







(1). 针对附件“HW3.txt”中的600个文档(每行表示一个document,文档ID为1至600)
(i)使用jieba中文分词(https://pypi.org/project/jieba/)或其他中文分词工具进行分词;
(ii)统计600个文档中的token的总数和term的总数;
(iii)构建倒排索引,并输出以下七组查询的文档ID:“迁移”,“迁移学习”,“推荐”,“深度学习”,“隐私”,“跨领域”,“跨域”。
代码截图和详细的文字说明:
- 读取文档
# 读取文档,并按行分隔
doc = open('HW3.txt', 'r', encoding='gbk').read().splitlines()
- 计算token,term
# 添加自定义词库(可选)
for path in os.listdir('dictionary'):
jieba.load_userdict('dictionary/' + path)
# 计算token,term数量
# token使用list存储,term使用set存储(可去重)
token, term = list(), set()
for sentence in doc:
# 利用jieba进行分词 返回分词后的结果
seg_list = list(jieba.cut(sentence, cut_all=False))
token.extend(seg_list)
term.update(seg_list)
print('len(token) =', len(token))
print('len(term) =', len(term))
- 建立倒排索引
hashtable = {}
for index, sentence in enumerate(doc):
# 利用jieba进行分词 返回分词后的结果
# 使用精确模式
for word in jieba.cut(sentence, cut_all=False):
if word in hashtable:
hashtable[word].append(index+1)
hashtable[word][0] += 1
else:
hashtable[word] = [1, index+1]
- question3展示
query_index = pd.DataFrame(columns=['term', 'doc.freq', 'postings list'])
query = ['迁移', '迁移学习', '推荐', '深度学习', '隐私', '跨领域', '跨域']
for term in query:
if term in hashtable:
query_index = query_index.append(
{'term': term, 'doc.freq': hashtable[term][0], 'postings list': hashtable[term][1:]}, ignore_index=True)
else:
query_index = query_index.append(
{'term': term, 'doc.freq': 0, 'postings list': []}, ignore_index=True)
display(query_index)
(i)使用jieba中文分词(https://pypi.org/project/jieba/)或其他中文分词工具进行分词
首先读取文档内容
# 读取文档,并按行分隔
doc = open('HW3.txt', 'r', encoding='gbk').read().splitlines()
for sentence in doc[:10]:
print(sentence)

然后调用jieba.cut函数进行分词
jieba分词0.4版本以上支持四种分词模式:
- 精确模式:试图将句子最精确地切开,适合文本分析;
- 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
- paddle模式:利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。
精确模式:

全模式:

搜索引擎模式:

