







由来
Elasticsearch 是一个基于 Apache Lucene 构建的分布式、高扩展、近实时的搜索与数据分析引擎,能够高效处理结构化和非结构化数据的全文检索及复杂分析
搜索,即用户在平台如百度进行输入关键词,由后端给出搜索结果数据进行返回,那为啥不可以使用mysql呢
mysql的缺点
比如商品标题模糊搜索,由于mysql的innodb的索引有着最左匹配原则,会造成索引失效,而造成全表扫描
如日志关键字实时检索,当业务系统达到了TB级别,数据量级别相当大,无法高效处理数据
如用户行为聚合分析,在使用mysql的情况下,需要进行多表关联查询,性能很低
ElasticSearch优点
在商品标题模糊搜索中,ElasticSearch的倒排索引支持分词、近义词扩展
日志关键字实时检索中,ElasticSearch的分布式架构支持水平扩展,近实时检索
用户行为聚合分析中,ElasticSearch原生聚合 API 支持多维统计
下载与启动
下载
elasticSearch 下载
Download Elasticsearch | Elastic
kibana下载
Download Kibana Free | Get Started Now | Elastic
启动
ElasticSearch启动
在ElasticSearch目录下输入bin/elasticsearch 看到如下的页面即启动成功
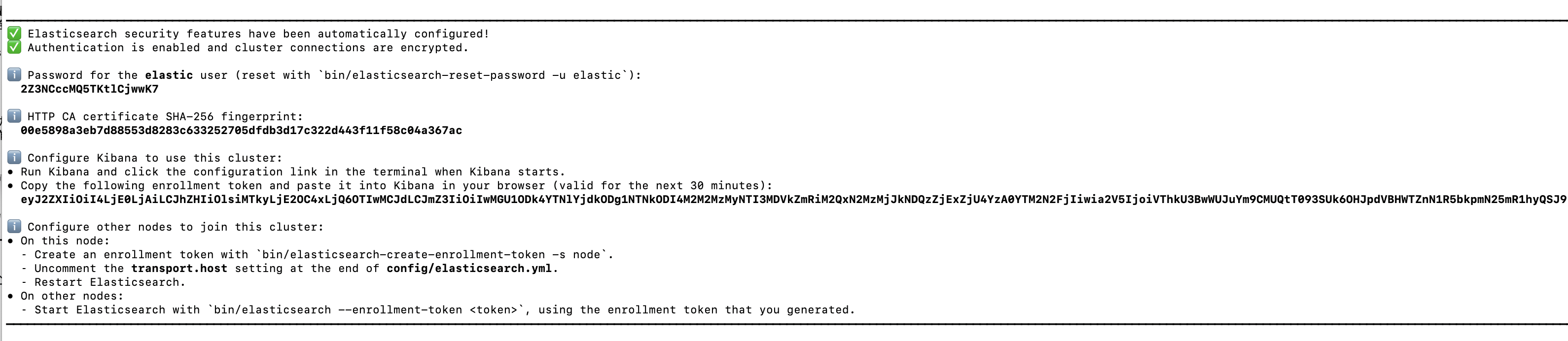
kibana启动
在Kibana目录下输入bin/kibana,看到如下页面即启动成功
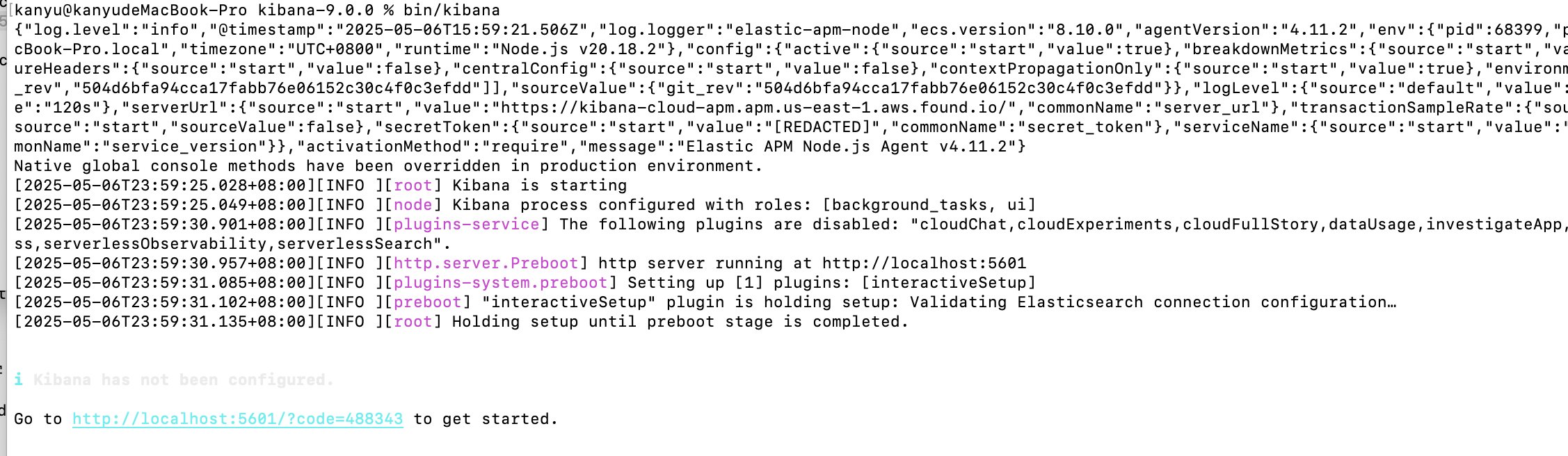
进入http://localhost:5601/?code=655275
输入token,token为启动elasticsearch的页面中有一段粗体token

复制这段token粘贴到登录页面
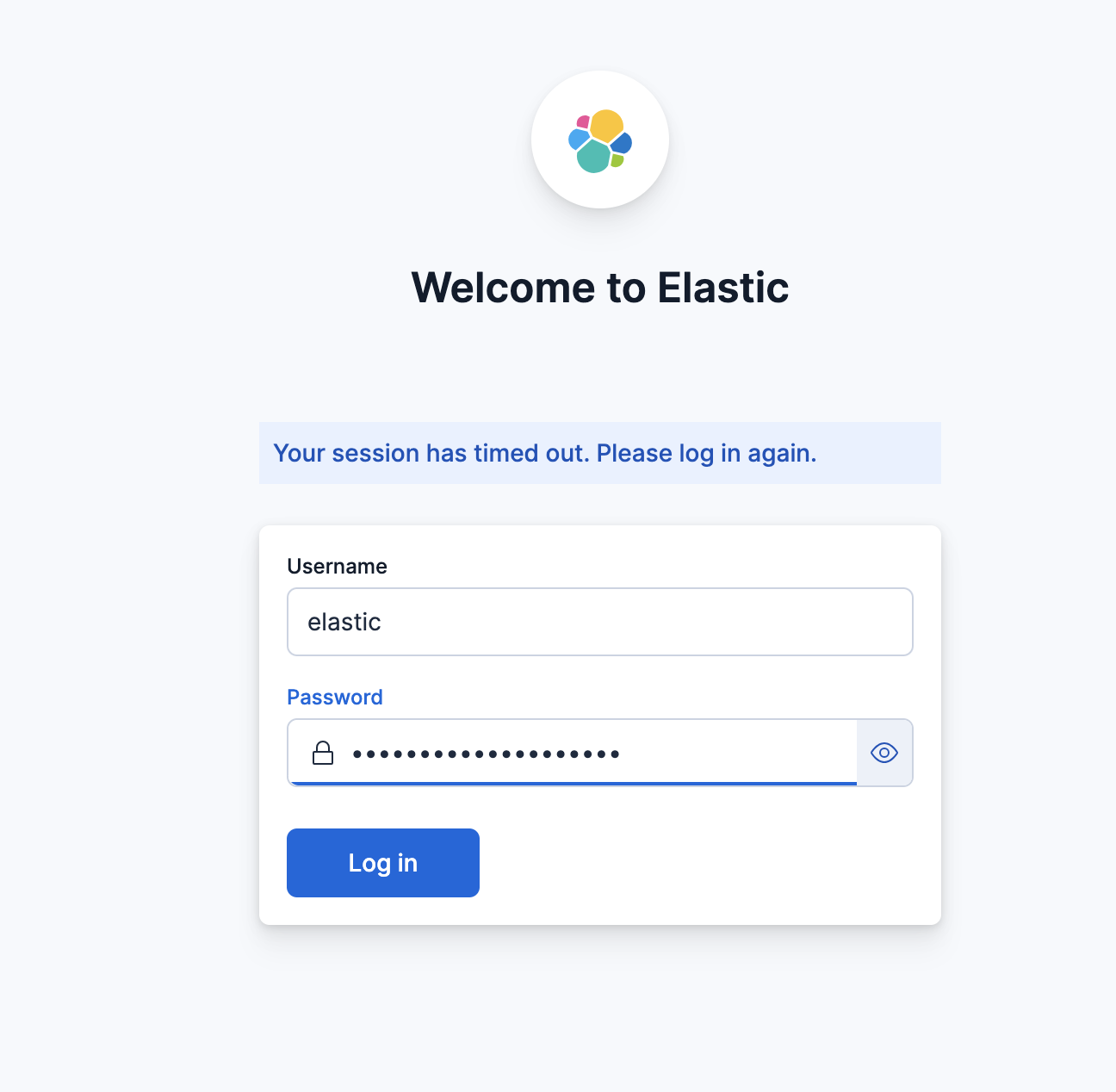
之后会进入登录输入框
username填入elastic
passward填入启动ElasticSearch看到的passward

点击login 则会直接ElasticSearch 网页
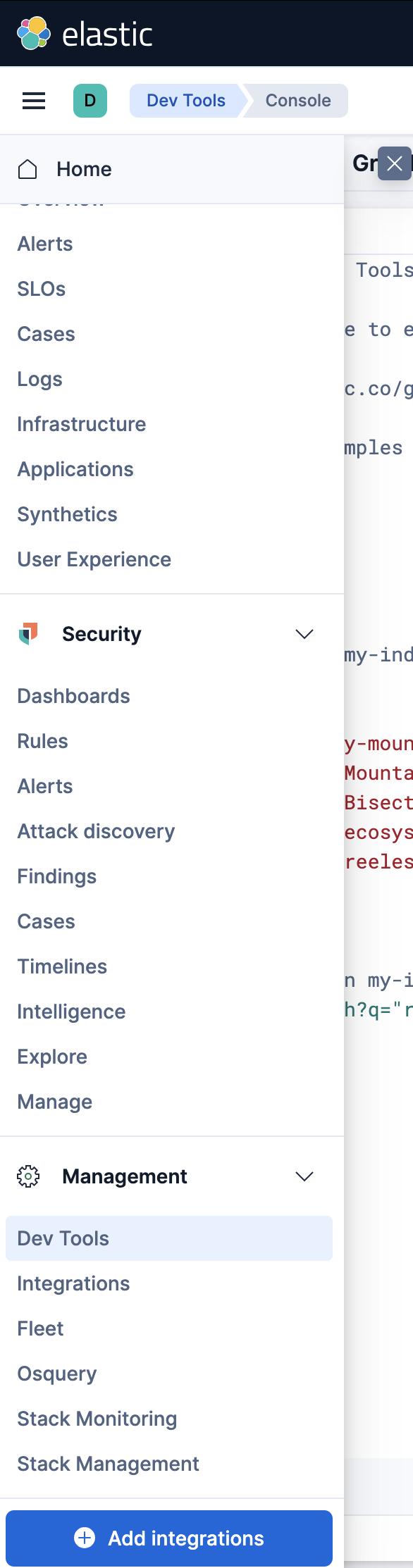
点击dev tools,进入操作网页与ElasticSearch进行交互
入门
基本概念
index索引
