







1.文本编码
bert模型的输入是文本,需要将其编码为模型计算机语言能识别的编码。这里将文本根据词典编码为数字,称之为token embedding;当输入的是两句话时,用[SEP]标志分隔,得到segment embedding,前一句对应元素的编码为0,那么后一句编码为1. 输入 文本的元素位置信息,做position embedding。这三个embedding组合起来作为模型的输入。
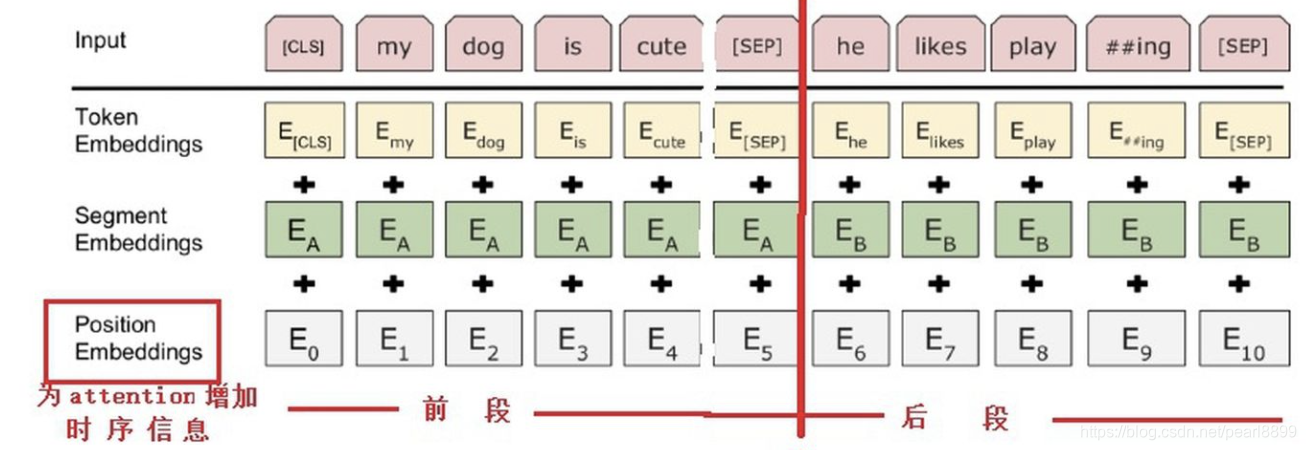
但是,在只有一句话的情况下,则可以不用segment embedding。 输入中,只有token embedding是必须的,其他的embedding,可有可无,看你需要。
1.1tokenizer基本含义
tokenizer就是分词器; 只不过在bert里和我们理解的中文分词不太一样,主要不是分词方法的问题,bert里基本都是最大匹配方法。
最大的不同在于“词”的理解和定义。 比如:中文基本是字为单位。
英文则是subword的概念,例如将"unwanted"分解成[“un”, “##want”, “##ed”] 请仔细理解这个做法的优点。
1.2bert里涉及的tokenizer
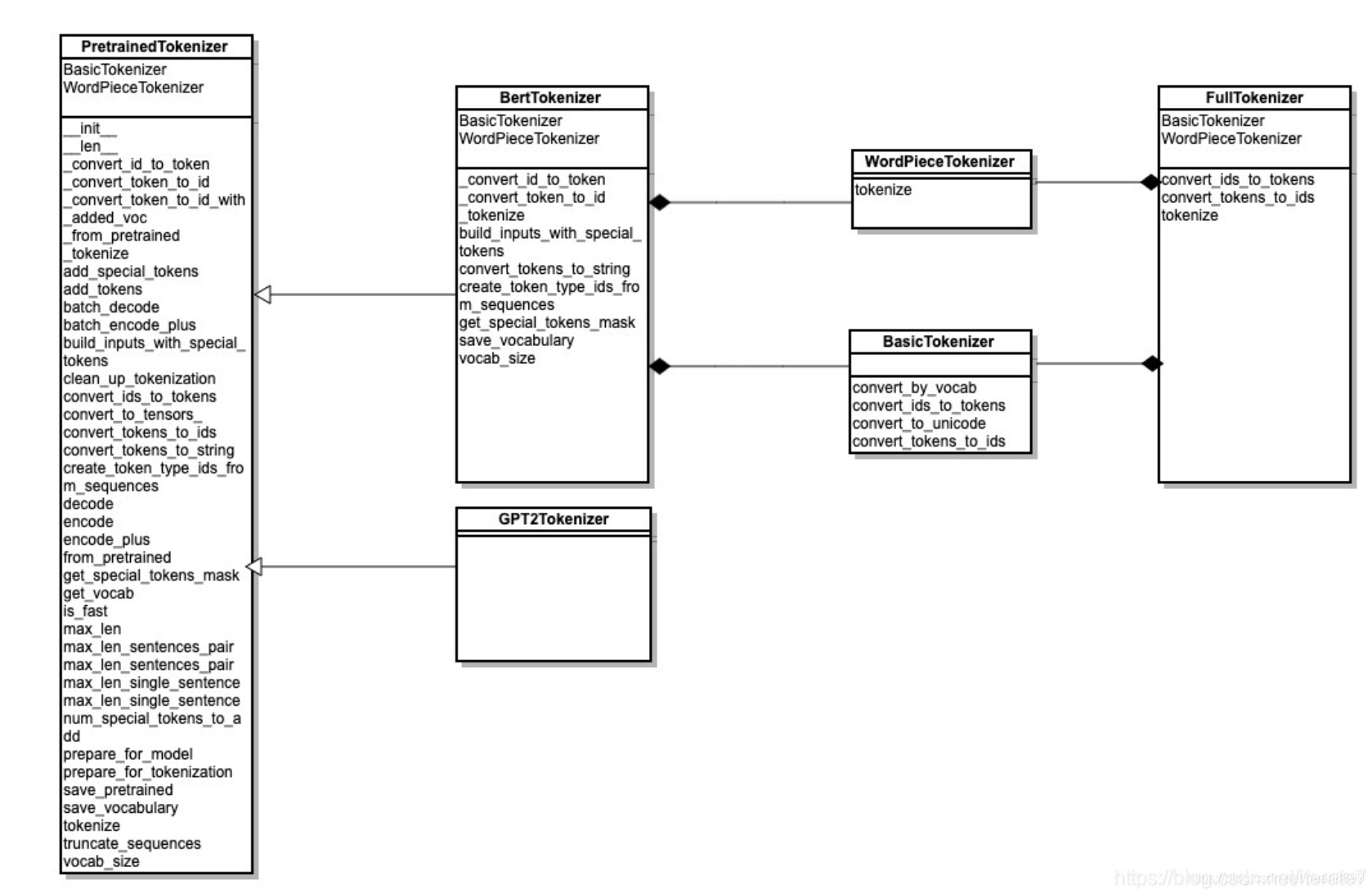
BasicTokenzer
主要的类是BasicTokenizer,做一些基础的大小写、unicode转换、标点符号分割、小写转换、中文字符分割、去除重音符号等操作,最后返回的是关于词的数组(中文是字的数组)
BasicTokenzer是预处理。
wordpiecetokenizer
另外一个则是关键wordpiecetokenizer,就是基于vocab切词。
FullTokenzier
这个基本上就是利用basic和wordpiece来切分。用于bert训练的预处理。基本就一个tokenize方法。不会有encode_plus等方法。
PretrainTokenizer
这个则是bert的base类,定义了很多方法(convert_ids_to_tokens)等。 后续的BertTokenzier,GPT2Tokenizer都继承自pretrainTOkenizer,下面的关系图可以看到这个全貌。
1.3句子简单编码
使用下面的encode方式即可:
from transformers import BertTokenizer
bert_name = 'bert-base-chinese'
tokenizer = BertTokenizer.from_pretrained(bert_name)
text = '愿执子手立黄昏,冬日品茗粥尚温.'
input_ids = tokenizer.encode(
text,
add_special_tokens=True, # 添加special tokens, 也就是CLS和SEP
max_length=100, # 设定最大文本长度
pad_to_max_length=True, # pad到最大的长度
return_tensors='pt' # 返回的类型为pytorch tensor
)
print('---text: ', text)
print('---id', input_ids)
输出:
---text: 愿执子手立黄昏,冬日品茗粥尚温.
