






SQL161——近一个月发布的视频中热度最高的top3视频
重要理解:近一个月!!! 整个就diff最难算
select t.video_id,round((100 * comp_play_rate
+ 5 * like_cnt
+ 3 * comment_cnt
+ 2 * retweet_cnt)/(diff+1),0) hot_index
from
(select a.video_id,
sum(if(timestampdiff(second,start_time,end_time)>= b.duration,1,0))/count(a.video_id) comp_play_rate,
sum(if_like) like_cnt,
sum(if(comment_id is not null,1,0)) comment_cnt,
sum(if_retweet) retweet_cnt,
if(count(a.video_id)=0,datediff(date((select max(end_time) from tb_user_video_log)),date(b.release_time)),
datediff(date((select max(end_time) from tb_user_video_log)),max(date(a.end_time)))) diff
from tb_user_video_log a
join tb_video_info b on a.video_id = b.video_id
where datediff(date((select max(end_time) from tb_user_video_log)),date(b.release_time)) <=29
group by a.video_id)t
order by hot_index desc limit 3
#diff 如果video_id等于0,则最近无播放天数为最近日期减去发布日期
#如果不等于0,则最近无播放天数为最近日期减去每类video_id最新播放日期
datediff函数
DATEDIFF函数用于返回两个日期的天数
语法格式
DATEDIFF(date1,date2)
参数说明
date1: 比较日期1
date2: 比较日期2
DATEDIFF函数返回date1 - date2的计算结果,date1和date2两个参数需是有效的日期或日期时间值;如果参数传递的是日期时间值,DATEDIFF函数仅将日期部分用于计算,并忽略时间部分(只有值的日期部分参与计算)
TIMESTAMPDIFF函数:
TIMESTAMPDIFF(unit,begin,end)
TIMESTAMPDIFF函数返回begin-end的结果,其中begin和end是DATE或DATETIME表达式。
TIMESTAMPDIFF函数允许其参数具有混合类型,例如,begin是DATE值,end可以是DATETIME值。 如果使用DATE值,则TIMESTAMPDIFF函数将其视为时间部分为“00:00:00”的DATETIME值。
unit参数是确定(end-begin)的结果的单位,表示为整数。 以下是有效单位:
MICROSECOND 微秒
SECOND 秒
MINUTE 分钟
HOUR 小时
DAY 天
WEEK 周
MONTH 月份
QUARTER
YEAR 年份
162——2021年11月每天的人均浏览文章时长
问题:统计2021年11月每天的人均浏览文章时长(秒数),结果保留1位小数,并按时长由短到长排序。
select date_format(in_time,'%Y-%m-%d') dt,round(sum(timestampdiff(second,in_time,out_time))/count(distinct uid),1) avg_viiew_len_sec
from tb_user_log
where artical_id != 0 and date_format(in_time,'%Y-%m') = '2021-11'
group by dt
order by avg_viiew_len_sec
date(in_time) 返回的也是年-月-日格式的日期函数
163——每篇文章同一时刻最大在看人数
问题:统计每篇文章同一时刻最大在看人数,如果同一时刻有进入也有离开时,先记录用户数增加再记录减少,结果按最大人数降序。
注意:同一时刻最大再看人数不是说该时刻有多少人开始阅读,还有前面提前进来看文章的但还没离开的
难点在于如何计算瞬时的最大计数(在看人数)
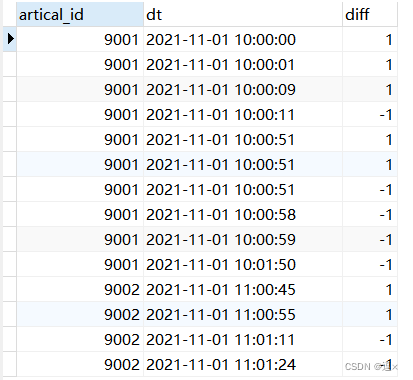
首先,我们自然会想到常见的编码+联立。在此对原表in_time和out_time进行编码,in为观看人数+1, out为观看人数-1,进行两次SELECT联立,并按artical_id升序,时间戳升序:
(注意:where artical_id != 0的条件,虽然表中没有等于0的但是题目有说明会有这种情况,那么代码中也要考虑)
SELECT
artical_id, in_time dt, 1 diff
