







什么是特征工程?有什么用呢?
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
更好的特征工程意味着更强的灵活度,更好的特征意味着只需用简单模型,更好的特征意味着更好的结果。
数据清洗
特征处理
在特征处理中,主要有一下几种类型需要进行一些处理:
-
数值型
-
类别型
-
时间类
-
文本类
-
统计类
-
组合特征
特征处理之数值型
- 幅度调整
拿到获取的原始特征,为什么要对每一特征分别进行归一化呢?比如,特征A的取值范围是[-1000,1000],特征B的取值范围是[-1,1].如果使用logistic回归,w1*x1+w2*x2,因为x1的取值太大了,所以x2基本起不了作用。所以,必须进行特征的归一化,每个特征都单独进行归一化。
1.幅度调整到给定范围内,默认[0,1]
sklearn.preprocessing.MinMaxScaler(feature_range=(0, 1), copy=True)该方法称为离差标准化,是对原始数据的线性变换,其缺陷在当有新的数据加入时,可能导致X.max和X.min的值发生改变,需要重新计算。
计算公式为:
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min其中max,min为放缩的范围。
例子:

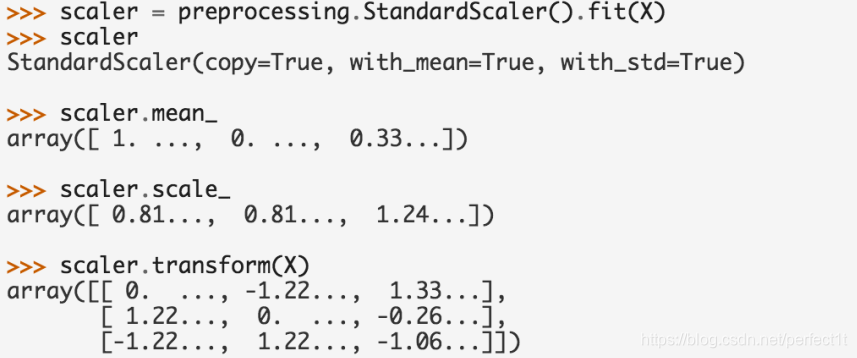
2.标准化
sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True)scaling,其实就是将一些变化幅度较大的特征化到[-1,1]之内。
计算公式:
Xscaled = (X - 均值) / 标准差
例子:
数据标准化的方法与意义:https://blog.csdn.net/fontthrone/article/details/74067064
- 统计值:max, min, mean, std等
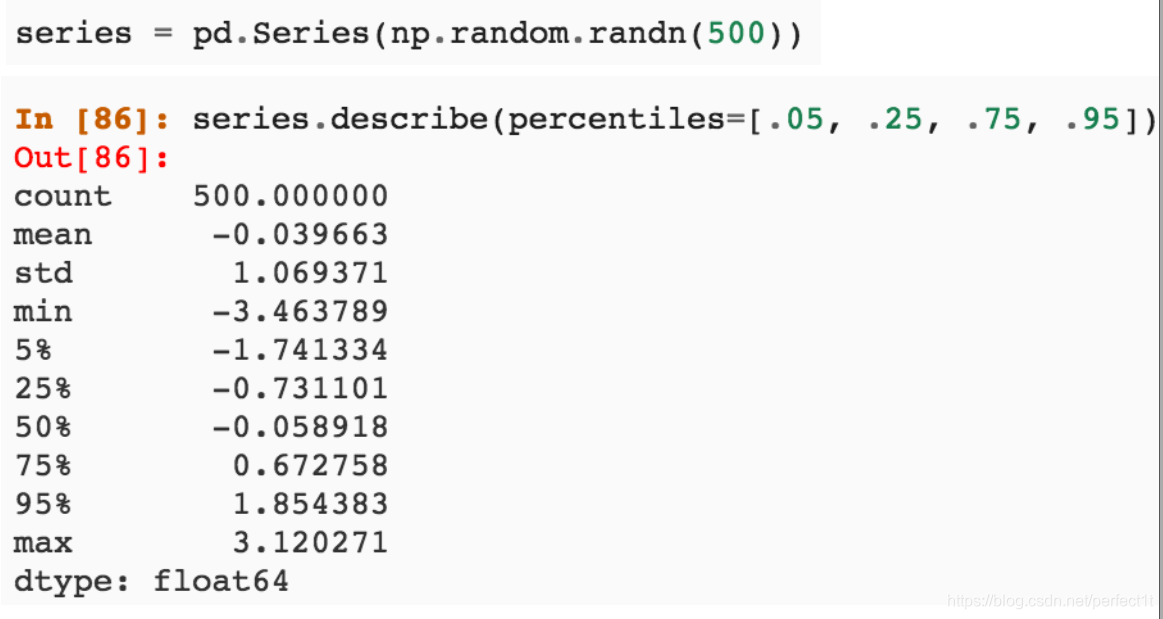
- 离散化
pandas.cut与pandas.qcut使用方法与区别:https://blog.csdn.net/cc_jjj/article/details/78878878
离散化:https://blog.csdn.net/programmer_wei/article/details/17200085
连续特征的离散化:在什么情况下将连续的特征离散化之后可以获得更好的效果?https://www.zhihu.com/question/31989952
例子:


特征处理之类别型
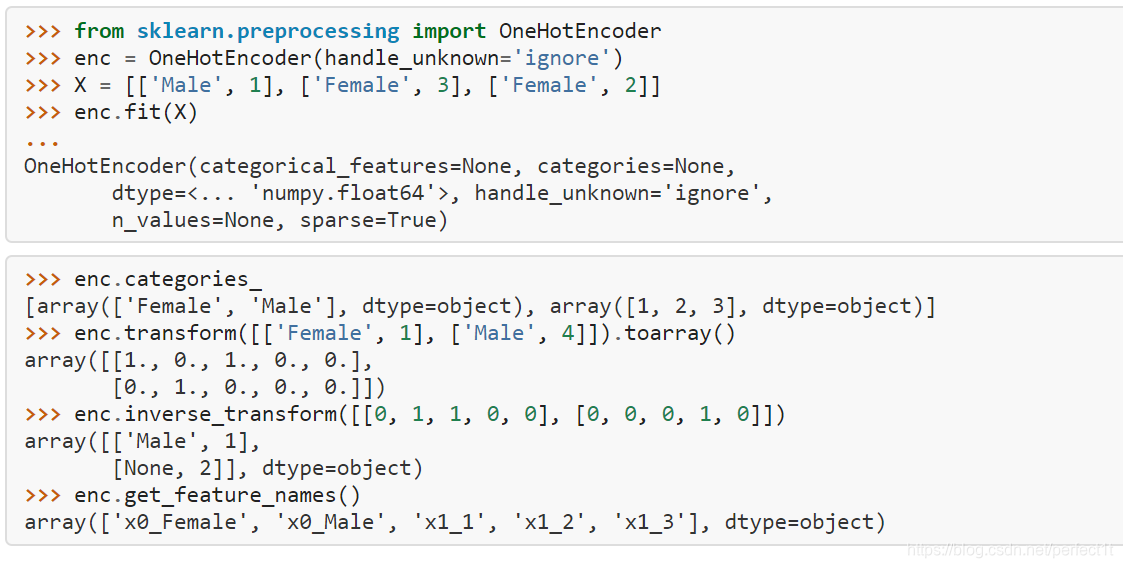
- One-hot编码/哑变量
one hot 编码及数据归一化:https://blog.csdn.net/dulingtingzi/article/details/51374487
离散型特征编码方式:one-hot与哑变量(区别):https://www.cnblogs.com/lianyingteng/p/7792693.html
sklearn.preprocessing.OneHotEncoder(n_values=None, categorical_features=None, categories=None, sparse=True, dtype=<class ‘numpy.float64’>, handle_unknown=’error’)
# https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html#sklearn.preprocessing.OneHotEncoderpandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None)
# API :
# http://pandas.pydata.org/pandas-docs/stable/generated/pandas.get_dummies.html#pandas.get_dummies例子:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