注意这里的索引和mysql的索引有所区别,mysql的索引类似于目录,帮助快速查询数据用的
es的索引指的是存储相关数据的数据结构,可以类比成mysql的数据表,es索引会存储不同的数据结构key和value的关系
其中索引还包括映射,用于定义索引中每个字段的数据类型和其他属性,相当于mysql中在新建表的过程中定义各个字段
ducoment文档
文档是存储数据的基本单元,每个文档都是一个JSON对象,包含多个字段(Field),字段可以是各种数据类型,如文本、数字、日期等。每个文档都有一个唯一的ID,用于标识和定位文档
比如
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_version": 1,
"_score": 1.0,
"_source": {
"title": "Elasticsearch Guide",
"author": "John Doe",
"published_date": "2023-10-01",
"content": "Elasticsearch is a distributed, RESTful search and analytics engine."
}
}
_index表示文档所属的索引名称,_type表示文档的类型(在Elasticsearch 7.x及以后版本中,默认为_doc),_id是文档的唯一标识符,_source包含实际的文档内容
type类型
在Elasticsearch中表示一类相似的文档。类型由名称(如user或blogpost)和映射组成。映射描述了文档可能具有的字段或属性、每个字段的数据类型(如string、integer或date)以及Lucene如何索引和存储这些字段。类型可以很好地抽象划分相似但不相同的数据。然而,由于Lucene的处理方式,类型的使用有一些限制。在Elasticsearch 7.x及以后的版本中,默认类型为_doc,这意味着不再需要显式定义类型
cluster集群
Elasticsearch集群是由一个或多个节点组成的集合,这些节点共同存储整个数据。集群有一个唯一的名称(默认为"elasticsearch"),同一集群中的所有节点共享这个名称
集群包含了多个节点(Node)和一个或多个索引(Index)
node节点
节点是Elasticsearch集群中的一个服务器,存储数据并参与集群的索引和搜索操作。每个节点都有一个唯一的名称,并且在集群初始化时自动加入集群
shard分片
