






引言
【又一个中国大模型在各大主流榜单全面超越DeepSeek V3!】
朋友们,AI圈再次掀起波澜!
这次是阿里通义千问推出的全新MOE大模型——Queen2.5 Max,不仅超越了爆火的DeepSeek V3,还在多个榜单中杀入前列。
Qwen2.5-Max 的工作原理是什么?
Qwen2.5-Max 采用专家混合(MoE)架构,DeepSeek V3 也采用了这种技术。 这种方法既能扩大模型规模,又能控制计算成本。 让我们以一种易于理解的方式来分解其关键组成部分。
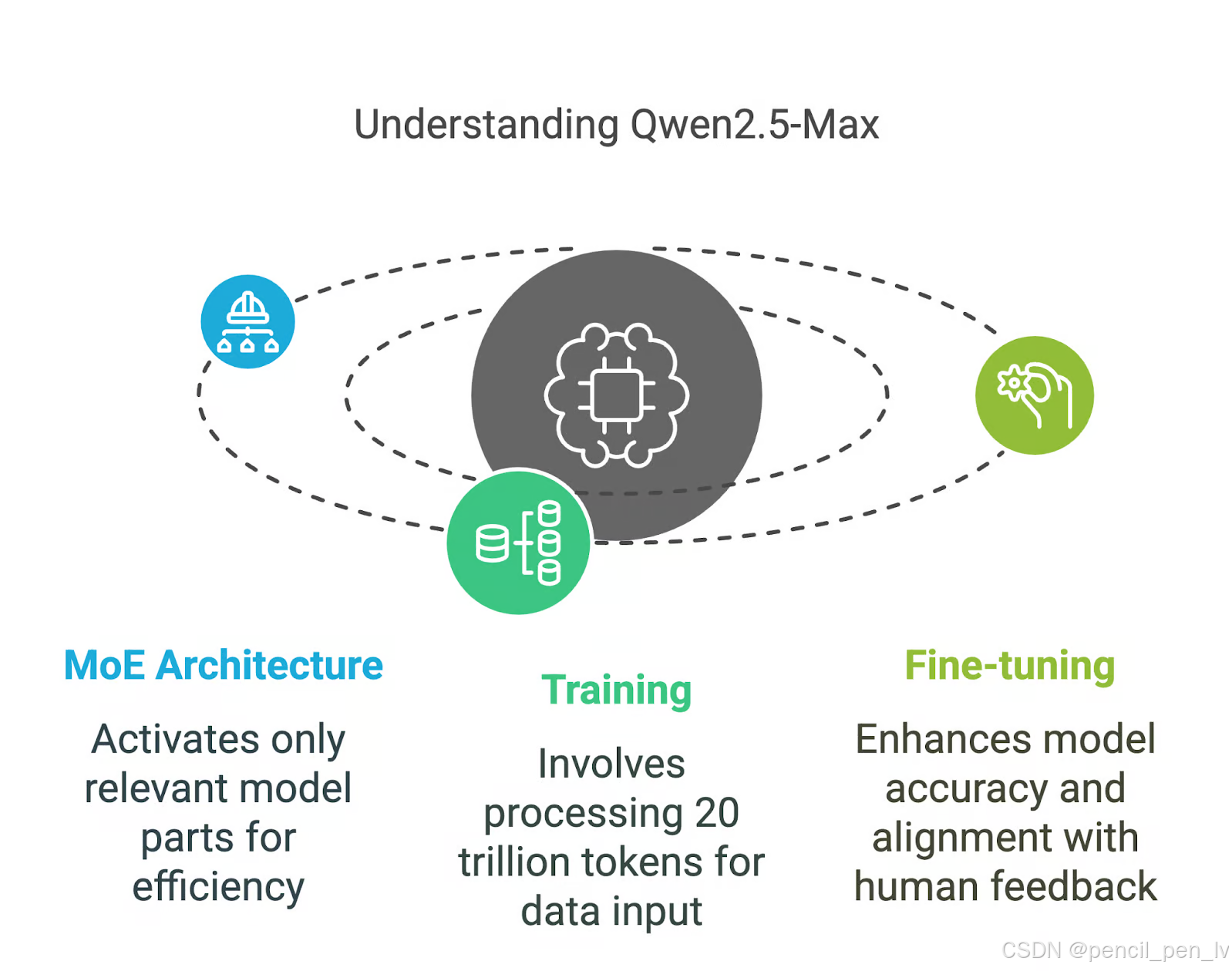
1.Mixture-of-Experts (MoE) 架构
传统的人工智能模型在处理每项任务时,会启用所有的参数。然而,Qwen2.5-Max 和 DeepSeek V3 等 MoE 模型却有所不同,它们在任何时刻都仅激活模型中最相关的部分。
这就好比是一个由各类专家组成的团队。倘若您抛出一个复杂的物理难题,那么只有物理方面的专家会予以回应,团队的其他成员则会保持安静。这种选择性激活的方式,让模型能够更高效地应对大规模处理任务,而无需依赖超高的计算能力。
凭借这种方法,Qwen2.5-Max 不仅实力强劲,还具备良好的可扩展性。这使得它能够与 GPT-4o 和 Claude 3.5 Sonnet 等密集模型一较高下,同时还能更加节省资源。所谓密集模型,是指对每个输入都会激活所有参数的模型。
-
MoE在扩展和效率方面的优势:
- 任务专业化:每个专家子模型可以专注于特定领域或输入类型,提高模型针对不同任务生成专业回复的能力。例如,一个专家可能更擅长处理编码任务,而另一个则针对常识知识进行了优化。
