






IK分词器
本文分为简介、安装、使用三个角度进行讲解。
简介
倒排索引
众所周知,ES是一个及其强大的搜索引擎,那么它为什么搜索效率极高呢,当然和他的存储方式脱离不了关系,ES采取的是倒排索引,就是反向索引;常见索引结构几乎都是通过key找value,例如Map;倒排索引的优势就是有效利用Value,将多个含有相同Value的值存储至同一位置。
分词器
为了配合倒排索引,分词器也就诞生了,只有合理的利用Value,才会让倒排索引更加高效,如果一整个Value不进行任何操作直接进行存储,那么Value和key毫无区别。分词器Analyzer 通常会对Value进行操作:一、字符过滤,过滤掉html标签;二、分词,英文安装空格将单词分开,中文通常采取高级算法进行分词,显然IK在这方面是做的最好的中文分词;三、单词加工,将大小写全部转换为小写。
IK分词器
IK分词器,提供两种颗粒度拆分(ik_smart ,ik_max_word)
- ik_smart(最粗粒度拆分)
- 分割的粒度较小
- ik_max_word(最细粒度划分)
- 分割的力度较大
代码测试
使用kinana发送请求
POST /_analyze
{
"analyzer": "ik_smart",
"text":"我们一起吃饭"
}
//分词结果 我们 一起 吃饭
POST /_analyze
{
"analyzer": "ik_max_word",
"text":"我们一起吃饭"
}
//分词结果 我们 一起 一 起 吃饭
总结:明显最细粒度划分的切割力度更大
安装
官网下载即可,要和ES版本对应,放到ES 的plugins文件夹下
使用
IK支持自定义扩展词典和停用词典,扩展词典的意思就是,将一些非关键词,设置为关键词;停用词典就是将一些默认的关键词,设置为非关键词
如何配置扩展词典与停用词典
打开ik目录下config/IKAnalyzer.cfg.xml
这里需要写入两个文件名 随便起,后缀要dic。
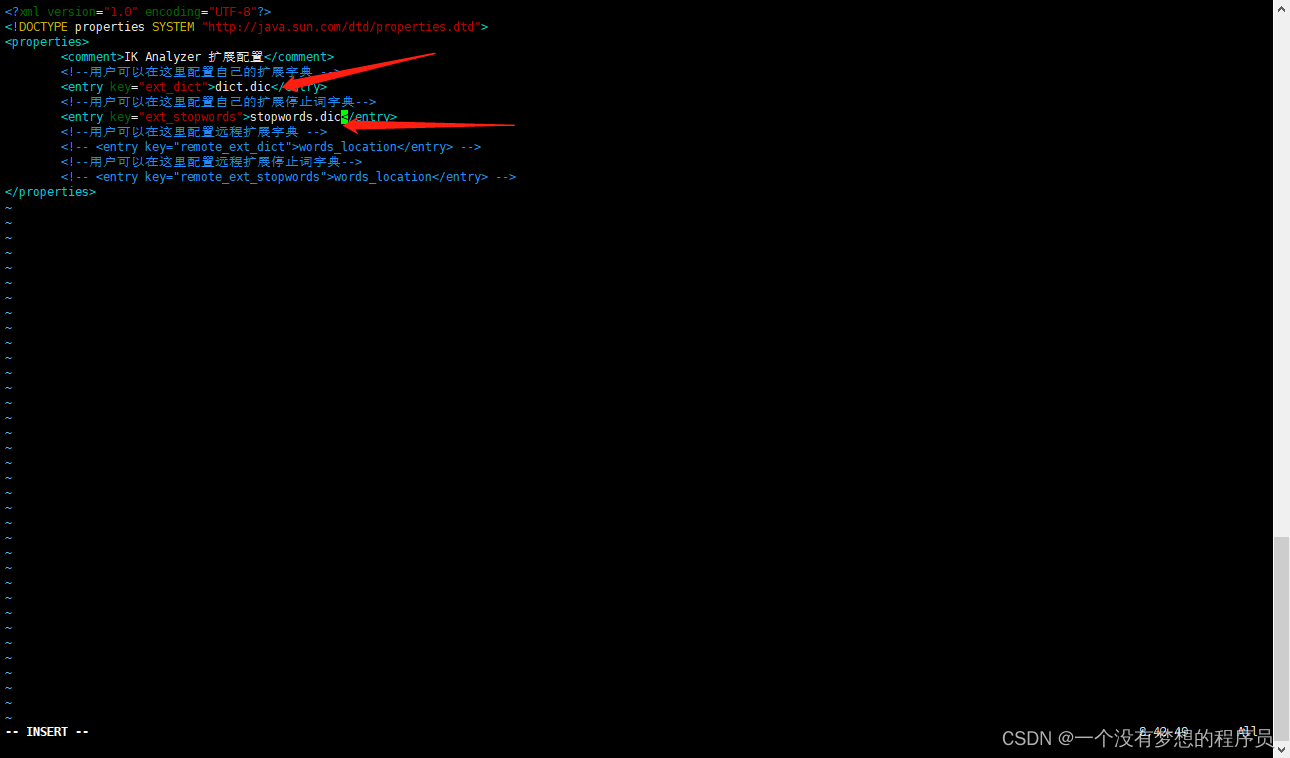
在config目录下 创建这两个文件 文档一行只可以写入一个值,具体格式如下

最后要重启ES服务 才可以生效
扩展词典测试
POST /_analyze
{
"analyzer": "ik_max_word",
"text":"李小八"
}
//此时的分词结果是 李 小 八
//我们把李小八这个词添加到扩展词典dict.dic后 分词结果只有李小八
停用词典测试
POST /_analyze
{
"analyzer": "ik_smart",
"text":"我们一起吃饭"
}
//此时分词结果为 “我们” “一起” ”吃饭“
//但当我们配置到stopwords.dic 添加吃饭,分词结果就会变成 ”我们“ ”一起“
// 停用词典是不会作为关键字被显示的














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