分片是存储Elasticsearch数据的基本物理单元。Elasticsearch将索引中的数据分割成多个分片,这些分片可以分布在集群的不同节点上。这样做的好处是提高了数据的并行处理能力,同时也提高了数据的可扩展性和可靠性
replica副本
副本是分片的复制,用于提高数据的可用性和冗余备份。每个索引可以有多个副本,当一个或多个节点发生故障时,副本可以用来恢复数据,保证数据的高可用性。副本的存在使得查询操作可以从任何副本读取数据,从而提高查询的吞吐量和响应速度
简单交互
请求体
ElasticSearch可以像请求http接口一样请求,使用RESTful API 通过端口 9200 和 Elasticsearch 进行通信
请求方法或谓词:GET、 POST、 PUT、 HEAD 或者 DELETE,语义和http相同
协议:支持http和https
主机名:本地部署启动的为localhost或者127.0.0.1
端口:运行 Elasticsearch HTTP 服务的端口号,默认是 9200
API 路径:相当于http路径
查询参数QUERY_STRING:?后边的参数
BODY请求体:JSON格式的请求体
举例
查询文档数量
GET /_count?pretty
{
"query": {
"match_all": {}
}
}返回
{
"count": 0,
"_shards": {
"total": 13,
"successful": 13,
"skipped": 0,
"failed": 0
}
}ElasticSearch会返回JSON格式的数据
文档
在之前的学习Java go mysql中,数据结构通常为对象或者简单的键值对
而ElasticSearch是面向文档的中间件
文档是 Elasticsearch 中的基本数据实体,以 JSON 格式 封装数据。每个文档包含:
- 数据字段:用户自定义的键值对(如
{"name":"张三","age":25})。 - 元数据:系统自动生成的标识信息(如
_id,_index,_version等)。
{
"_index": "user",
"_id": "1",
"_source": {
"name": "张三",
"age": 30,
"address": "北京"
}
}
举例实践
存储员工文档
这里以elasticsearch官方权威指南的举例进行实操

接下来进行实操下
1,新建员工文档
PUT /megacorp/employee/1
{
"first_name" : "张",
"last_name" : "三",
