一个简单的决策依据表和数据集

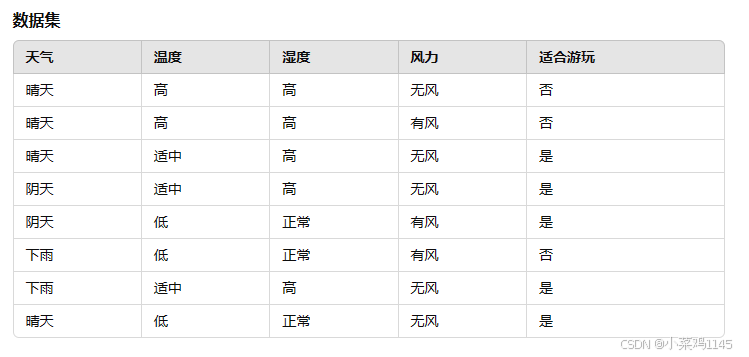
2、导入必要的库和创建数据集
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
# 准备数据
data = {
'天气': ['晴天', '晴天', '晴天', '阴天', '阴天', '下雨', '下雨', '晴天'],
'温度': ['高', '高', '适中', '适中', '低', '低', '适中', '低'],
'湿度': ['高', '高', '高', '高', '正常', '正常', '高', '正常'],
'风力': ['无风', '有风', '无风', '无风', '有风', '有风', '无风', '无风'],
'适合游玩': ['否', '否', '是', '是', '是', '否', '是', '是']
}
df = pd.DataFrame(data)
sklearn.tree.DecisionTreeClassifier: 这是scikit-learn库中的决策树分类器,用于分类任务。我们将使用它来训练一个模型。
data:这是一个字典,包含了天气、温度、湿度、风力以及是否适合游玩的数据。每列是一个特征,最后一列(适合游玩)是目标变量。
pd.DataFrame(data): 使用pandas将字典data转换为一个DataFrame格式。这样可以方便后续的数据处理和模型训练。
3、划分x、y并将其转化为数字编码
# 特征和目标变量
X = df[['天气', '温度', '湿度', '风力']]
y = df['适合游玩']
# 将类别特征转换为数字编码
X = pd.get_dummies(X)X: 取出特征列,包含天气、温度、湿度和风力。
y: 取出目标列,即是否适合游玩。
pd.get_dummies(X):使用pandas的get_dummies函数将类别型特征(如天气、温度等)转换为独热编码(one-hot encoding)。每个类别会被转换为一个独立的列,列值为0或1。例如,“天气”列中的“晴天”会被拆分为天气_晴天,并将其值编码为1或0。这样做是因为机器学习模型无法直接处理字符串类型的数据,需要将其转化为数值。
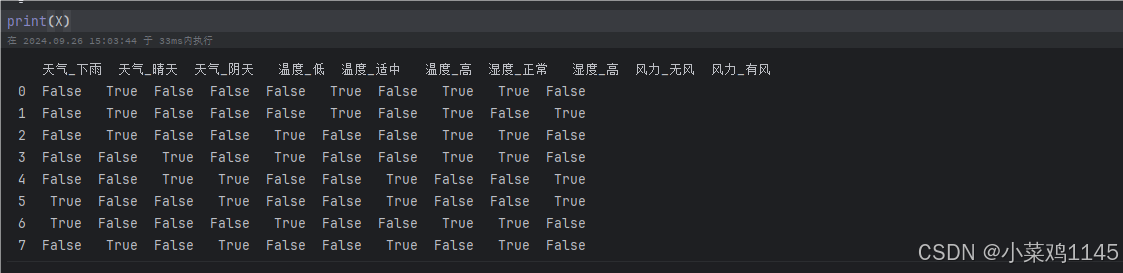
这里将天气、温度、湿度、风力分为三种,其中一种为ture时其他两种为false,举个例子,天气晴、温度高、湿度高、风力无的时候应该是对应010,001,01,10(true为1,false为0).
为什么需要pd.get_dummies()?
机器学习模型不能直接处理非数值型的数据(例如 "晴天"、"阴天" 这样的文字)。所以,必须将这些类别特征转换为数值形式,通常通过这种独热编码的方式。 pd.get_dummies() 会自动帮你完成这种转换,使得每个类别都用数值型的列来表示。
4、创建并训练决策树模块
model = DecisionTreeClassifier(criterion='entropy')