---id tensor([[ 101, 2703, 2809, 2094, 2797, 4989, 7942, 3210, 8024, 1100, 3189, 1501,
5751, 5114, 2213, 3946, 119, 102, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0]])
1.4.其他形式编码
from transformers import BertTokenizer
bert_name = 'bert-base-chinese'
tokenizer = BertTokenizer.from_pretrained(bert_name)
# text = '[SEP]愿执子[sep]手立黄昏,[SEP]冬日品茗粥尚温.'
text = '愿执子手立黄昏,[SEP]冬日品茗粥尚温.'
input_ids = tokenizer(text)
print('---text: ', text)
print('---id', input_ids)
print("词典大小:",tokenizer.vocab_size)
text = "the game has gone!unaffable I have a new GPU!"
tokens = tokenizer.tokenize(text)
print("英文分词来一个:",tokens)
text = '愿执子手立黄昏,[SEP]冬日品茗粥尚温.'
tokens = tokenizer.tokenize(text)
print("中文分词来一个:",tokens)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
print("id-token转换:",input_ids)
sen_code = tokenizer.encode_plus("i like you much", "but not him")
print("多句子encode:", sen_code)
print("decode:",tokenizer.decode(sen_code['input_ids']))
输出:
---text: 愿执子手立黄昏,[SEP]冬日品茗粥尚温.
---id {'input_ids': [101, 2703, 2809, 2094, 2797, 4989, 7942, 3210, 8024, 102, 1100, 3189, 1501, 5751, 5114, 2213, 3946, 119, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
词典大小: 21128
英文分词来一个: ['the', 'game', 'has', 'go', '##ne', '!', 'u', '##na', '##ff', '##able', '[UNK]', 'have', 'a', 'new', '[UNK]', '!']
中文分词来一个: ['愿', '执', '子', '手', '立', '黄', '昏', ',', '[SEP]', '冬', '日', '品', '茗', '粥', '尚', '温', '.']
id-token转换: [2703, 2809, 2094, 2797, 4989, 7942, 3210, 8024, 102, 1100, 3189, 1501, 5751, 5114, 2213, 3946, 119]
多句子encode: {'input_ids': [101, 151, 8993, 8357, 11677, 8370, 102, 10288, 9059, 8913, 8175, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
decode: [CLS] i like you much [SEP] but not him [SEP]tokenizer.tokenize() :
使用 tokenize() 函数对文本进行 tokenization(分词)之后,返回的分词的 token 词
tokenizer.encoder():
encode() 函数对 文本 进行 tokenization 并将 token 用相应的 token id 表示
1.5 此处缺一个编码函数
待续ing
2.分隔符编码
特殊的分隔符号:
[MASK] :表示这个词被遮挡。需要带着[],并且mask是大写,对应的编码是103
[SEP]: 表示分隔开两个句子。对应的编码是102
[CLS]:用于分类场景,该位置可表示整句话的语义。对应的编码是101
[UNK]:文本中的元素不在词典中,用该符号表示生僻字。对应编码是100
[PAD]:针对有长度要求的场景,填充文本长度,使得文本长度达到要求。对应编码是0
eg:
from transformers import BertTokenizer
bert_name = 'bert-base-chinese'
tokenizer = BertTokenizer.from_pretrained(bert_name)
text = '[SEP]愿执子[sep]手立黄昏,[MASK]冬日品茗粥尚温.'
input_ids = tokenizer.encode(
text,
add_special_tokens=True, # 添加special tokens, 也就是CLS和SEP
max_length=100, # 设定最大文本长度
pad_to_max_length=True, # pad到最大的长度
return_tensors='pt' # 返回的类型为pytorch tensor
)
print('---text: ', text)
print('---id', input_ids)
输出:
---text: [SEP]愿执子[sep]手立黄昏,[MASK]冬日品茗粥尚温.
---id tensor([[ 101, 102, 2703, 2809, 2094, 138, 9463, 140, 2797, 4989, 7942, 3210,
8024, 103, 1100, 3189, 1501, 5751, 5114, 2213, 3946, 119, 102, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0]])参考:
1.https://huggingface.co/transformers/model_doc/bert.html#bertforsequenceclassification


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