"age" : 30,
"about" : "I love to go rock climbing",
"interests": [ "运动", "音乐" ]
}报错

注意权威指南的语法适用于7.0之前的版本,之后的版本去掉了type的概念
修正为PUT /employee/_doc/1
PUT /employee/_doc/1
{
"first_name" : "张",
"last_name" : "三",
"age" : 30,
"about" : "I love to go rock climbing",
"interests": [ "运动", "音乐" ]
}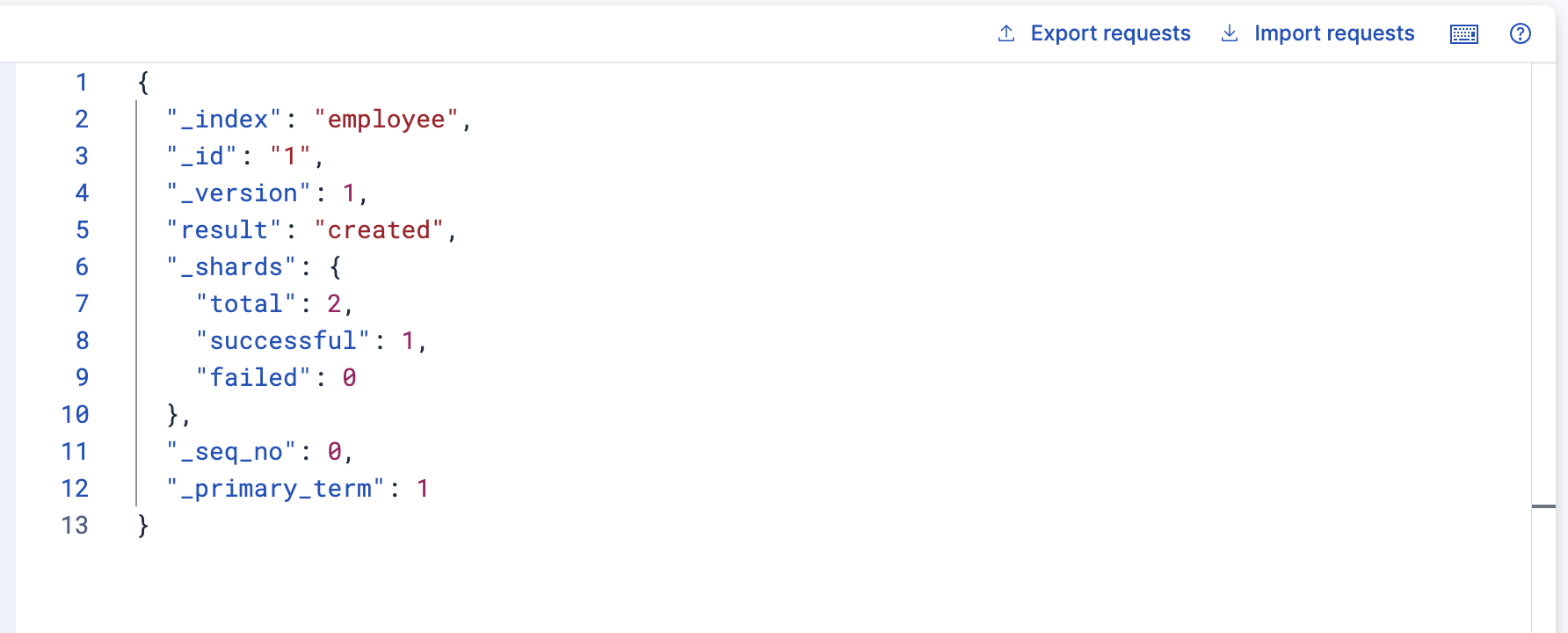
可以看到文档新建成功
2,检索员工文档
GET /employee/_doc/1
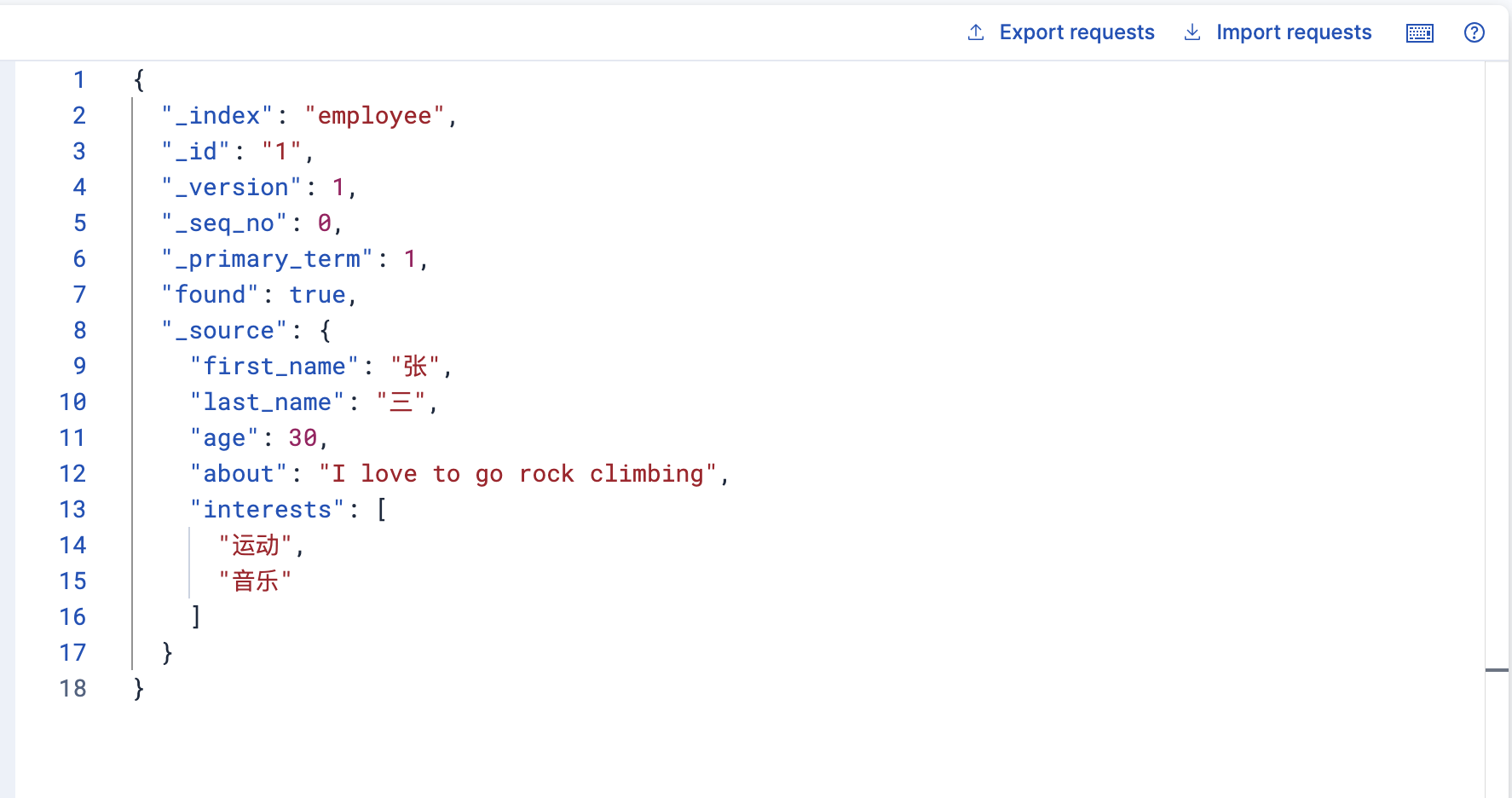
3,轻量搜索
查询所有雇员
GET /employee/_search
返回
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "employee",
"_id": "1",
"_score": 1,
"_source": {
"first_name": "张",
"last_name": "三",
"age": 30,
"about": "I love to go rock climbing",
"interests": [
"运动",
"音乐"
]
}
},
{
"_index": "employee",
"_id": "2",
"_score": 1,
"_source": {
"first_name": "王",
"last_name": "五",
"age": 33,
"about": "I love to go rock climbing",
"interests": [
"运动"
]
}
},
{
"_index": "employee",
"_id": "3",
"_score": 1,
"_source": {
"first_name": "赵",
"last_name": "六",
"age": 33,
"about": "I like to build cabinets",
"interests": [
"林业"
]
}
}
]
}
}返回的数据包括了所有文档
高亮搜索
GET /employee/_search?q=last_name:六