- 高效扩展:MoE架构避免了使用大规模单一模型以通用方式处理所有任务的情况,它允许Qwen2.5-Max通过添加更多专家来扩展规模,而无需按指数级增加计算需求。这意味着Qwen2.5-Max可以在保持成本效益和降低计算开销的同时实现高性能。
- 动态专家选择:MoE模型使用一种机制,使模型能够为每个输入仅选择相关专家。这种选择性激活减少了推理过程中的计算量,使模型在实际部署中更高效。
2.训练与微调:
✅海量数据训练
Qwen2.5-Max 在 20 万亿个词库上进行了训练,涵盖了广泛的主题、语言和语境。从代币数量来看,这大约相当于 15 万亿个单词,其规模之大令人难以估量 。为了帮助理解这一庞大的数字,可以做一个简单的对比:乔治·奥威尔的经典小说《1984》包含约 89,000 个单词,这意味着 Qwen2.5-Max 的训练数据相当于在 1.68 亿本《1984》的基础上进行的训练。这种海量的数据为模型提供了坚实的知识基础,使其能够应对各种复杂任务。
✅高质量数据优化
然而,仅仅依靠庞大的原始训练数据并不足以确保一个高质量的人工智能模型。为此,阿里巴巴团队通过多种技术手段对 Qwen2.5-Max 进行了进一步优化,以提升其性能和实用性:
1. 监督微调(SFT)
在监督微调阶段,人工标注员为模型提供了高质量的回复示例,指导模型生成更准确、更有用的输出结果。这种方法类似手把手教,帮助模型更好地理解和回应用户的需求 。
