DataX实现Mysql与Oracle、HDFS、Postgres的数据同步
第1章 Demo设计
架构图:
Mysql — data —> HDFS HDFS — data —> Mysql Oracle — data —> Mysql Postgresql — data —> Hive 第2章 快速部署
2.1 官方地址
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
2.2 前置要求
Linux ( Centos7.6 ) JDK(1.8以上,推荐1.8) Python(推荐Python2.6.X) 2.3 安装
1)将下载好的datax.tar.gz上传到服务器的/opt/software
1
[root@node1 software]# ll
2)解压datax.tar.gz到/opt/module
1
[root@node1 software]$ tar -zxvf datax.tar.gz -C /opt/module/
3)运行自检脚本
1
[root@node1 bin]$ cd /opt/module/datax/bin/
第3章 DEMO案例
3.1 DataX示例一:读Mysql数据到HDFS
3.1.1 查看官方模板
1
[root@node1 ~]$ python /opt/module/datax/bin/datax.py -r mysqlreader -w hdfswriter
如果你的数据库没有设置密码,那么就需要修改源码,下载dataX源码,做如下修改,并打成jar包datax-common-0.0.1-SNAPSHOT.jar :
将打好的jar包替换datax/lib/datax-common-0.0.1-SNAPSHOT.jar
3.1.2 准备数据
1)在Mysql中创建alert_current表,导入测试数据
3.1.3 编写配置文件
1
[root@node1 job]# vi Mysql2Hdfs.json
3.1.4 执行任务
[root@node1 datax]# bin/datax.py ./job/Mysql2Hdfs.json
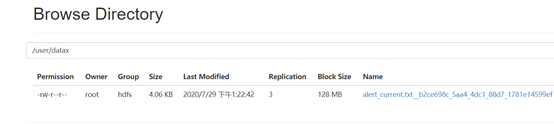
3.1.5 查看HDFS
注:HdfsWriter实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名。
3.2 DataX示例二:读HDFS中数据到Mysql
基于3.2案例结果HDFS中的数据,导出到Mysql的alert_current_copy表中
3.2.1 编写配置文件
1
[root@node1 job]# vi Hdfs2Mysql.json
3.2.1 查看运行结果
查看Mysql数据库的alert_current_copy表
3.3 DataX示例三: Oracle同步数据到Mysql
3.3.1准备工作
1)192.168.20.2 节点Oracle中选择稍微大一点的LineItem表(719M),查看数据量 select count(*) from lineitem;
2)192.168.20.1 节点Mysql中datax_test库中创建表LINEITEM
1
create table LINEITEM (
3.3.2 编写配置文件
1
[root@node1 job]# vi oracle2Mysql.json
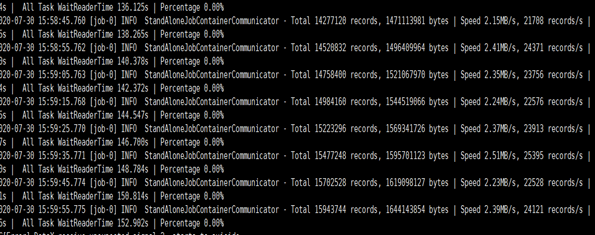
3.3.3 运行并查看结果
1
[root@node1 datax]# bin/datax.py ./job/oracle2Mysql.json
速度仅有2M/S,采取以下优化措施:
结果总用时917s:
Jvm调优:
1
[root@node1 bin]# vi datax.py
3.4 DataX示例四: Postgres同步数据到Hive
直接上配置文件:
1
{<!-- -->
小结:
1、本次示例的运行主机是32G -8核虚拟机,优化程度有限。






























 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