这里使用路径查询参数来查询last_name=六的雇员信息
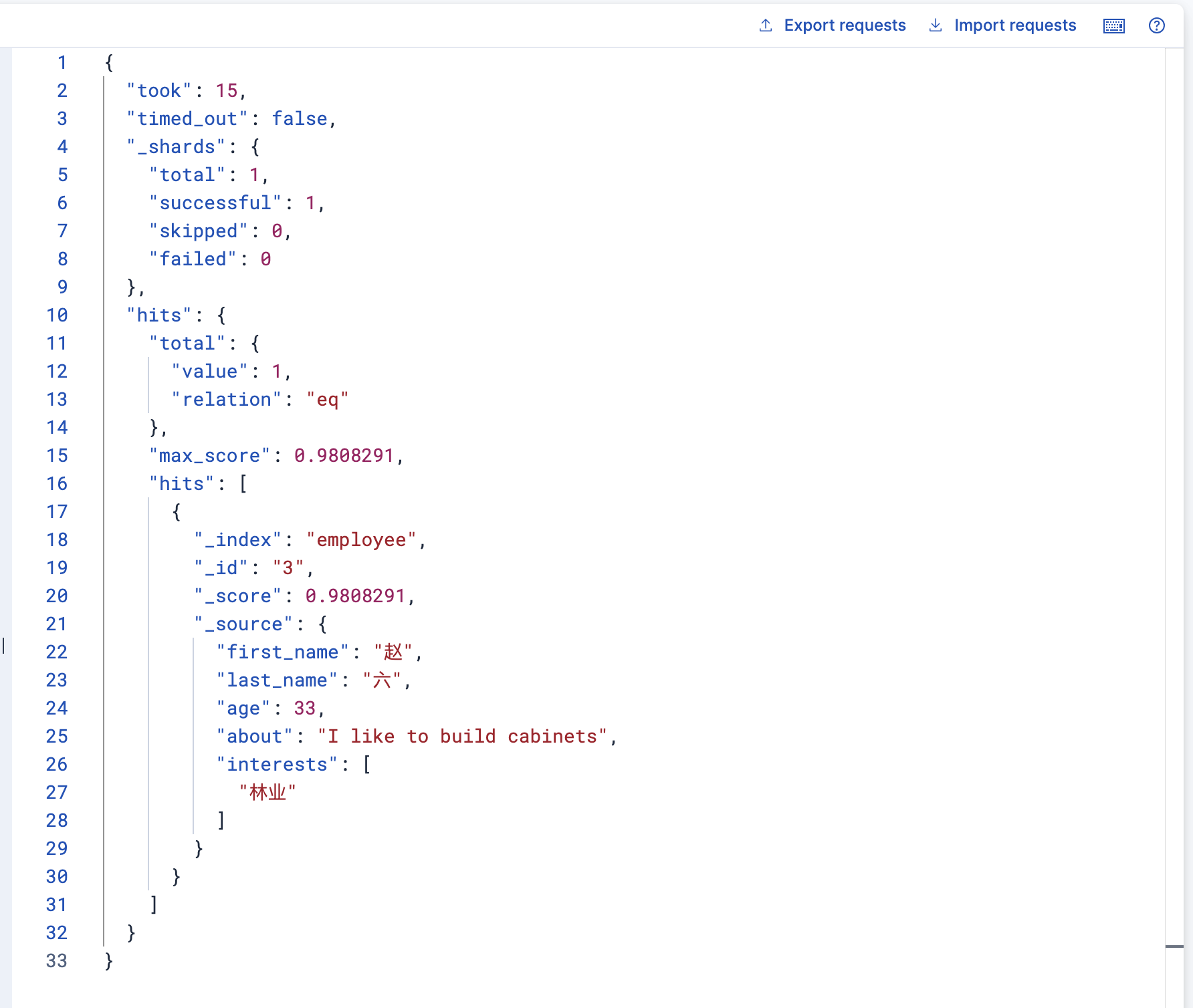
4,查询表达式搜索
使用DSL语句进行查询
GET /employee/_search
{
"query" : {
"match" : {
"last_name" : "三"
}
}
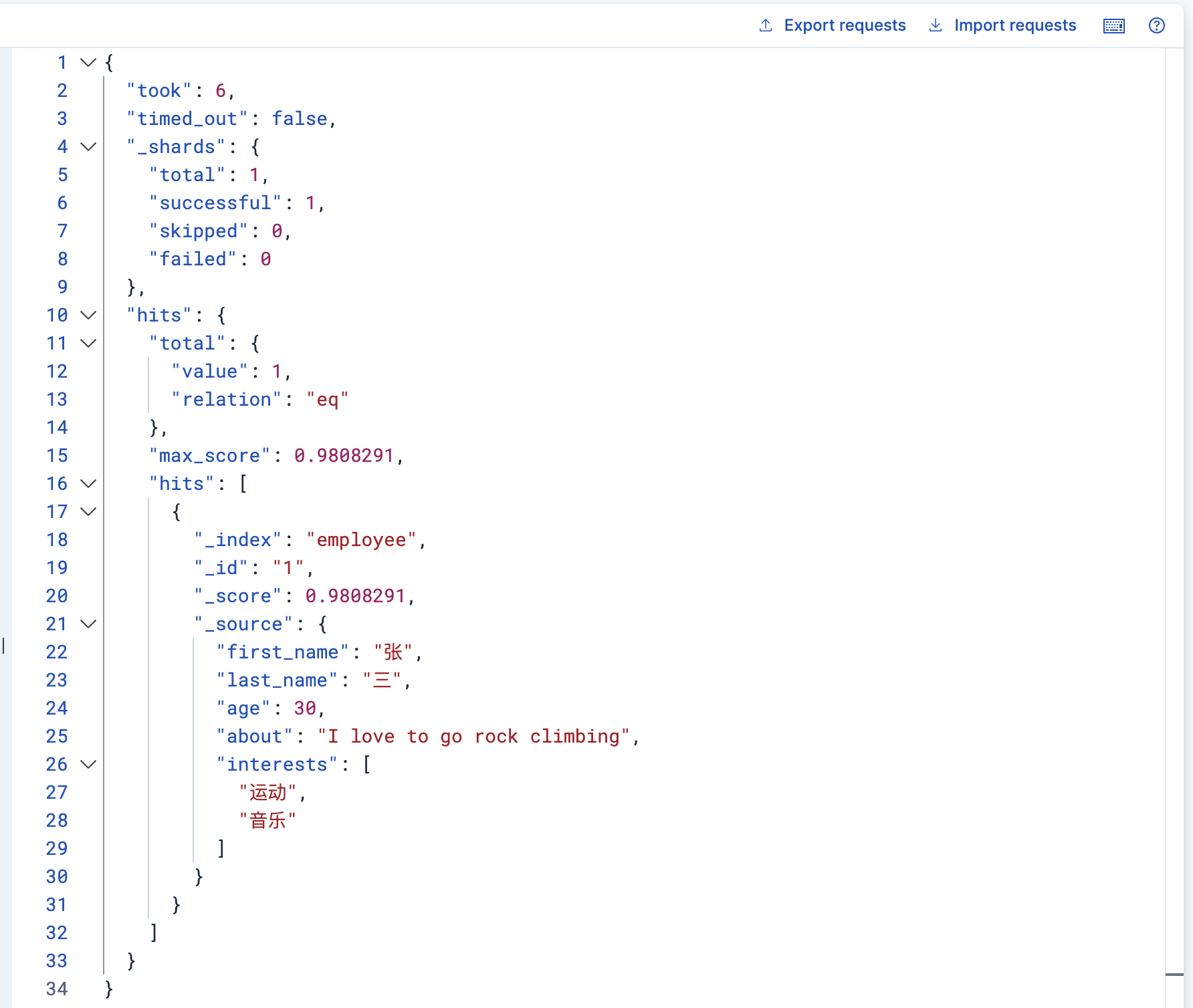
}即查询文档中last_name=三的雇员信息
返回
5,更复杂的搜索
查询last_name=六 而且age>30的,可以类比成mysql的where last_name=六 and age>30
GET /employee/_search
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "六"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}在es中用了filter过滤器来实现多维度查询语句
6,全文搜索
接下来操作下查询所有喜欢rock climbing的雇员
类比成使用传统的mysql数据库,使用模糊搜索 where about like %rock climbing
GET /employee/_search
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}返回
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.4167401,
"hits": [
{
"_index": "employee",
"_id": "1",
"_score": 1.4167401,
"_source": {
"first_name": "张",
"last_name": "三",
"age": 30,
"about": "I love to go rock climbing",
"interests": [
"运动",
"音乐"
]
}
},
{
"_index": "employee",
"_id": "2",
"_score": 0.4589591,
"_source": {
"first_name": "王",
"last_name": "五",
"age": 33,
"about": "I like to collect rock albums",
"interests": [
"运动"
]
