






一、背景
2014年11月,亚马逊推出了一款全新概念的智能音箱:Echo,这款产品最大的亮点是将智能语音交互技术植入到传统音箱中,从而赋予了音箱人工智能的属性。这个被称为“Alexa”的语音助手可以像你的朋友一样与你交流,同时还能为你播放音乐、新闻、网购下单、Uber叫车、定外卖等等。
随着Echo的流行,拥有多个Echo的用户越来越多,2016年,亚马逊推出了基于多设备的空间感知功能(ESP: Echo Spatial Perception)。与多设备交互时,ESP会选出离用户最近的设备去响应用户。
2017年7月,小米发布了首款小米AI音箱,在首款音箱推出后,我们就已经开始思考未来多设备唤醒交互的场景。2018年春季发布会上,随着小爱音箱mini的发布,正式推出了小爱就近唤醒功能(协同唤醒前身),当周围多个小爱设备被唤醒时,只有离用户最近的设备响应用户。
2020年11月的MIDC上,小爱就近唤醒升级为小爱协同唤醒。
二、小爱协同唤醒
协同唤醒是小爱多设备用户唤醒的基础功能,在手机、音箱、电视、大家电等多个智能设备周围说「小爱同学」时,小爱将智能选择一台合适的设备应答和倾听,避免一呼百应。
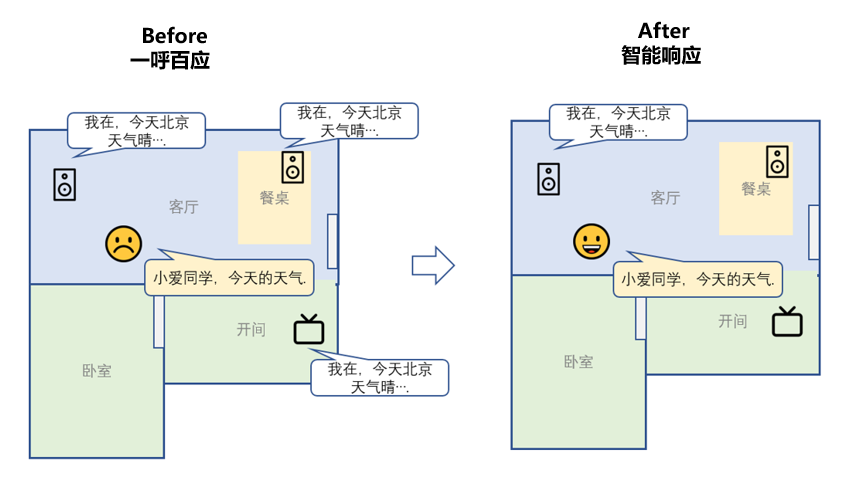
相对于早期AIoT设备间的就近唤醒,协同唤醒除了支持AIoT设备外,还支持了手机,实现手机与AIoT设备间的协同;不仅如此,多设备间响应策略从之前的就近策略升级为根据距离、活跃状态、设备品类等信息智能决策一台合适设备响应。
三、原理
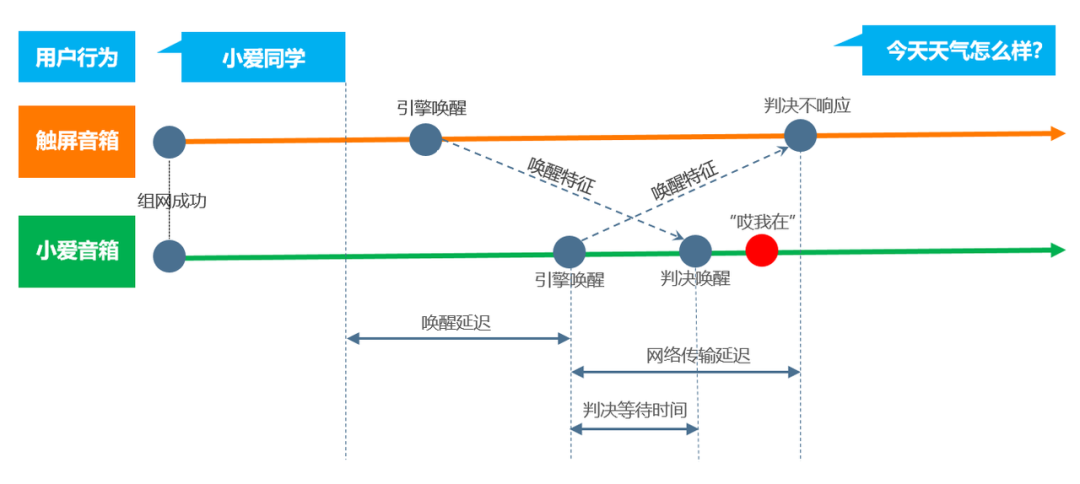
相同账号的小爱设备在用户唤醒之前,协同唤醒会将多设备聚合并组网。当用户唤醒小爱后,协同唤醒会提取唤醒词的方向、距离特征数据,并在组内设备间交互。收集完毕全局的特征数据或者决策等待超时时,结合各设备的状态等信息,进行分布式决策,最终选出一个合适的设备应答。