- 特定任务性能提升:微调有助于模型在某些类型的任务上实现专业化,例如处理复杂查询或总结长篇文档。通过从这些特定示例中学习,模型能够更好地解决现实世界中的问题。
- 任务特定调整:SFT确保模型在目标用例中的输出符合人类期望,从而产生更准确、相关的回复。
2. 从人类反馈中强化学习(RLHF)
阿里巴巴还采用了 从人类反馈中强化学习(RLHF)的方法,使模型的回答更加自然且贴近实际情境。通过收集人类用户的偏好数据,模型被训练得更能理解人类意图,从而生成更具人性化和实用性的回答 。
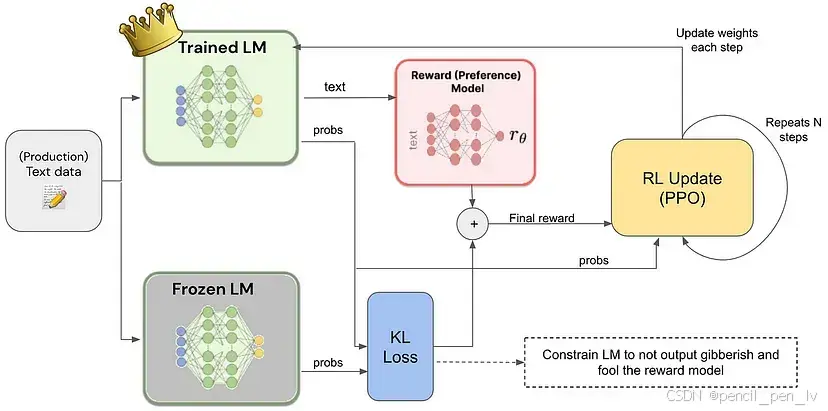
- **符合人类偏好**:RLHF确保模型的输出更符合人类偏好,提高了它产生满足用户需求和期望的回复的能力。
- **提高可靠性**:通过根据现实世界的反馈不断优化输出,Qwen2.5-Max随着时间的推移可以生成更可靠、准确的结果。
3.现实世界类比
可以把RLHF想象成训练自动驾驶汽车。如果汽车转弯不当,人为干预会纠正它,系统就会学习在未来避免这个错误。
3.Qwen2.5-Max 基准测试
Qwen2.5-Max 已与其他领先的人工智能模型进行了测试,以衡量其在各种任务中的能力。 这些基准测试同时评估了指导模型(针对聊天和编码等任务进行了微调)和基础模型(微调前的原始基础)。 了解这一区别有助于明确这些数字的真正含义。
✅指令模型基准
指导模型针对实际应用进行了微调,包括对话、编码和常识任务。 这里将 Qwen2.5-Max 与 GPT-4o、Claude 3.5 Sonnet、Llama 3.1 405B 和 DeepSeek V3 等模型进行比较。