}
}
]
}
}可以看到返回了两个文档,返回的相关性得分高的在前边,但员工2同样返回了,由于员工2的about包括了rock 与查询的rock climbing有点关联但关联比不上员工1
这里同样表示了和mysql数据库的区别
mysql:select * from employee where about like %rock climbing
这里只会返回about完全匹配rock climbing的记录
而es会根据相关读来返回和查询有关联的所有记录,和咱平常查询百度相同,不会完全匹配,但会有返回很多和输入有关联的检索记录
7,短语搜索
这里的搜索关键词match_phrase即完全匹配
GET /employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}返回
{
"took": 279,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.4167401,
"hits": [
{
"_index": "employee",
"_id": "1",
"_score": 1.4167401,
"_source": {
"first_name": "张",
"last_name": "三",
"age": 30,
"about": "I love to go rock climbing",
"interests": [
"运动",
"音乐"
]
}
}
]
}
}可以看到这里只会返回员工1,这是由于只有员工1的about完全匹配了“rock climbing”
8,高亮搜索
在日常的百度使用中,搜索"elasticsearch"
可以看到elasticsearch全部都高亮了
与之前的搜索语句对比,多了hightlight高亮语句片段
GET /employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}返回
{
"took": 736,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.4167401,
"hits": [
{
"_index": "employee",
"_id": "1",
"_score": 1.4167401,
"_source": {
"first_name": "张",
"last_name": "三",
"age": 30,
"about": "I love to go rock climbing",
