






“
尽管大语言模型在多个领域取得了突破性进展,但其训练与推理的效率问题仍然是当前技术发展的一大瓶颈。为此,小米集团大模型团队联合Kaldi之父Daniel Povey提出了SUBLLM(Subsampling-Upsampling-Bypass)大型语言模型。与以往的大模型相比,SUBLLM的推理速度最多可以提升50%以上。
”
想象一下,当你求助AI帮忙处理一篇万字长文时,你希望能迅速了解文章的重点,但面对庞大的文字量,传统大模型的处理能力则有些力不从心。
目前,云端的大模型处理类似的长文本任务,通常需要动用多达8个GPU,这个过程不仅耗时,而且成本昂贵。如果将大模型类比于人脑,那么当前大模型的运行功率相比于人脑的运行功率的100倍以上。大语言模型(LLMs)在自然语言处理(NLP)领域取得了重要进展,深入了日常生活的方方面面,但大语言模型在训练和推理的过程中,对计算资源和内存的需求却异常庞大。
此前,Daniel Povey在语音识别领域提出了Zipformer,Zipformer可以用最低压缩16倍的帧率,达到与更大模型一致甚至更高的语音识别率,完成了语音识别领域的“四两拨千斤”。在Zipformer的启发下,小米集团大模型团队尝试将这一思路创新性地扩展至大型语言模型中,在性能不受损害的前提下,实现了更高效率的大模型运算。
01
就像在一万字中挑选最关键的五百字
与以往的大模型架构相比,小米大模型团队以其创新的SUBLLM架构,显著提升了效率,展现了行业领先的技术实力。SUBLLM的工作原理通过引入子采样、上采样和旁路模块等方式,对计算资源动态分配,从而减少了冗余的token计算负担,加速了模型的训练和推理过程。能做到就像在一万字中挑选最关键的五百字一样,保留文本中必需的部分,删减其中的冗余,从而让大模型所需处理的文本更短。
就具体实现路径而言,会将子采样模块根据token的重要性分数对其进行筛选,保留重要的token并丢弃不重要的部分。随后,上采样模块将子采样后的序列恢复到原始长度,确保语言模型在生成token时的顺序一致性。同时,旁路模块通过结合子采样前后的序列,进一步提高了模型的收敛速度。这种设计不仅显著减少了计算成本,还保持了输入序列的语义完整性。
 图:对文本序列进行子采样的有效性探究
图:对文本序列进行子采样的有效性探究
如果将SUBLLM理解为一个聪明的编辑,就像我们的大脑会识别要点一样,它可以在阅读一大段文字时快速识别出哪些词是关键的,哪些词不那么重要。SUBLLM会保留那些重要的词汇,而忽略那些不太重要的部分,这就大大减少了需要处理的信息量。
随后,就像我们能通过只言片语补充完整故事的来龙去脉,SUBLLM也能将精简后的信息恢复到原有的完整度,确保整个文本在表达时的连贯与完整。在处理信息时,SUBLLM还能更加迅速地找到最佳的表达方式。
与LLaMA等大型语言模型相比,SUBLLM在训练和推理速度以及降低内存方面都有了显著改善。例如根据已有的训练数据,在训练中,SUBLLM的速度提高了26%,每个GPU的内存减少了10GB。在推理中,它的速度提高了高达37%,每个GPU的内存减少了1GB。训练和推理速度分别最高可以提高至34%和52%。同时,SUBLLM还保持了有竞争力的少样本学习性能。
02
智能处理数据,训练推理更高效
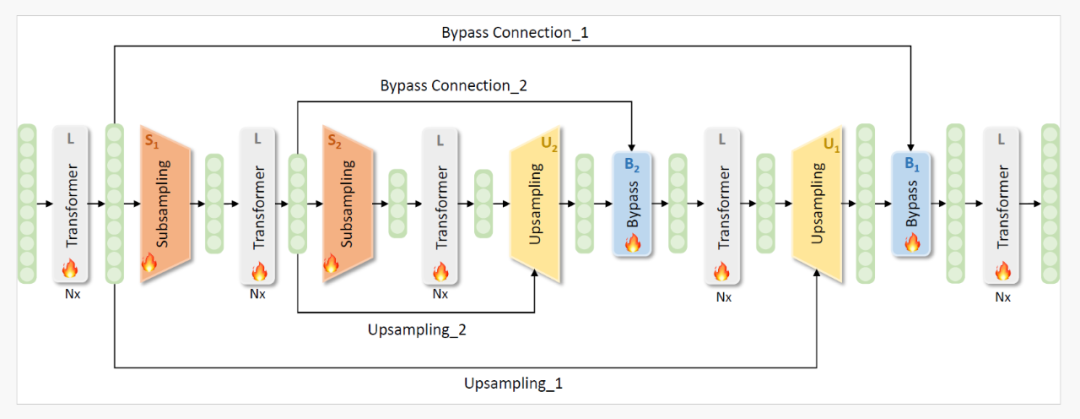