四、挑战
小爱协同唤醒已接入手机与AIoT设备众多,软硬件差异大,使用场景复杂,如何有效的将不同组合的设备在各种复杂场景高效的协同起来,存在非常大的挑战。主要表现在以下三个方面:
准确性影响因素多:麦克风硬件参数以及形态、环境噪声、唤醒时人的位置等是影响协同唤醒准确性的主要因素;
手机接入困难:手机作为低功耗设备,对功耗要求比较高,AIoT的传输方案在手机上会引入比较大功耗开销;
线上质量管控困难:线上质量指标主要是指协同唤醒失灵,发生同时唤醒的概率。根据协同唤醒原理,当唤醒特征消息传输延迟大或不同设备唤醒延迟差异大时,会导致判决等待时间内无法收全全局的信息,引起不同设备判决结果不一致,发生同时唤醒。判决等待时间的设定会影响同时唤醒率与设备应答速度,当判决等待时间过长,设备应答速度变慢,判决等待时间过短,同时唤醒概率升高。
五、解决方案
>>>>
5.1 准确性
不同设备因麦克风阵列形态和麦克风硬件参数不同,导致在相同位置的设备采集到的声音能量差异比较大。为了保证相同位置采集的能量数据一致性,算法在处理前,会对采集的音频数据进行归一化处理。
协同唤醒算法经历过以下两个大版本,目前我们采取的是基于直达声能量与方位信息综合判决。
基于能量
声音在空中传播过程中有能量衰减,传播距离越远,衰减越严重。早期通过麦克风采集的能量大小判断设备离说话人的远近,实现协同唤醒功能。该方案适用于安静场景,在周围存在环境噪声干扰时,会影响准确性。
基于直达声能量与方位
为了解决环境噪声干扰,从采集的数据中提取直达声的能量判断说话人与设备的远近,同时,也引入方位的特征,当人与两个设备距离相当时,通过说话人唤醒时的朝向,选中朝向的设备应答。
>>>>
5.2 手机协同唤醒
手机围绕着功耗在传输方案上做了很多改进,从早期复用AIoT传输链路到最终采用改进的小米推送链路,达成功耗和传输链路稳定性的要求。
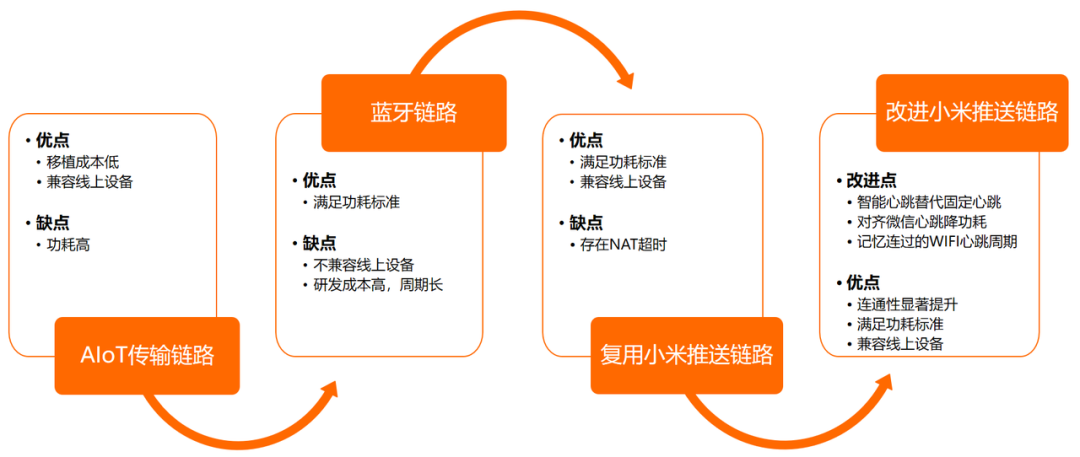