"interests": [
"运动",
"音乐"
]
},
"highlight": {
"about": [
"I love to go <em>rock climbing</em>"
]
}
}
]
}
}可以看到返回的数据中多了个highlight切返回的about增加了<em>标签
9,分析与聚合
挖掘出员工中最受欢迎的兴趣
注意使用ElasticSearch5版本之前会报错
es5请求:
GET /megacorp/employee/_search
{
"aggs": {
"all_interests": {
"terms": { "field": "interests" }
}
}
}
报错

Fielddata可以消耗大量的堆空间,特别是在加载高基数文本字段时。一旦fielddata已经加载到堆中,它在该段的生存期内保持。此外,加载fielddata是一个昂贵的过程,可以导致用户体验延迟命中,在[员工]的[兴趣]上禁用了字段数据。文本字段没有针对需要每个文档字段数据(如聚合和排序)的操作进行优化,因此默认情况下这些操作被禁用。请改用关键字字段。或者,在[interests]上设置fielddata=true,以便通过取消倒排索引来加载字段数据。请注意,这可能会占用大量内存
所以fielddata默认禁用。如果尝试对文本字段上的脚本进行排序,聚合或访问值,就会看到这个异常
由于fielddata会消耗大量内存所以这里采用keyword关键字
es9版本:
GET /employee/_search
{
"aggs": {
"all_interests": {
"terms": { "field": "interests.keyword" }
}
}
}返回
{
"took": 57,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "employee",
"_id": "1",
"_score": 1,
"_source": {
"first_name": "张",
"last_name": "三",
"age": 30,
"about": "I love to go rock climbing",
"interests": [
"运动",
"音乐"
]
}
},
{
"_index": "employee",
"_id": "3",
"_score": 1,
"_source": {
"first_name": "赵",