paddle模式:(m1 macbook暂不支持paddlepaddle安装,故没有测试)
可以看出,全模式的切词是最粗糙的,将所有的词汇都进行了返回。主要有以下几个问题:
- 未结合语境,容易有歧义:协同过滤----> 协同+同过+过滤
- 不了解词汇:鲁棒----> 鲁+棒
精确模式与搜索引擎模式可以结合具体需求进行选择。
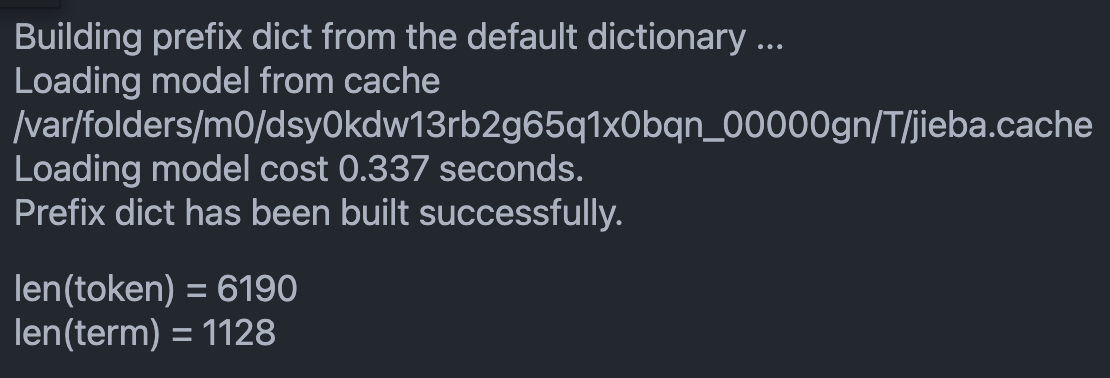
(ii)统计600个文档中的token的总数和term的总数
经过上方的测试,此处选择精确模式进行分析。
将分解出的词汇分别存入list和set。set会自动进行去重,达到计算term的目的
token数量:6190
term数量:1128
# 添加自定义词库(可选)
for path in os.listdir('dictionary'):
jieba.load_userdict('dictionary/' + path)
# 计算token,term数量
# token使用list存储,term使用set存储(可去重)
token, term = list(), set()
for sentence in doc:
# 利用jieba进行分词 返回分词后的结果
seg_list = list(jieba.cut(sentence, cut_all=False))
# print('--------------------------------------------------------------')
# print('sentence:', sentence)
# print('seg_list:', seg_list)
token.extend(seg_list)
term.update(seg_list)
print('len(token) =', len(token))
print('len(term) =', len(term))
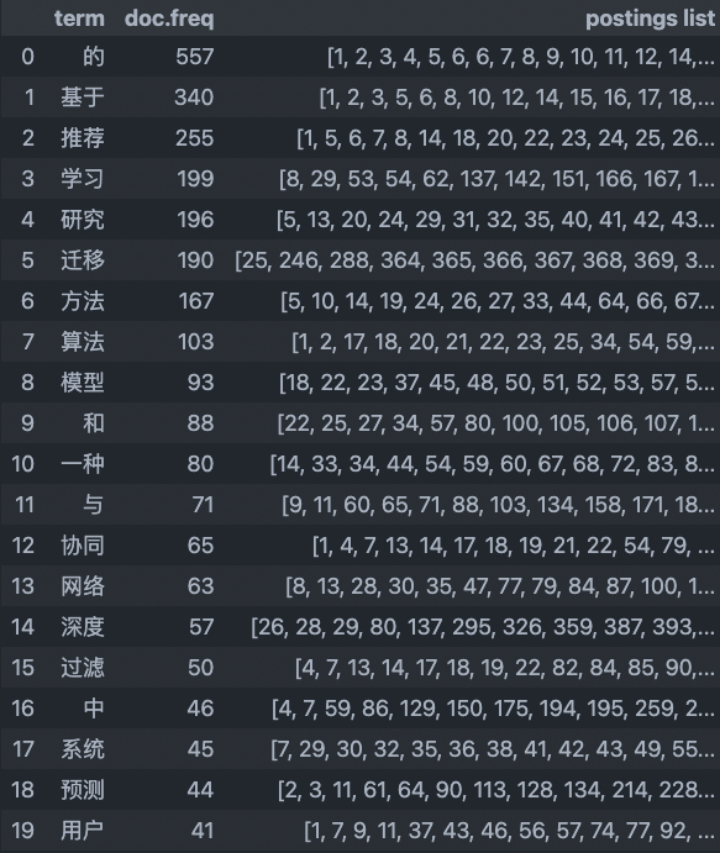
(iii)构建倒排索引,并输出以下七组查询的文档ID:“迁移”,“迁移学习”,“推荐”,“深度学习”,“隐私”,“跨领域”,“跨域”
a. 建立如下数据结构:
建立一个哈希表,key值为字符串,value值为列表。
其中key值中存储所有单词,并作为哈希表的索引;value值中第1位记录倒排索引长度,第2位开始记录每个单词出现文章的序号。