我们从以下三个方面对小米推送做出了改进,满足功耗、连通性要求,实现手机与AIoT设备间的协同唤醒功能:
智能心跳替代固定心跳:通过动态检测当前连接WiFi的NAT超时时间,调整小米推送心跳间隔,适配当前WiFi网络,解决NAT超时引起的连通性问题 ;
对齐微信心跳降功耗:因小米推送最小心跳周期大于微信心跳周期,当微信心跳时,会激活AP,同时通知小米推送同步心跳,避免小米推送主动激活AP,解决功耗问题 ;
记忆连接过的WiFi使用的心跳周期:对于已经连接过的WiFi网络,存储该WiFi网络下的心跳周期,每次连接该网络时,直接采用历史存储值,避免反复NAT超时检测引起功耗开销,进一步降功耗。
>>>>
5.3 线上质量
为了解决线上质量管控难的问题,我们搭建了一套智能运营系统。在设备端上,每次唤醒时,收集唤醒延迟、不同设备间消息传输延迟、设备组合、系统状态、网络信号强度等信息,然后根据大量线上数据,估计不同设备间在不同影响因素下的网络传输延迟以及唤醒速度差异,并下发到设备端,设备端根据下发参数,在设定范围内动态调节判决等待超时时间。
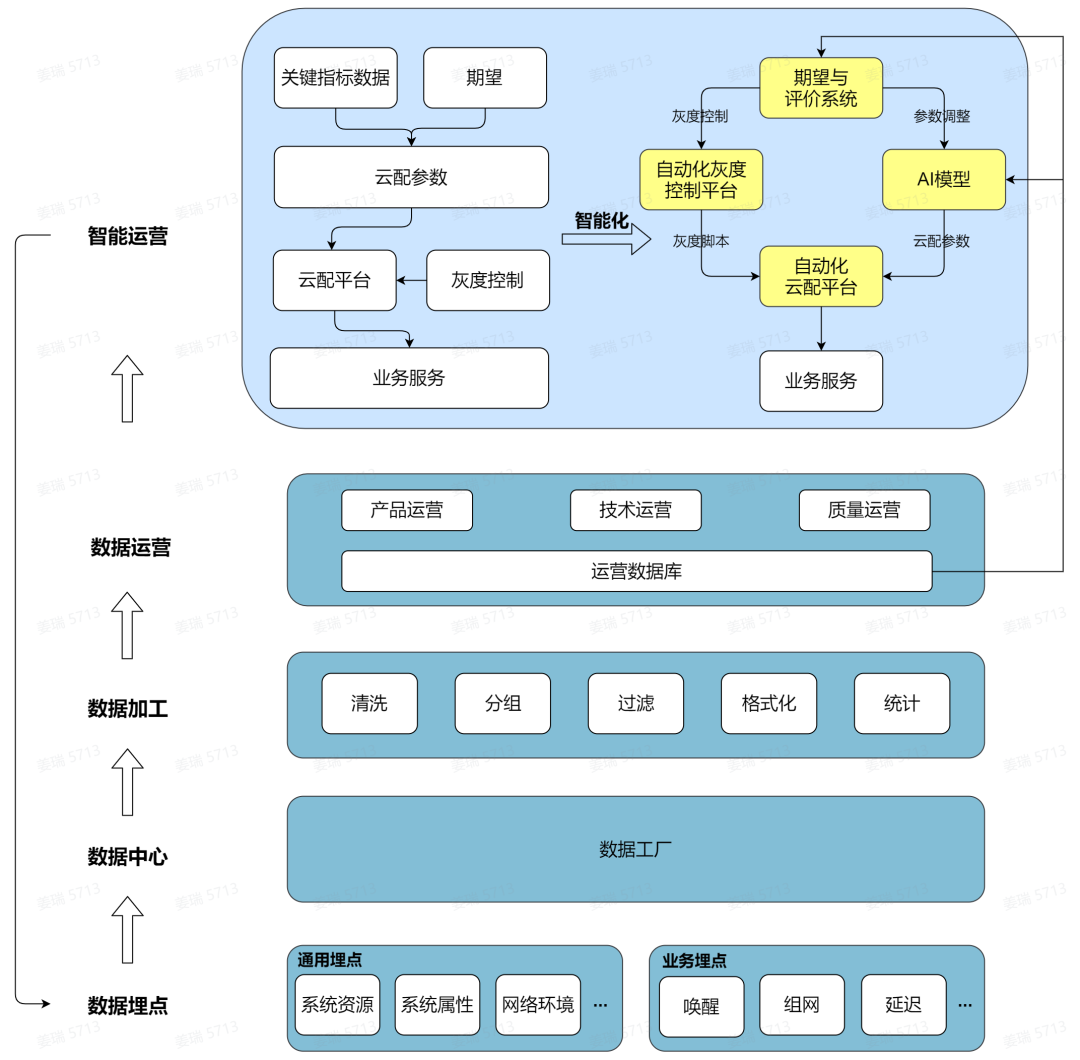
智能运营分两期,一期是基础能力建设,可以实现针对单设备以及不同的设备组合和不同场景下发不同的参数,这些参数的生成是需要人工重度参与,且是通用参数,会损失部分用户体验。二期在一期基础上实现了智能化,依托大数据和AI技术,自动的为每类或每个用户生成个性化的定制参数。
智能运营两个比较关键的服务:AI模型和期望与评价系统。AI模型根据大数据生成通用参数,然后结合每个用户的环境和行为的建模数据,生成定制化的参数,并通过自动化云配平台和灰度控制策略下发到设备端做AB测试。期望与评价系统会对AB测试的结果进行评估,如果不理想,则重新调整参数,输出到AI模型,并产生新的云配参数下发;如果评估可行,则启用下发给设备端的最新参数;通过这种方式不断循环迭代,达到预先设定的期望。