"last_name": "六",
"age": 33,
"about": "I like to build cabinets",
"interests": [
"林业"
]
}
},
{
"_index": "employee",
"_id": "2",
"_score": 1,
"_source": {
"first_name": "王",
"last_name": "五",
"age": 33,
"about": "I like to collect rock albums",
"interests": [
"运动"
]
}
}
]
},
"aggregations": {
"all_interests": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "运动",
"doc_count": 2
},
{
"key": "林业",
"doc_count": 1
},
{
"key": "音乐",
"doc_count": 1
}
]
}
}
}这里利用了Elasticsearch聚合(aggregations)功能
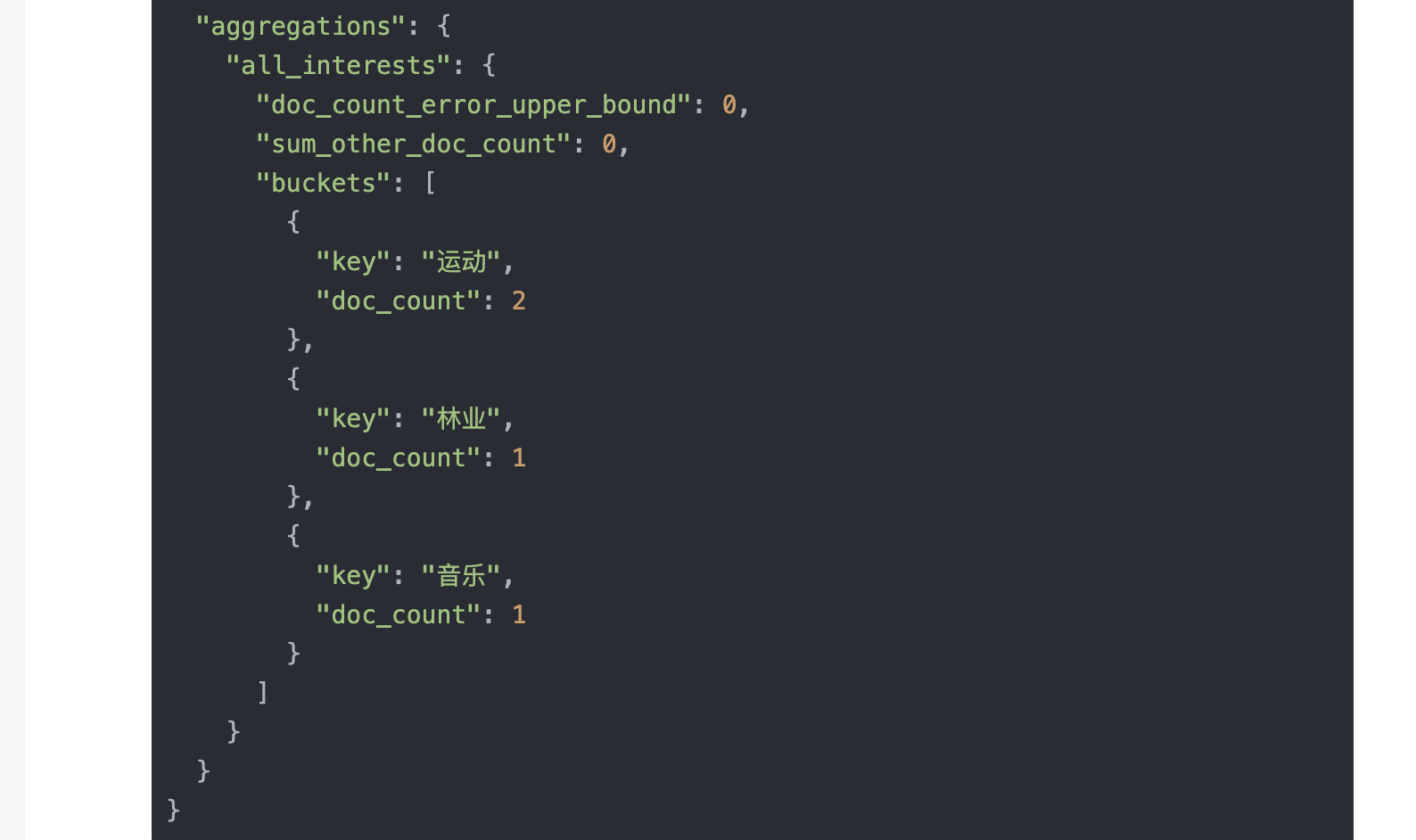
从返回中可以看出有2人对运动感兴趣,1人对林业感兴趣,1人对音乐感兴趣
组合查询
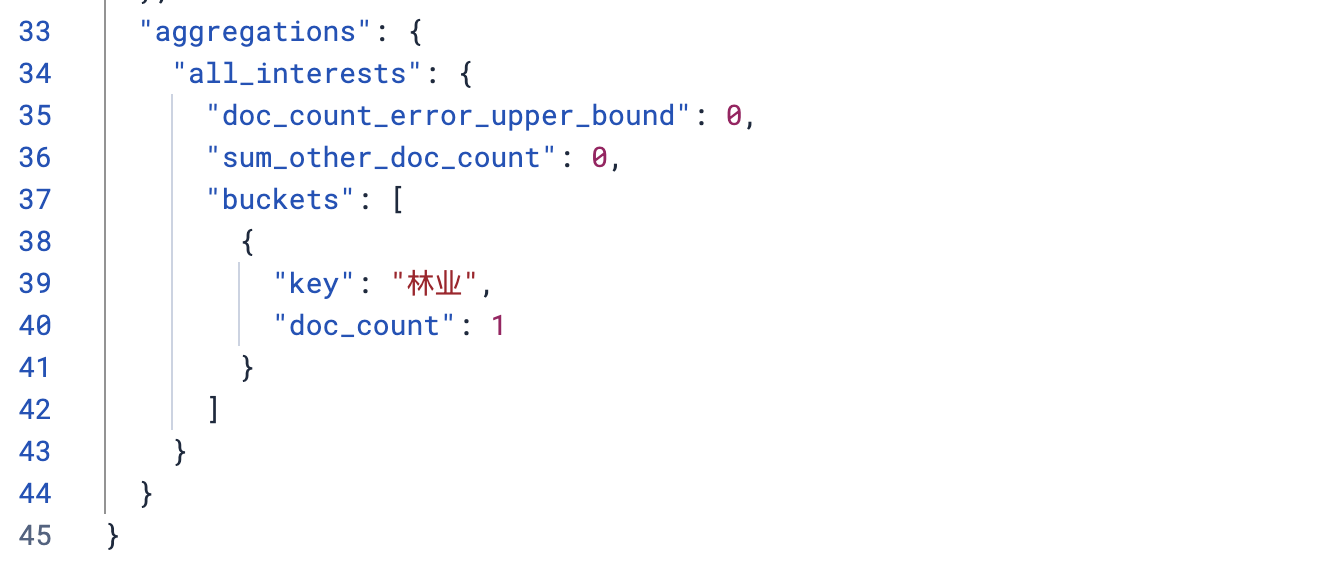
分析员工last_name=“六”中最受欢迎的兴趣
GET /employee/_search
{
"query": {
"match": {
"last_name": "六"
}
},
"aggs": {
"all_interests": {
"terms": {
"field": "interests.keyword"
}
}
}
}返回
分级聚会汇总
GET /employee/_search
{
"aggs" : {
"all_interests" : {
"terms" : { "field" : "interests.keyword" },
"aggs" : {
"avg_age" : {
"avg" : { "field" : "age" }
}
}
}
}
}这个请求指的是查询最受欢迎的兴趣以及各个兴趣中的员工的平均年龄是多少
返回

参考
李文周ElasticSearch


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