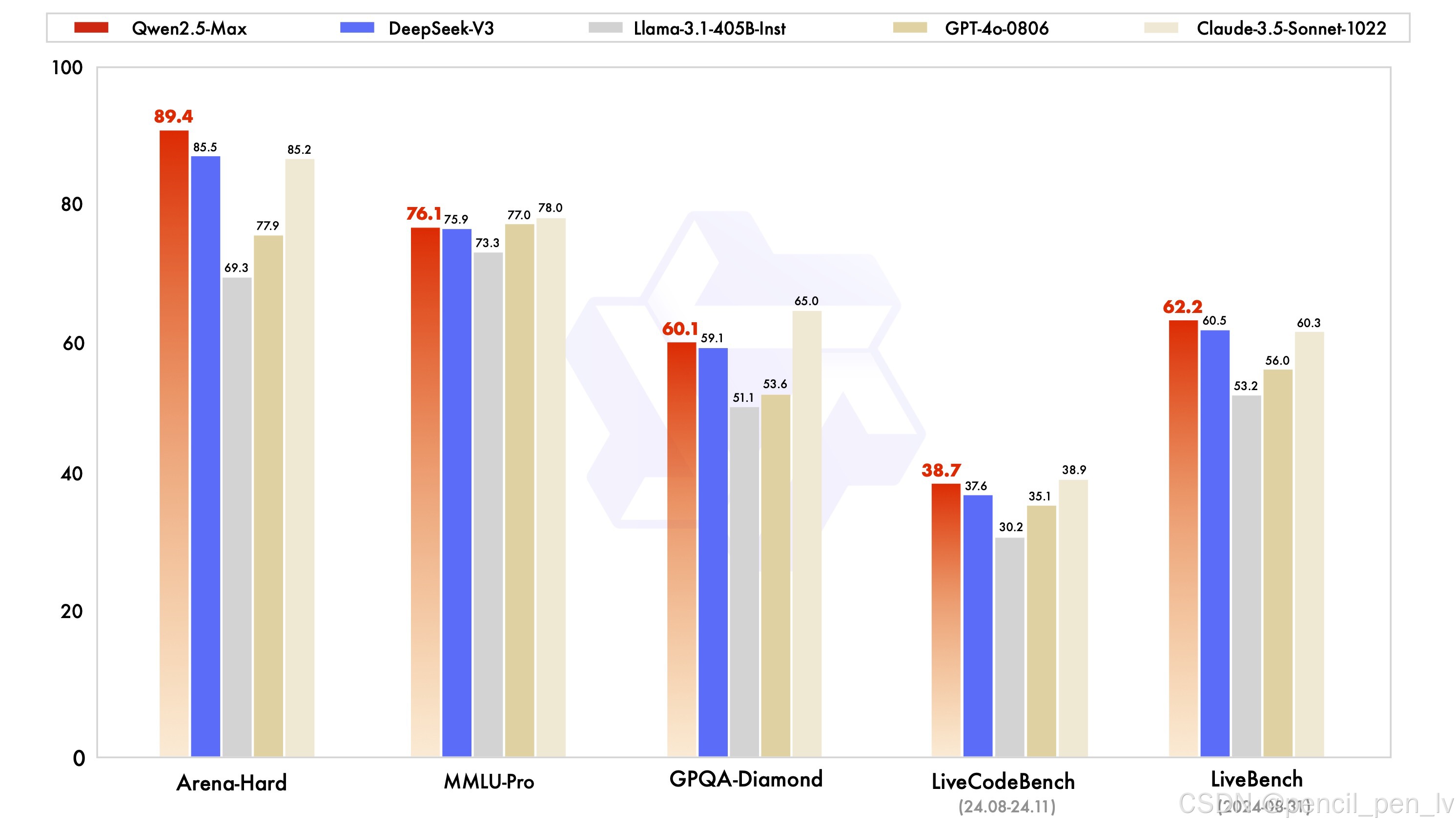
来源:QwenLM
让我们快速分析一下结果:
-
Arena-Hard(偏好基准): Qwen2.5-Max 得分为 89.4,领先于 DeepSeek V3(85.5)和 Claude 3.5 Sonnet(85.2)。 该基准近似于人类对人工智能生成的反应的偏好。
-
MMLU-Pro(知识与推理): Qwen2.5-Max 得分为 76.1,略高于 DeepSeek V3(75.9),但也略低于领先者 Claude 3.5 Sonnet(78.0)和亚军 GPT-4o(77.0)。
-
GPQA-Diamond(常识问答): Qwen2.5-Max的得分为60.1,超过了DeepSeek V3(59.1),而Claude 3.5 Sonnet则以65.0领先。
-
LiveCodeBench(编码能力):Qwen2.5-Max的得分为38.7,超过了DeepSeek V3(59.1): Qwen2.5-Max的编码能力为38.7,与DeepSeek V3(37.6)大致相当,但落后于Claude 3.5 Sonnet(38.9)。
-
LiveBench(整体能力): Qwen2.5-Max 以 62.2 分遥遥领先,超过了 DeepSeek V3(60.5 分)和 Claude 3.5 Sonnet(60.3 分),这表明 Qwen2.5-Max 在实际人工智能任务中具有广泛的能力。
总之,Qwen2.5-Max 被证明是一个全面的人工智能模型,在基于偏好的任务和一般人工智能能力方面表现出色,同时还保持了竞争知识和编码能力。
