






在数据表示方面,XML文档更加结构化。DOM在支持HTML的基础上提供了一系列的API,支持针对XML的访问和操作。利用这些API,我们可以从XML中提取信息,动态的创建这些信息的HTML呈现文档。处理XML文档,通常遵循“加载XML文档à提取信息à加工信息à创建HTML文档”的过程。下面的例子演示了如何加载并处理XML文档。
这个例子包含两个JS函数。loadXML()负责加载XML文档,其中既包含加载XML文档的2级DOM代码,又有实现同样操作的Microsoft专有API代码。需要提醒注意的是,文档加载过程不是瞬间完成的,所以对loadXML()的调用将在加载文档完成之前返回。因此,需要传递给loadXML()一个引用,以便文档加载完成后调用。
例子中的另外一个函数makeTable(),则在XML文档加载完毕之后,使用最后前介绍过的DOM应用编程接口读取XML文档信息,并利用这些信息形成一个新的table表格。
例子7 -- sample6_1.htm:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<title>无标题文档</title>
<script language="javascript">
function loadXML(handler) {
var url = "employees.xml";
if(document.implementation&&document.implementation.createDocument) {
var xmldoc = document.implementation.createDocument("", "", null);
xmldoc.onload = handler(xmldoc, url);
xmldoc.load(url);
}
else if(window.ActiveXObject) {
var xmldoc = new ActiveXObject("Microsoft.XMLDOM");
xmldoc.onreadystatechange = function() {
if(xmldoc.readyState == 4) handler(xmldoc, url);
}
xmldoc.load(url);
}
}
function makeTable(xmldoc, url) {
var table = document.createElement("table");
table.setAttribute("border","1");
table.setAttribute("width","600");
table.setAttribute("class","tab-content");
document.body.appendChild(table);
var caption = "Employee Data from " + url;
table.createCaption().appendChild(document.createTextNode(caption));
var header = table.createTHead();
var headerrow = header.insertRow(0);
headerrow.insertCell(0).appendChild(document.createTextNode("姓名"));
headerrow.insertCell(1).appendChild(document.createTextNode("职业"));
headerrow.insertCell(2).appendChild(document.createTextNode("工资"));
var employees = xmldoc.getElementsByTagName("employee");
for(var i=0;i<employees.length;i++) {
var e = employees[i];
var name = e.getAttribute("name");
var job = e.getElementsByTagName("job")[0].firstChild.data;
var salary = e.getElementsByTagName("salary")[0].firstChild.data;
var row = table.insertRow(i+1);
row.insertCell(0).appendChild(document.createTextNode(name));
row.insertCell(1).appendChild(document.createTextNode(job));
row.insertCell(2).appendChild(document.createTextNode(salary));
}
}
</script>
<link href="css/style.css" rel="stylesheet" type="text/css">
</head>
<body onLoad="loadXML(makeTable)">
</body>
</html>
供读取调用的XML文档 – employees.xml:
<?xml version="1.0" encoding="gb2312"?>
<employees>
<employee name="J.Doe">
<job>Programmer</job>
<salary>32768</salary>
</employee>
<employee name="A.Baker">
<job>Sales</job>
<salary>70000</salary>
</employee>
<employee name="Big Cheese">
<job>CEO</job>
<salary>100000</salary>
</employee>
</employees>
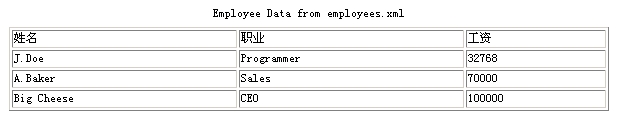
处理XML文档
脱离XML文档的AJAX是不完整的。在本部分未完成之前,有读者说AJAX改名叫AJAH(H应该代表HTML吧)比较合适。应该承认,XML文档在数据的结构化表示以及接口对接上有先天的优势,但也不是所有的数据都应该用XML表示。有些时候单纯的文本表示可能会更合适。下面先举个AJAX处理返回XML文档的例子再讨论什么时候使用XML。
7.5.1 、处理返回的XML
例子8 -- sample7_1.htm:
在这个例子中,我们采用之前确定的AJAX开发框架,稍微修改一下body内容和processRequest的相应方式,将先前的employees.xml的内容读取出来并显示。
body的内容如下:
<input type="button" name="read"
value="读取XML" onClick="send_request('employees.xml')">
processRequest()方法修改如下:
// 处理返回信息的函数
function processRequest() {
if (http_request.readyState == 4) { // 判断对象状态
if (http_request.status == 200) { // 信息已经成功返回,开始处理信息
var returnObj = http_request.responseXML;
var xmlobj = http_request.responseXML;
var employees = xmlobj.getElementsByTagName("employee");
var feedbackStr = "";
for(var i=0;i<employees.length;i++) { // 循环读取employees.xml的内容
var employee = employees[i];
feedbackStr += "员工:" + employee.getAttribute("name");
feedbackStr +=
" 职位:" + employee.getElementsByTagName("job")[0].firstChild.data;
feedbackStr +=
" 工资:" + employee.getElementsByTagName("salary")[0].firstChild.data;
feedbackStr += "/r/n";
}
alert(feedbackStr);
} else { //页面不正常
alert("您所请求的页面有异常。");
}
}
}
运行一下,看来效果还不错:















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









