









Sphinx 在网站应用中的服务架构设计
- Sphinx
- Linux
- Mysql
- Web Application
Sphinx 简单介绍
- 介绍
Sphinx 是一个基于 SQL 的全文检索引擎,可以给 Mysql、PostgreSQL 做检索,提供比数据库更加专业的搜索功能。Sphinx 的搜索API接口支持 PHP,Python,Ruby,等。Sphinx 单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Sphinx创建索引的速度为:创建100万条记录的索引只需 3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒 主要特性
- 高速索引
- 高速搜索
- 支持分布式搜索
- 提供从Mysql 内部的插件式存储引擎上搜索
- 采用 UTF-8 字符集
- 支持 Windows/Linux/MacOX
使用场景
如果数据库的数据量不是很多,百万级的数据,可以采用数据库索引来进行检索,但是对于上千万的数据量的话就用数据库直接检索的效率就会有所下降,特别对于采用分库分表的数据库设计,如果要检索非主键的字段的话,将会非常麻烦。
比如用户表 user,用户量大的时候,我们一般会采用分表的方式来提高应用的访问性能。user_0 ~ user_63 ,总共 64 张表,user_id 作为 主键
表结构如下。
user_id name password age
int char(100) char(32) int
如果知道 user_id = 65,那我们很容易找到用户的信息, 65 % 64 = 1,那就在 user_1 表中,采用 select * from user_1 ….
但是如果我想检索名字叫 “phachon” 的用户,这个就比较麻烦了,最笨的办法就是每一张表都去查找 select * from user_* where name LIKE %phchon% ,这样要循环 64 次,再将数据合并起来,这样显然是不可行的,数据库的开销太大,造成应用程序的性能下降。
Sphinx 就可以帮我们解决上面所说的问题。当然,Sphinx 可以应用的场景很多,上面只是其中的一种。
Sphinx 在网站应用程序中的应用架构设计
以下是最近在工作中使用 Sphinx 来进行后台数据检索的应用架构设计
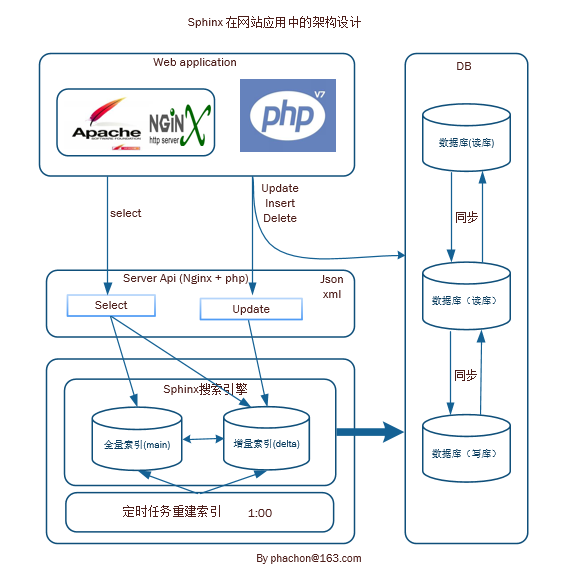
web application 应用程序层 select 操作只用请求 Server Api 层的 select 接口;update/insert/delete 操作先操作数据库再请求 Server Api 的 update 更新接口。
Server Api 层通过 Nginx + php 连接 Sphinx 客户端,主要提供了两个接口 select 查询接口和 update 更新接口。select 接口需要查询全量(main)索引和增量(delta)做索引的数据,取其数据的交集才是真正需要的数据。
Sphinx 客户端建了两个索引,全量索引(main)和增量索引(delta),每天凌晨 1 点通过脚本进行定时任务重建索引,如果插入或者修改量很低的话,重建索引的频率可适当调整。应用层更新操作可通过消息队列来异步实现。
DB 数据库层读库和写库及时同步保证数据的一致性。
Server Api 层连接 Sphinx 客户端的可使用 SphinxClinet 类或者 foolz/sphinxql-query-builder 类来实现。
Sphinx 配置
Sphinx 在 Linux 下的安装可参考之前写的一篇文章《Sphinx 在Linux下的安装与基本配置》















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









