









1 yarn web ui:
-
Apps Submitted:已提交的应用
-
Apps Completed:已完成的应用
-
Apps Running:正在运行的应用
-
Containers Running:正在运行的容器
-
Memory Total:集群总内存
-
Memory Used:已使用内存
-
VCores Total:集群 CPU 总核数
-
VCores Used:已使用的 CPU 核数
-
Memory Reserved:预留的内存
-
VCores Reserved:预留的 CPU 核数
参考:辛辛苦苦运行起来的Yarn页面,里面的参数你得了解一下_a934079371的博客-CSDN博客
2 Memory Reserved:预留的内存
VCores Reserved:预留的 CPU 核数
Yarn 为了防止在分配一个容器到 NodeManager 的时候, NodeManager当前还不能满足,那么 现在 NodeManager 已经有的资源将被冻结即reserved,直到达到 容器需要的标准,然后分给那个容器。
An implementation detail of this change that prevents applications from starving under this new flexibility is the notion of reserved containers. Imagine two jobs are running that each have enough tasks to saturate more than the entire cluster. One job wants each of its mappers to get 1GB, and another job wants its mappers to get 2GB. Suppose the first job starts and fills up the entire cluster. Whenever one of its task finishes, it will leave open a 1GB slot. Even though the second job deserves the space, a naive policy will give it to the first one because it’s the only job with tasks that fit. This could cause the second job to be starved indefinitely. To prevent this unfortunate situation, when space on a node is offered to an application, if the application cannot immediately use it, it reserves it, and no other application can be allocated a container on that node until the reservation is fulfilled. Each node may have only one reserved container. The total reserved memory amount is reported in the ResourceManager UI. A high number means that it may take longer for new jobs to get space.
大意如下: 同时2个JOB在运行,且每个JOB都能完全占满了当前集群资源, 假如第一个JOB每个任务需要1G资源,第二个JOB每个任务需要2G的资源。 如果第一个JOB的某个任务运行完成了,会有1个G的资源属于开放可用状态, 那么这个1个G的资源也会只有第一个JOB可用, 第二个JOB肯定用不到。因为第二个JOB需要至少2G内存,那么这1个G的资源肯定不够,但是对第一个JOB的子任务正好。导致第二个JOB的任务总是无法分配到资源。
为解决这种问题, 出现了reserved资源的做法, 即1G的资源即使不能立即为第二个JOB使用, 也会先占用即reserved, 直到对应节点可分配到更多资源达到2个G,此时reserved状态即解除。
思考: 如上述情况,每个节点应该仅仅有且有一个reserved状态容器。 【但是针对更多JOB的情况,可能会更多,即多个JOB都需要2G的内存单元运行的情况下,是否有可能出现多个reserved状态资源呢?】
3 yarn log.
正在运行的日志保存路径(可配置本地保存路径),运行完成后会移除,聚合到HDFS路径,参看3.3.

3.1 spark AM container日志。
在yarn web ui, 可以看到Logs

点击logs链接。会进入AM容器日志列表页面。结尾编号为000001

可以看到有4个日志文件。 prelaunch.err, prelauch.out, stderr,stdout.
prelaunch.err, prelauch.out为启动AM前的一些日志,基本不用关注。
stderr, 为容器启动即AM注册时一些日志信息。 以及JOB运行时,请求资源executor相关容器的一些框架相关信息。也包含启动过程中一些异常信息。
stdout, AM相关容器程序的输出信息。一般为空。
3.2 spark executor container日志
spark executor container 在UI第一列链接后,可以看到所有容器日志链接:

如上图, 除了编号000001外,都是executor容器,点击链接logs:

prelaunch.err, prelauch.out为启动executor容器之前的一些日志,基本不用关注。
stderr, 为容器启动executor容器,以及注册时一些日志信息。 以及JOB运行时,分配任务以及运行情况的一些日志。也包含启动过程中一些异常信息。
stdout, 运行的任务输出信息。如system.out.println 或者log.info打印的一些信息。
3.3 spark event log
spark event log记录了spark job所有的事件信息,WEB ui查看历史和当前的数据都可以在此路径找到。
spark.eventLog.dir = hdfs://emr-cluster/spark-history
运行完成的app可以在这个目录下找到,例如 hdfs://emr-cluster/spark-history/application_1675767210052_**** (有可能有后缀_1)
整下运行的spark, 会有后缀 .inprogress
3.3 spark history log.
运行完成后,日志文件都会聚合到HDFS指定路径:

如下截图:为applicationID 的聚合日志,可以看到是按节点聚合保存。(1个AM,6个executor) :

通过命令行yarn logs -applicationId appid可以查看所有容器的聚合日志(上述7个文件的合并)。
也可以通过yarn web ui查看单个容器的历史日志文件:
3.2.1 am 日志: 直接找到历史job,点击logs, 即可链接进入到 AM的容器日志。 注意历史日志已经聚合prelaunch.err, prelauch.out,stderr,stdout到一个文件中。
AM日志
sterr除注册申请分配信息,
stout 也包含main程序输出打印信息。 (drirver 后面的日志可点击)
注:有时可以看到2个logs, 说明启动过2次am, 以第二个重新构建的AM为准。
3.2.2 executor日志。需要从AM的track url 链接, 进入spark history web ui.