✅基本模型基准
由于 GPT-4o 和 Claude 3.5 Sonnet 是没有公开基础版本的专有模型,因此比较对象仅限于 Qwen2.5-Max、DeepSeek V3、LLaMA 3.1-405B 和 Qwen 2.5-72B 等开放重量模型。 这样就能更清楚地了解 Qwen2.5-Max 与领先的大型开放模型之间的差距。
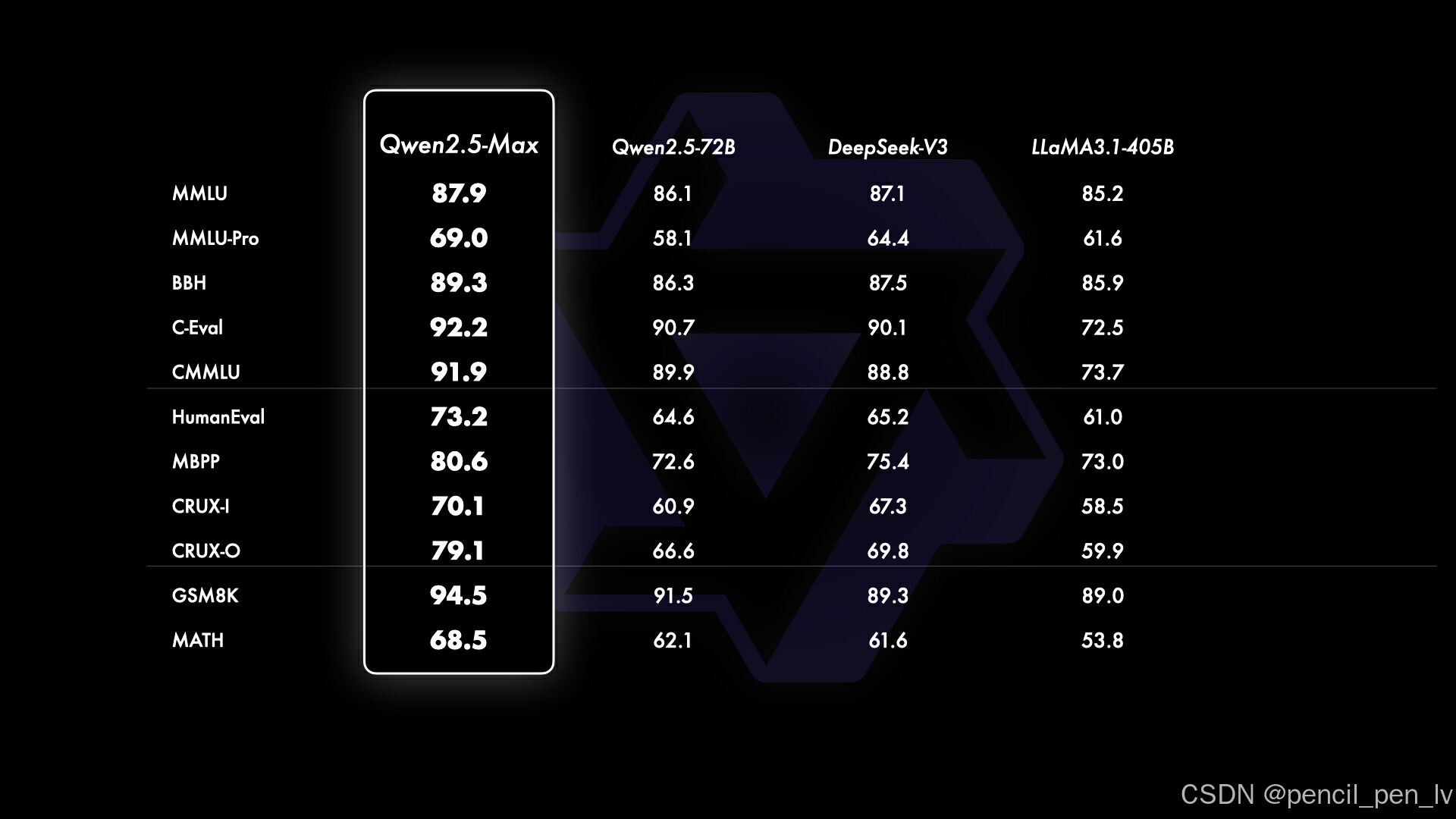
常识和语言理解
- MMLU:Qwen2.5-Max 得分 87.9,领先 DeepSeek V3 和 Llama 3.1-405B 。
- C-Eval:Qwen2.5-Max 得分 92.2,同样位居第一 。
编码和问题解决
- HumanEval:Qwen2.5-Max 得分 73.2,高于 DeepSeek V3,大幅领先 Llama 3.1-405B 。
- MBPP:Qwen2.5-Max 得分 80.6,继续保持优势 。
数学问题解决
- GSM8K:Qwen2.5-Max 得分 94.5,远超 DeepSeek V3和 Llama 3.1-405B。
- MATH:Qwen2.5-Max 得分 68.5,虽有优势,但仍有提升空间 。
国外友人直呼:“Can someone ask China to take a break?” 这次我们不光要关注它的性能,更要看看它如何改变我们的日常生活与工作方式。
 |  |
 |  |
 |  |
 |  |
4.如何访问 Qwen2.5-Max 访问