FROM tb_user_log
WHERE artical_id != 0
UNION ALL
SELECT
artical_id, out_time dt, -1 diff
FROM tb_user_log
WHERE artical_id != 0
ORDER BY 1,2
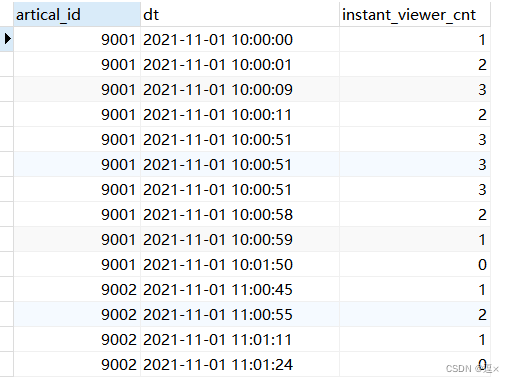
SELECT
artical_id,
dt,
SUM(diff) OVER(PARTITION BY artical_id ORDER BY dt) instant_viewer_cnt
FROM (
SELECT
artical_id, in_time dt, 1 diff
FROM tb_user_log
WHERE artical_id != 0
UNION ALL
SELECT
artical_id, out_time dt, -1 diff
FROM tb_user_log
WHERE artical_id != 0) t1
题目要求在瞬时统计时遵循【先进后出】:如果同一时刻有进入也有离开时,先记录用户数增加,再记录减少。
因此在ORDER BY层面,在遵循dt升序的同时,还要遵循先+1,再-1的原则,即diff DESC:
SUM(diff) OVER(PARTITION BY artical_id ORDER BY dt, diff DESC)
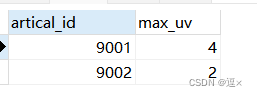
SELECT
artical_id,
MAX(instant_viewer_cnt) max_uv
FROM (
SELECT
artical_id,
SUM(diff) OVER(PARTITION BY artical_id ORDER BY dt, diff DESC) instant_viewer_cnt
FROM (
SELECT
artical_id, in_time dt, 1 diff
FROM tb_user_log
WHERE artical_id != 0
UNION ALL
SELECT
artical_id, out_time dt, -1 diff
FROM tb_user_log
WHERE artical_id != 0) t1
) t2
GROUP BY 1
ORDER BY 2 DESC
- 敲黑板!!! 解释排序这部分order by dt, diff desc
第一步:理解 order by Time
order by Time 这个巧妙地将时间揉在了一起(不管是进,还是出),先把时间从小到大排在了一起。举个例子——同一篇文章A的观看时间:
第一个人是在1分的时候开始看,5的时候结束。
第二个人是在4分的时候开始看,6分的时候结束。
第三个人是在5分的时候开始看,7分的时候结束。
一旦排序,就变成了: 1(开始看),4(开始看),5,5(开始看、结束),6, 7.这样就知道哪些人在同一时刻看同一篇文章了。很明显,时间在4分钟至5分钟的时候,第一个人和第二个人在同一个时间内观看文章A。
第二步:理解 order by diff desc
题目要求在瞬时统计时遵循【先进后出】。这里第二次排序就是对【先进后出】的解释
order by diff desc(先 1再-1)这里不是时间的大小了,用降序desc,就只是让 1(先算进去的)排前面, -1(再算退出去的)排后面的区别。那就变成了:1(+1), 4(+1), 5 (+1), 5(-1), 6(-1), 7(-1)
(desc:降序、asc:升序——仅对前面的字段有效)
- group by 1 order by 2
group by, order by 后面跟数字,指的是 select 后面选择的列(属性),1 代表第一个列(属性),依次类推。
164——2021年11月每天新用户的次日留存率
问题:统计2021年11月每天新用户的次日留存率(保留2位小数)
注:
- 次日留存率为当天新增的用户数中第二天又活跃了的用户数占比。(新增的用户第二天还活跃的)
- 如果in_time-进入时间和out_time-离开时间跨天了,在两天里都记为该用户活跃过,结果按日期升序。
解题思路:
-
先查询出每个用户第一次登陆时间(最小登陆时间)–每天新用户表(先找到新增的用户)
-
因为涉及到跨天活跃,所以要进行并集操作,将登录时间和登出时间取并集,这里union会去重–用户活跃表
(取登入时间和登出时间说明用户在这些时间都有活跃,由于in_time-进入时间和out_time-离开时间有可能跨天,所以登出时间也要)
-
将每天新用户表和用户活跃表左连接,只有是同一用户并且该用户第2天依旧登陆才会保留整个记录,否则右表记录为空
-
得到每天新用户第二天是否登陆表后,开始计算每天的次日留存率:根据日期分组计算,次日活跃用户个数/当天新用户个数
select first_in dt,round(count(t2.uid)/count(first_in),2) uv_left_rate from
(select uid, min(date(in_time)) first_in