SUBLLM的模型结构是基于decoder-only的大型语言模型架构,在不改变原有模型结构的基础上,在一些特殊的层上进行了结构升级。为了管理要处理的token数量,子采样和上采样模块被集成到Transformer块之间。
首先,模型使用几个Transformer块处理完整序列,捕获全面的token序列表示。引入子采样模块后,这些模块暂时去除不关键的token,从而减少处理所需的序列长度。然后对缩减后的序列进行更多次的子采样过程,也就是序列的缩减是嵌套的。序列压缩的最高级别发生在网络的最中间的Transformer块中。随后,使用上采样模块逐步恢复序列长度。这些模块将较短的处理序列与子采样前的原始序列合并,将它们恢复到完整长度。这种机制允许仅解码器模型作为语言模型操作,按顺序生成token,保证输入和输出序列长度相同。此外,上采样过程后集成了绕过连接模块,以利用每个子采样前的嵌入,帮助改进从子采样到上采样的学习过程。随后的实验证实,这种方法显著提高了收敛效率。
这项工作的主要贡献总结如下:
提出了一种新颖的架构,SUBLLM,它提出了子采样、上采样和绕过模块。这种设计通过绕过连接动态地将资源分配给重要token,减少了与token冗余相关的计算成本,并加速了模型收敛。
提出了一种新颖的token序列子采样方法,有效测量token重要性得分,并控制得分值的分布,以实现推理期间期望的子采样保留比率。
实验结果表明,与LLaMA模型相比,SUBLLM在训练和推理方面分别实现了26%和37%的速度提升,同时显著降低了内存成本,同时保持了性能。
 图:主要实验结果
图:主要实验结果
简单来说,SUBLLM通过智能地选择和处理数据,使得模型在训练和推理时更加高效。子采样模块剔除不必要的信息,上采样模块恢复数据的完整性,而绕过模块则加快了学习过程。这些技术的结合使得SUBLLM在处理大型语言模型时,实现更快的速度和更低的内存使用。
03
成为一粒种子
无独有偶,大语言模型效率优化问题已经得到了行业的广泛关注。
前不久,大洋彼岸的谷歌deepmind提出了mixture of depths(MoD)模型结构,MoD使用静态计算预算,使用每个块的路由器选择token进行计算,并通过对自注意力和MLP块或残差连接的选择来优化FLOP使用。更早以前,经典论文CoLT5使用条件路由来决定给定token是通过轻量分支还是重量分支在前馈和注意力层中传递,以便将更多资源分配给重要token。
与这些模型结构类似,SUBLLM采用的原理接近于人脑对于信息的处理机制。人脑有两种思维模式,一种低功耗的快模式,一种高功耗的慢模式,分工明确,且两种模式恰恰用的是同一个脑部区域。因此,SUBLLM作者也从这一信息处理模式的角度思考了如何将大模型的算力进行合理地分配:重要的token用全部算力,相对不重要的token使用更少算力。
相似动机但不同路径的研究,也再次证明了国内大模型研究的创新力已经与国际顶尖水平并驾齐驱。
小米这次的创新不仅在展示一种高效的模型架构,更希望通过开源代码,激励更多的研究者在这一方向上继续探索。比起一次创新,小米更希望SUBLLM能够作为一个“种子”,推动更多关于大语言模型效率提升的研究,推动人工智能领域的进一步发展!
论文链接:https://arxiv.org/abs/2406.06571


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