Qwen2.5-Max的最快方法是通过Qwen Chat平台。 这是一个基于网络的界面,允许您直接在浏览器中与模型互动,就像在浏览器中使用 ChatGPT 一样。
要使用 Qwen2.5-Max 模型,请单击模型下拉菜单并选择 Qwen2.5-Max: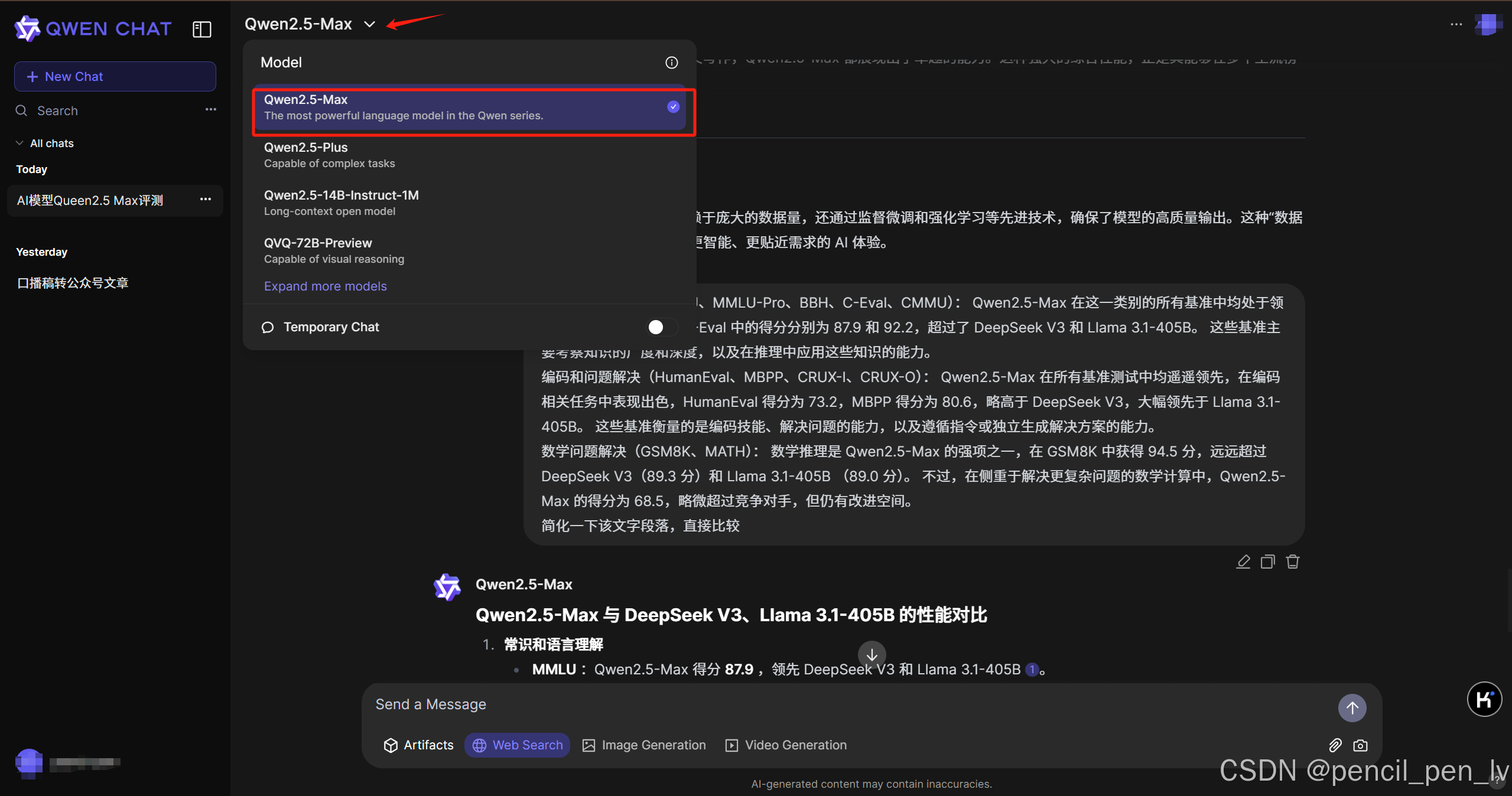
对于开发者来说,Qwen2.5-Max 可通过阿里云 Model Studio API 访问。 要使用它,你需要注册一个阿里云账户,激活 Model Studio 服务,并生成一个 API 密钥。 由于 API 遵循 OpenAI 的格式,因此如果你已经熟悉 OpenAI 模型,整合起来应该很简单。
有关详细设置说明,请访问 Qwen2.5-Max 官方博客。
春节假期里,咱们中国在动漫电影和大模型领域真是狠狠地秀了一波实力!
-
动漫电影《哪吒2》直接炸裂春节档,票房一路飙升,搞不好要成为第一部拿下春节档冠军的国产动画电影。这不仅是国产动漫的一次大突破,更是文化自信的体现,看得人热血沸腾!
-
大模型DeepSeek系列和Qwen2.5-Max简直像开了挂一样,在全球榜单上直接碾压国际对手。尤其是Qwen2.5-Max,数学、编程样样精通,连复杂的考研题都能轻松搞定。而且啊,三大电信企业都全面接入了DeepSeek开源大模型,应用场景越来越多,感觉AI离我们的生活越来越近了。
这个春节,不仅电影让人看得爽,科技也让人用得爽。国产AI这么争气,真的让人忍不住想喊一句:厉害了,我的国!未来可期啊!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









