







参考资料:
判别分析是一种经典的现行分析方法,其利用已知类别的样本建立判别模型,对未知类别的样本进行分类。在这里我们主要讨论fisher判别分析的方法。
fishter原理
费歇(FISHER)判别思想是投影,使多维问题简化为一维问题来处理。选择一个适当的投影轴,使所有的样品点都投影到这个轴上得到一个投影值。对这个投影轴的方向的要求是:使每一类内的投影值所形成的类内离差尽可能小,而不同类间的投影值所形成的类间离差尽可能大。
公式推导
这里给出一个二维的示意图(摘自周志华老师的《机器学习》一书),在接下来的讨论中我们也将以二维的情况做分类来逐步分析原理和实现。
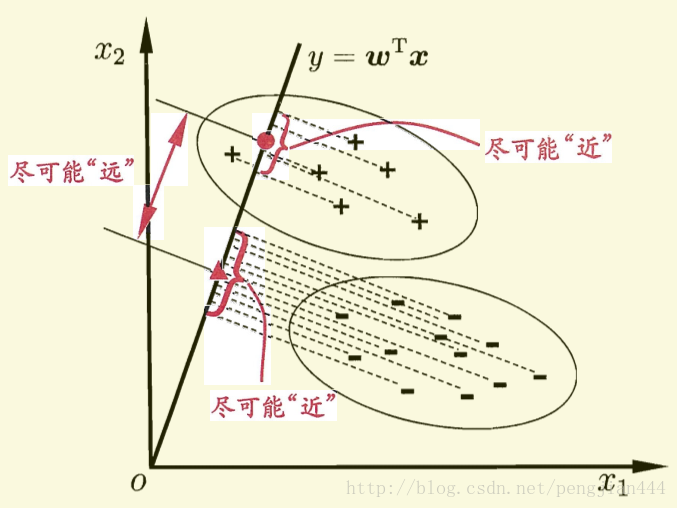
ps: 图中有一处描述似乎不是特别的准确,直线的方程应该是
而不是
ps: 因为在书关于此的其他讨论中,并未涉及任何y的概念,这里将y写入对我造成了某种误导。
对于给定的数据集,D(已经设置好分类标签),
Xi,Ui,∑i
分别表示给定类别
i
的集合,均值向量,协方差矩阵。现将数据投影到直线
这里定义“类内散度矩阵”(within-class scatter matrix)
以及类间离散度矩阵(between-class scatter matrix)
则 J 可重写为:
ps:sorry 这些公式确实敲得有点累,道个歉,我直接截图了。希望不影响大家的理解。

在推导出上面的公式之后我们就可以开始写代码了。
编程实现
数据生成
这里我偷一个懒,直接用scikit-learn的接口来生成数据:
from sklearn.datasets import make_multilabel_classification
import numpy as np
x, y = make_multilabel_classification(n_samples=20, n_features=2,
n_labels=1, n_classes=1,
random_state=2) # 设置随机数种子,保证每次产生相同的数据。
# 根据类别分个类
index1 = np.array([index for (index, value) in enumerate(y) if value == 0]) # 获取类别1的indexs
index2 = np.array([index for (index, value) in enumerate(y) if value == 1]) # 获取类别2的indexs
c_1 = x[index1] # 类别1的所有数据(x1, x2) in X_1
c_2 = x[index2] # 类别2的所有数据(x1, x2) in X_2fisher算法实现
def cal_cov_and_avg(samples):
"""
给定一个类别的数据,计算协方差矩阵和平均向量
:param samples:
:return:
"""
u1 = np.mean(samples, axis=0)
cov_m = np.zeros((samples.shape[1], samples.shape[1]))
for s in samples:
t = s - u1
cov_m += t * t.reshape(2, 1)
return cov_m, u1
def fisher(c_1, c_2):
"""
fisher算法实现(请参考上面推导出来的公式,那个才是精华部分)
:param c_1:
:param c_2:
:return:
"""
cov_1, u1 = cal_cov_and_avg(c_1)
cov_2, u2 = cal_cov_and_avg(c_2)
s_w = cov_1 + cov_2
u, s, v = np.linalg.svd(s_w) # 奇异值分解
s_w_inv = np.dot(np.dot(v.T, np.linalg.inv(np.diag(s))), u.T)
return np.dot(s_w_inv, u1 - u2)判定类别
def judge(sample, w, c_1, c_2):
"""
true 属于1
false 属于2
:param sample:
:param w:
:param center_1:
:param center_2:
:return:
"""
u1 = np.mean(c_1, axis=0)
u2 = np.mean(c_2, axis=0)
center_1 = np.dot(w.T, u1)
center_2 = np.dot(w.T, u2)
pos = np.dot(w.T, sample)
return abs(pos - center_1) < abs(pos - center_2)
w = fisher(c_1, c_2) # 调用函数,得到参数w
out = judge(c_1[1], w, c_1, c_2) # 判断所属的类别
print(out)绘图
import matplotlib.pyplot as plt
plt.scatter(c_1[:, 0], c_1[:, 1], c='#99CC99')
plt.scatter(c_2[:, 0], c_2[:, 1], c='#FFCC00')
line_x = np.arange(min(np.min(c_1[:, 0]), np.min(c_2[:, 0])),
max(np.max(c_1[:, 0]), np.max(c_2[:, 0])),
step=1)
line_y = - (w[0] * line_x) / w[1]
plt.plot(line_x, line_y)
plt.show()最后一步【贴图】
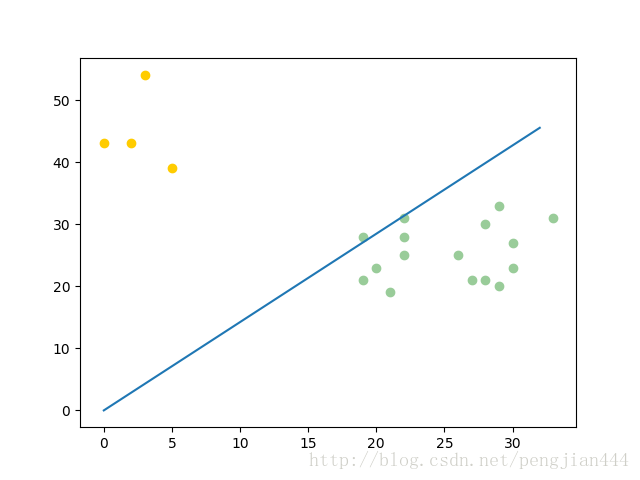
最后的最后,大家只要把上面所有的代码复制粘贴到一个文件夹下,在python3 环境下运行就好了。本人调试运行的环境为:
- python3
- ubuntu 16.04
- pycharm















 2423
2423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