b.遍历token列表:
a) 如果单词出现过,就将文章序号添加到列表尾部,并且长度加一。
b) 单词第一次出现时,将单词加入哈希表。
最终得到了如下的倒排索引表:
同时也对需要进行搜索的单词进行了筛选:
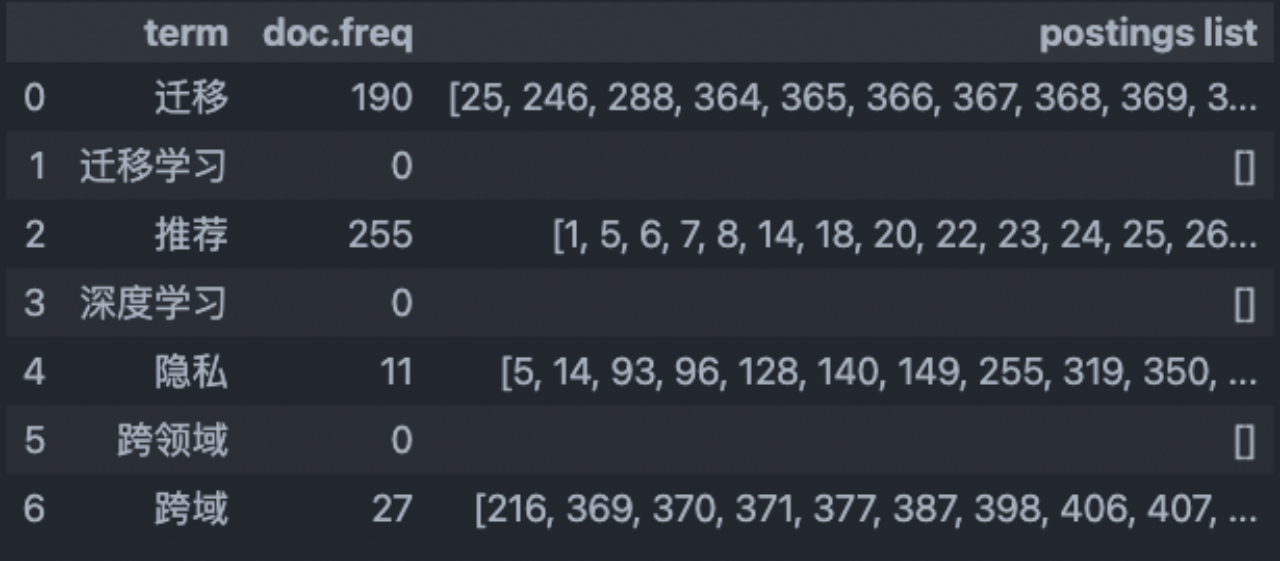
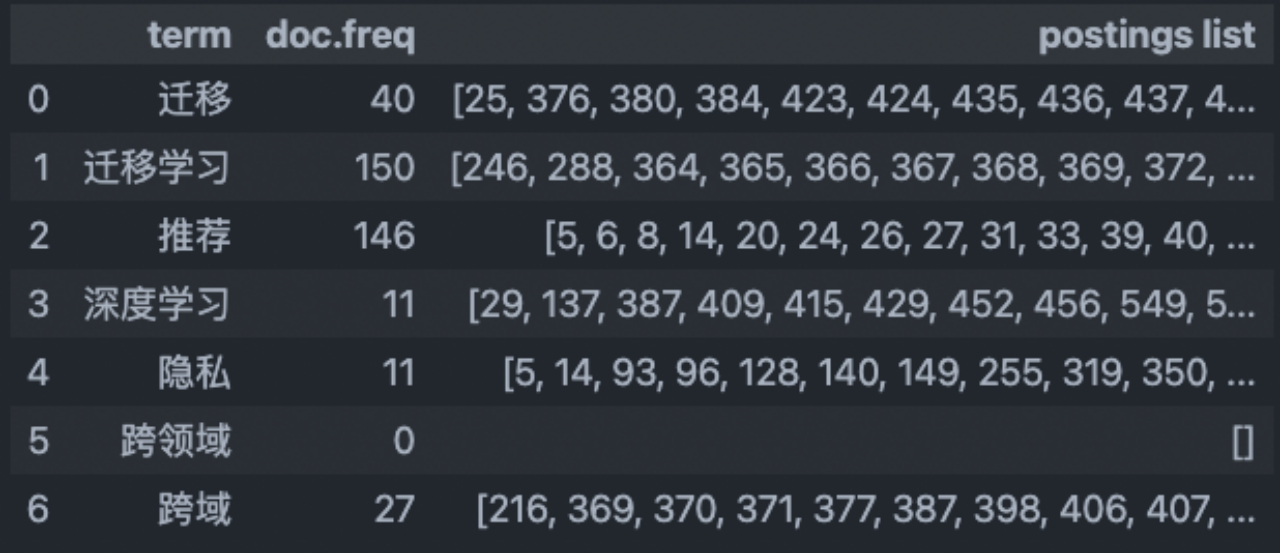
可以看到jieba对于计算机专业词汇的分割,并不是十分了解。因此我又尝试了许多其他分词库,包括thulac,pkuseg,FoolNLTK等,发现结果大同小异。最终,我觉得手动添加一些计算机专业词汇进入jieba。
在网站:https://github.com/ylfeng250/cs-dict中,有许多已经整理好的计算机专业词汇。