from tb_user_log
group by uid) t1
left join
(select uid,date(in_time) dt
from tb_user_log
union
select uid,date(out_time) dt
from tb_user_log) t2
on t1.uid = t2.uid and first_in = date_sub(t2.dt,Interval 1 day)
where date_format(first_in,'%Y-%m') = '2021-11'
group by first_in
order by first_in
date_sub函数的语法及其用法
(1)语法:date_sub(,interval <interval_expr> <date_type>)
参数说明
date:日期表达式,可为字段或者获取日期的表达式,也可直接引用日期字符串比如“2021-02-03”。
interval_expr:时间间隔,可为整数,比如20。
date_type:日期类型,可为second(秒)、minute(分)、hour(小时)、day(天)、week(周)、month(月)、year(年)等。
(2)用法:从日期减去指定的时间间隔,获取指定日期
union与union all的区别
- 区别1:取结果的并集
1、union: 对两个结果集进行并集操作, 不包括重复行,相当于distinct, 同时进行默认规则的排序;
2、union all: 对两个结果集进行并集操作, 包括重复行, 即所有的结果全部显示, 不管是不是重复;
- 区别2:获取结果后的操作
1、union: 会对获取的结果进行排序操作
2、union all: 不会对获取的结果进行排序操作
union all只是合并查询结果,并不会进行去重和排序操作,在没有去重的前提下,使用union all的执行效率要比union高
165——统计活跃间隔对用户分级结果
问题:统计活跃间隔对用户分级后,各活跃等级用户占比,结果保留两位小数,且按占比降序排序。
注:
- 用户等级标准简化为:忠实用户(近7天活跃过且非新晋用户)、新晋用户(近7天新增)、沉睡用户(近7天未活跃但更早前活跃过)、流失用户(近30天未活跃但更早前活跃过)。
- 假设今天就是数据中所有日期的最大值。
- 近7天表示包含当天T的近7天,即闭区间[T-6, T]
解题思路:
- 流失用户:用户最后活跃的日期距离今天>30
- 沉睡用户:用户最后活跃的日期距离今天>7
- 新晋用户:用户最开始活跃的日期距离今天<7
- 忠实用户:最后活跃的日期距离今天<7 且 最开始活跃期距离今天>7
所以要获取用户最早和最晚的活跃日期
-
计算今天的日期及总用户数量
select max(date(out_time)) as cur_dt, count(distinct uid) as user_cnt from tb_user_log -
计算每个用户最开始和最晚活跃日期
select uid,min(date(in_time)) as first_dt, max(date(out_time)) as last_dt from tb_user_log group by uid -
计算最开始、最晚活跃期距离今天的天数差
-
使用case when 分类每个用户等级
-
统计每个等级的占比
select user_grade,round(count(uid)/Max(user_cnt),2) as ratio
from(
select uid,user_cnt,
case
when last_dt_diff >= 30 then "流失用户"
when last_dt_diff >= 7 then"沉睡用户"
when first_dt_diff < 7 then "新晋用户"
else "忠实用户"
end as user_grade
from(
select uid,user_cnt,
timestampdiff(day,first_dt,cur_dt) as first_dt_diff,
timestampdiff(day,last_dt,cur_dt) as last_dt_diff
from
(select uid,min(date(in_time)) as first_dt,
max(date(out_time)) as last_dt
from tb_user_log
group by uid) t_uid_first_last
left join
(select max(date(out_time)) as cur_dt,
count(distinct uid) as user_cnt
from tb_user_log) t_overall_info
on 1)as t_user_info) t_user_grade
group by user_grade
order by ratio desc















 3279
3279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









