






对一个查询q, 包括t1,t2,...tm个词,在d1,d2,....dn,这n个文档中,推荐那一个给用户更加恰当.
基本xiangf如果一个文档包含了这t1,t2,...tm这m个词的话,并且出现频率都很高的话,那么可以认定这个文档可能比较好.
对∑中的每一个词ti,按其在所有文档中出现的情况(词频)定义一个向量vec(ti),称为( occurrence patterns )向量定义在文档空间,即为n.
此时通过余玄向量求任意两个词的相似度,这个相似度表达了词在文档中共现的特征。对查询的选择,就可以针对查询中词的向量和文档的相似度来进行。
sim(q,d) = sim(q,d) = Σi[maxj(sim(tqi, tdj)]
解释一下,q,和d的相似程度,是把q中的查询词汇,和文档中出现的全部词汇去比较相似度,选择一个相似度最大的,也就是共现性最大的,记录这个相似性,然后把所有的查询词得到的这个相似性累加,就是查询和文档的相似性,对一次查询,做n词这样的比较,就可以得到那些文档是和这次查询的企图最相似,就优先推荐。当然了,会有一个问题,一个文档越长可能越占便宜,他的关键字多,如果一个查询中包括的关键词越多,那么就越难猜测他这样就需要一个归一化方法。
sim(q,d) = sim(q,d) = Σi[maxj(sim(tqi, tdj)] / (|q|*|d|)
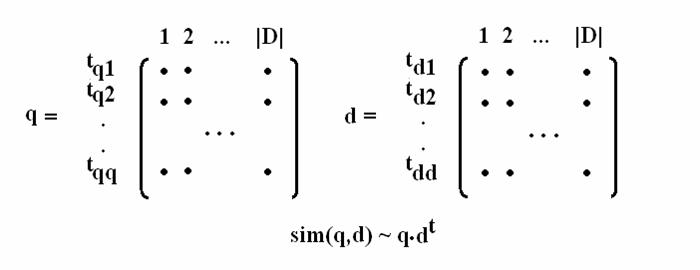
用矩阵的方法描述如上,dt表示转置矩阵。
Sim(q,d)为结果矩阵中每一行最大值的和















 2015
2015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