使用jieba.load_userdic()添加自定义词库
# 添加自定义词库(可选)
for path in os.listdir('dictionary'):
jieba.load_userdict('dictionary/' + path)
最终,倒排索引搜索结果如下:
(2). 阅读教材《Introduction to Information Retrieval》第97页Figure 5.8中所描述的采用VB的编码和解码过程(VB encoding and decoding),并用Java语言或其他常用语言实现该算法。要求在三个数字(113,309,720)上验证实现的算法的正确性。
代码截图(不要复制源代码,请用截图的方式)和详细的文字说明:
编码过程:将数据循环除以128取余并将十进制结果记录,将延续位变为1并将8位二进制字符串结果记录。
解码过程:将二进制字符串变成十进制,将延续位改为0。
- VB编码单数字(输入数字,返回VB编码)
def VBEncodeNumber(num):
# 存储每个字节的十进制编码(0-127)
bytes = []
while True:
bytes.insert(0, num %128)
if num < 128:
break
num = num // 128
# 将延续位变为1
bytes[-1] += 128
# # 展示二进制编码
# print(['{:08b}'.format(x) for x in bytes])
return bytes
- VB编码数字流(输入数字流,对数字一次编码,并返回字节流)
def VBEncode(numbers):
# 字节流
bytestream = []
# 将每个数字进行VB编码,并存入字节流
for n in numbers:
bytes = VBEncodeNumber(n)
bytestream.extend(bytes)
return bytestream
- VB解码字节流(输入数字流,返回解码后的数字流)
def VBDecode(bytestream):
numbers = []
n = 0
# 读入字节流,并解析出每个数字
for i in range(len(bytestream)):
# 大于128说明数字有延续位,结束
if bytestream[i] < 128:
n = 128*n + bytestream[i]
else:
n = 128*n + bytestream[i] - 128
numbers.append(n)
n = 0
return numbers
注:在python中,无法对于数字的数据类型进行指定,因此在代码中不再进行特别指定。如果使用C/C++,可以使用unsigned char来存储(0-255),刚好一个字节的大小,可以尽量节省存储空间。
第1个数字113上的运行结果截图和详细的文字说明:
原始: num = 113
十进制: VBEncodeNumber10(num) = [241]
二进制: VBEncodeNumber2(num) = [‘11110001’]
解码: VBDecode(VBEncodeNumber2(num)) = [113]
第2个数字309上的运行结果截图和详细的文字说明:
原始: num = 309
十进制: VBEncodeNumber10(num) = [2, 181]
二进制: VBEncodeNumber2(num) = [‘00000010’, ‘10110101’]
解码: VBDecode(VBEncodeNumber2(num)) = [309]
第3个数字720上的运行结果截图和详细的文字说明:
原始: num = 720
十进制: VBEncodeNumber10(num) = [5, 208]
二进制: VBEncodeNumber2(num) = [‘00000101’, ‘11010000’]
解码: VBDecode(VBEncodeNumber2(num)) = [720]
在数字流[113,309,720]上的运行结果截图和详细的文字说明:
原始: nums = [113, 309, 720]
十进制: VBEncode(nums) = [241, 2, 181, 5, 208]
二进制: VBEncode(nums) = [‘11110001’, ‘00000010’, ‘10110101’, ‘00000101’, ‘11010000’]
解码: VBDecode(VBEncode(nums)) = [113, 309, 720]
(3). 阅读教材《Introduction to Information Retrieval》第98-99页(Section 5.3.2)中所描述的采用Gamma codes的编码和解码过程(encoding and decoding of Gamma codes),并用Java语言或其他常用语言实现该算法。要求在三个数字(113,309,720)上验证算法的正确性。
代码截图(不要复制源代码,请用截图的方式)和详细的文字说明:
编码过程:将数据转化为二进制,去除首位得到偏移量。对偏移量的长度进行一元编码,gammar编码最终为两者相连。
解码过程:获取第一次出现0的位置,获取偏移部分,首位添一,转换为十进制。
- gammar编码数字流
def GammarEncode(numbers):
# 根据数字流构成gamma编码字节流
bytestream = ''
for n in numbers:
bytes = gammarEncodeNumber(n)
bytestream += bytes
return bytestream
- gammar编码单数字
def gammarEncodeNumber(num):
# num转化为二进制,去掉第一位的1,构成offset
offset = bin(num)[3:]
# 根据offset计算长度,构成一元编码
length = '1' * len(offset) + '0'
# 构成gamma编码
gammarCode = length + offset
return gammarCode
- gammar编码解码(根据数字流,返回解码后的字节流)
def gammarDecode(bytestream):
numbers = []
i = 0
# 读入字节流
while i < len(bytestream):
length = 0
# 找到第一个0
while bytestream[i] != '0':
i += 1
# 计算1的长度,即offset的长度
length += 1
# 提取offset
offset = bytestream[i + 1: i + length + 1]
# 给offset首位添1,并转换为十进制
numbers.append(int('1'+offset, 2))
i += length + 1
# 返回数字流
return numbers
第1个数字113上的运行结果截图和详细的文字说明:
num = 113
gammarEncodeNumber(num) = 1111110110001
gammardecode(gammarEncodeNumber(num)) = [113]
第2个数字309上的运行结果截图和详细的文字说明:
num = 309
gammarEncodeNumber(num) = 11111111000110101
gammardecode(gammarEncodeNumber(num)) = [309]
第3个数字720上的运行结果截图和详细的文字说明:
num = 720
gammarEncodeNumber(num) = 1111111110011010000
gammardecode(gammarEncodeNumber(num)) = [720]
在数字流[113,309,720]上的运行结果截图和详细的文字说明:
nums = [113, 309, 720]
gammarEncode(num) = 1111110110001111111110001101011111111110011010000
gammardecode(GammarEncode(nums)) = [113, 309, 720]


















 1698
1698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