model.fit(X, y)DecisionTreeClassifier(criterion='entropy'):DecisionTreeClassifier: 创建一个决策树分类器。 criterion='entropy': 决策树的分裂标准设置为信息增益,即使用entropy(熵)来衡量数据的纯度(另一种常用标准是gini)。
model.fit(X, y):fit:使用特征数据X和目标变量y来训练模型。训练过程中,决策树会根据特征将数据进行划分,以最大化信息增益,构建出树状模型。
5、对训练的模型进行训练
# 预测
test = pd.DataFrame({'天气': ['晴天'], '温度': ['高'], '湿度': ['高'], '风力': ['无风']})
test = pd.get_dummies(test)
test = test.reindex(columns=X.columns, fill_value=0)
prediction = model.predict(test)
print(f"预测结果: {prediction[0]}") 
准备测试数据:
pd.DataFrame({'天气': ['晴天'], '温度': ['高'], '湿度': ['高'], '风力': ['无风']}): 创建一个DataFrame,包含一组新的测试数据。这里的测试数据表示天气是“晴天”、温度“高”、湿度“高”、风力“无风”。
对测试数据进行独热编码:
test = pd.get_dummies(test):同样使用get_dummies将测试数据中的类别特征转换为数值编码,和训练数据格式一致。
对齐列:
test = test.reindex(columns=X.columns, fill_value=0):因为测试数据可能缺少某些类别(如“温度_低”),通过reindex函数确保测试数据的列与训练数据的列对齐,缺失的列用0填充。
进行预测:
model.predict(test):使用训练好的决策树模型对新数据进行预测。模型会根据新样本的特征值沿着树的分支做出决策,最终返回预测结果(晴天天气又热确实不太适合出去玩儿~)。
最后我们再来测试几组看看效果怎么样:
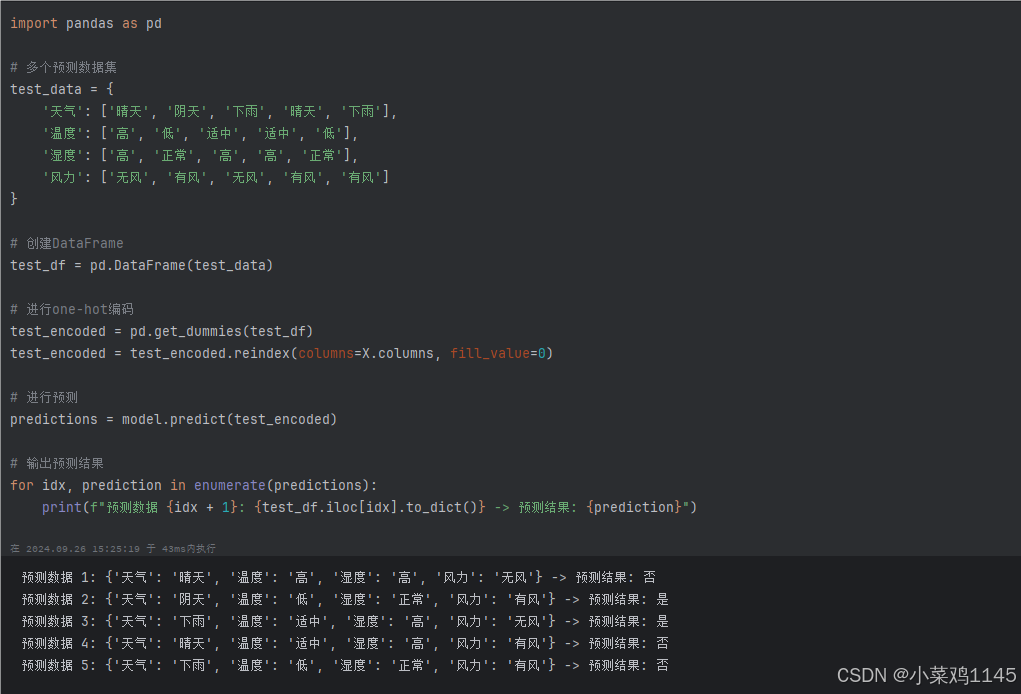
显示下雨温度适中(无风情况下)也推荐出去玩,可以再加上一个雨是否下的大的影响因素进行改进,不然下大雨我觉得还是待在室内比较靠谱。
三、结语
本文对决策树算法进行一个简单的运用,可以看到仅用代码实现的话是比较简单的,但里面涉及到的原理可能比较复杂,需要感兴趣的读者自行再去深入研究,我觉得这个简单的案例其实可以用在天气预测下面有个今日推荐上面,类似于:

最后,大家如果觉得对您有帮助的话麻烦点点赞,如果有错误或者纰漏希望您能在评论区指出,帮助大家能更好地理解和掌握相关知识!

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