六、成果
>>>>
6.1 设备接入
已接入手机与AIoT设备超过60款,涉及手机、音箱、电视、IoT、大家电,在线设备超过千万级别。

>>>>
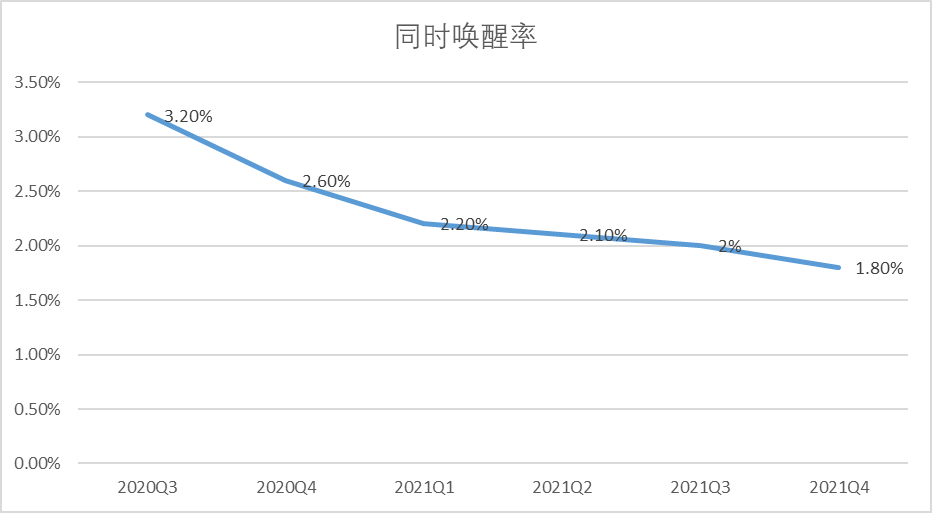
6.2 线上质量-同时唤醒率
因实验室环境比较理想,协同唤醒的质量指标以线上数据为参考。线上近一年的同时唤醒率从去年Q3平均3.2%下降到了目前1.8%,下降幅度43%。
七、未来规划
>>>>
7.1 更精确的空间感知
基于同账号的组网存在以下一些弊端:
同账号组网会无视距离,将两地设备组在一起(特别是手机),每次发生协同唤醒时,都需要等超时,从而影响唤醒整体的应答速度;
当家里的小爱设备登录多个账号或者不登录账号(比如电视)时,多个账号或无账号的设备无法协同唤醒。
为了解决以上问题,确保用户唤醒时,只有用户周边的设备参与协同唤醒,与账号、局域网完全解耦,我们将基于声学感知技术,实现家庭、公司、车载三大空间以及家庭内各小空间的精准感知。
>>>>
7.2 更稳定实时的传输
协同唤醒对消息传输实时性要求比较高,WiFi传输链路会受到设备所处网络环境以及路由拥塞程度影响,线上很大一部分协同唤醒失效是由于传输延迟高引起。
为了确保传输的稳定性和实时性,降低协同唤醒失效比例,通过WiFi、蓝牙多链路融合策略,实现消息多链路传输,从而满足设备间消息稳定实时的传输。
八、总结
小爱协同唤醒自上线以来,接入手机与AIoT设备超过60款,拥有多个小爱设备的用户也越来越多,如何实现1+1>2是协同唤醒团队一直努力的方向。不论是从技术创新还是质量管控上,我们一直都在追求极致的用户体验!
END



















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