每个executor的日志有独特标志(executorId@hostname): 如: 28367@sz-hd-13
实际展现是根据聚合的日志文件,截取executorId对应的日志内容显示。
3.3 flink log
flink同spark类似,只是AM运行的是jobmanager. 任务运行在taskmanager,
任务日志文件主要看taskmanager.log和taskmanager.out。
taskmanager.log打印一些系统框架输出日志(如checkpoint信息)和业务日志信息即业务代码中log代码信息(默认情况)。
我们可以修改默认配置: 将业务日志信息写到特定文件。调整log4j.properties可以指定。但是这样就再WEB页面看不到了。
taskmanager.out 打印所有的System.out.print日志。
一般情况下很少使用,所以这个文件其实很小。
参考: https://support.huaweicloud.com/devg3-mrs/mrs_07_260053.html
http://www.cnblogs.com/createweb/p/11613511.html
注: flink默认使用log4j作为日志输出。要使用logback: 可以删除log4j.propertis并添加logback.xml配置文件(flink/conf目录), 同时需要添加依赖jar包到flink/lib
 参考:hadoop - What is Memory reserved on Yarn - Stack Overflow
参考:hadoop - What is Memory reserved on Yarn - Stack Overflow
3.1 job, stage ,task概念
//todo
前言: 看懂UI前先要弄清楚 job, stage ,task概念。 可参考:理解spark中的job、stage、task - 知乎
1 当在程序中遇到一个action算子的时候,就会提交一个job
2 job中stage的划分就是根据shuffle依赖进行的. 如果宽依赖(即父rdd 对应多个子rdd)会产生shuffle,即拆分为一个stage.
3 一个spark application提交后,陆续被分解为job、stage,到这里其实还是一个比较粗的概念。Stage继续往下分解,就是Task。
Task的数量其实就是stage的并行度。RDD在计算的时候,每个分区都会起一个task,所以rdd的分区数目决定了总的的task数目。
3.2 spark webui 内存相关的重要参数
3.2.1 Storage Memory
此参数 显示RDD占用存储数据区的内存/存储区域内存(一般RDD数据缓存在此)大小。 spark新版本中运行时内存不够时是可以使用数据存储区内存的。我们对rdd进行cache操作可以查看存储使用的内存大小。
如果发现执行器正在使用Storage下的大量内存(分子代表使用的内存),则有可能需要增加执行器的内存大小。
(如何判断 执行器使用了大量存储内存呢?参看3.2.2)
分母:数据存储总共可用内存。spark2中, execution memory和storage memory是共用的,默认是各占用0.5, 但是两者可以互相占用。
所以这里spark UI显示的存储区域内存,为存储和执行总内存之和 = (executor内存 - 300M)*0.6
分子: 显示了存储实际占用的内存。
注意: 虽然我们设置了 --executor-memory 18g,但是 Spark 的 Executor 端通过 Runtime.getRuntime.maxMemory 拿到的内存其实没这么大,只有 17179869184 字节
,另外sparkUI, 计算时除以的是 1000, 不是1024,所以与我们实际计算会有些许出入。
Storgae 和 Execution 在适当时候可以借用彼此的 Memory,需要注意的是,当 Execution 空间不足而且 Storage 空间也不足的情况下,Storage 空间如果曾经使用了超过 Unified 默认的 50% 空间的话则超过部份会被强制 drop 掉一部份数据来解决 Execution 空间不足的问题 (注意:drop 后数据会不会丢失主要是看你在程序设置的 storage_level 来决定你是 Drop 到那里,可能 Drop 到磁盘上,如果只能内存,则报错),这是因为执行(Execution) 比缓存 (Storage) 是更重要的事情。
- 双方空间都不足时,则存储到硬盘;如己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的 Block)。
- 执行内存的空间被对方占用后,可让对方将占用的部分存储转存到硬盘,然后“归还”借用的空间。
- 存储内存的空间被对方占用后,无法让对方“归还”,因为需要考虑到 Shuffle 过程中很多因素,实现起来较为复杂。
在storage中,查看rdd size on disk ,如果有存储到磁盘,说明 storage memory是不足的(如下截图)

3.2.2 shuffle writer
发生在shuffle之前
shuffle wrirer反应了 executor数据在shuffle操作前,如果executor内存不够,会把shuffle的数据溢写到磁盘。
shuffle写伴随着rdd计算结果,一般先写内存buffer,默认好像是32K, 超过阈值,会写入磁盘。为什么写入磁盘,一个是不同任务计算完后,将结果写磁盘,资源让给其它任务,在shuffle时不用去等待。
存在shuffle写是正常的,shuffle前所有数据基本都是存储磁盘(内存32K缓存区没多少,可以忽略),并不能说明executor内存不够。 如果shuffle写太大,说明分区太少,导致单个task溢写磁盘太大。
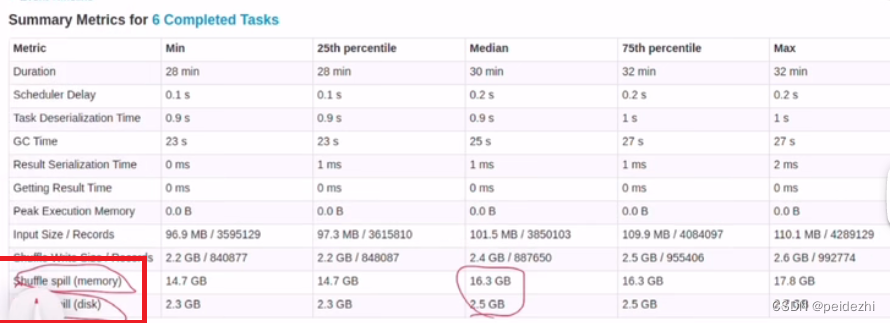
也可以从stage 菜单下,查看单独的task任务,
如下图: shuffle spill 溢写(达到内存buffer的阈值)。
·
3.2.3 shuffle reader
发生在shuffle后, 下游RDD读取上游RDD的数据。 这个反应了shuffle数据输入大小。 一般不用太关心。














 2300
2300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









