






Florence:计算机视觉的一个新的基础模型
基础模型:
基础模型的术语首次被引入指的是任何从大规模数据中训练的模型 ,这些模型能够被适应 (例如微调)到广泛的下游任务 。由于其令人印象深刻的性能和泛化能力,基础模型变得很有前途。
由于视觉理解的多样性 ,我们将计算机视觉的基础模型重新定义为一个预训练模型及其适配器 , 用于解决这个时空模态空间中的所有视觉任务, 具有可迁移性 ,如零/少样本学习和完全微调等。
一、创新点
现有的视觉基础模型,如CLIP、ALIGN等,主要侧重于将图像和文本映射到一种跨模态的共享表征。
Florence则将表征进行了拓展,不仅拥有从粗略(场景)到精细(对象)的表征能力,还将视觉能力从静态(图像)扩展到动态(视频),从RGB图像扩展到多模态(文字、深度信息)。
通过整合图像-文本数据的通用视觉语言表示能力,Florence可以轻松适用于各种计算机视觉任务,如分类、目标检测、VQA、看图说话、视频检索和动作识别,在多种类型的迁移学习中均表现出色。
二、方法

1. 数据集的选取
利用互联网上公开的大量图像-文本数据,微软构建了FLD-900M(FLorenceDataset)数据集。
FLD-900M包含了9亿图像-文本对,970万个独特的查询,总共75亿个标记,通过一个程序化的数据整理管道,并行处理大约30亿张互联网图像及其原始描述得到,并进行了严格的数据过滤以确保数据相关性和质量。
2. 基于Transformer的预训练模型
Florence预训练模型使用双塔结构:一个12层的Transformer作为语言编码器,类似于CLIP,和一个分层的视觉Transformer作为图像编码器。
分层的视觉Transformer采用的是一个经过修改的Swin Transformer,具有卷积嵌入功能,名为CoSwin Transformer。
Florence使用具有全局平均池的CoSwin Transformer来提取图像特征。在图像编码器和语言编码器的顶部添加了两个线性投影层,以匹配图像和语言特征的尺寸。
Florence预训练模型总共有893M的参数,包括有256M参数的语言Transformer和有637M参数的CoSwin-H Transformer,需要用512个NVIDIA A100 GPU训练10天。
3. 统一的图像-文本对比学习
CLIP隐式地假设了每个图像-文本对都有其独特的标注,其他图像会被认为是负样本。然而,在实际的网页数据中,多个图像可能会对应相同的标注。
其中,FLD-900M就包含了3.5亿个这种类型的图像-文本对。在对比学习中,所有与相同文本相关的图像都可以被视为正样本对。
为此,本文决定采用统一图像-文本对比学习(UniCL),其中Florence在图像-标签-描述空间中被预训练。
图像-标签空间的统一学习将两种流行的学习范式统一起来,将图像映射到标签上以学习辨别性的表征(即监督学习),并给每个描述分配一个独特的标签以进行语言-图像预训练(即对比学习)。
实验表明,具有丰富内容的长篇语言描述比短篇描述(如一两个词)更有利于图像-文本表征学习,微软通过生成提示模板的方式来丰富描述,并作为数据的补充。
4. V+L(Vision+Language tasks)表征学习
在视觉问题回答(VQA)和图像标注方面,细粒度的表征(即对象级别)也是必不可少的。
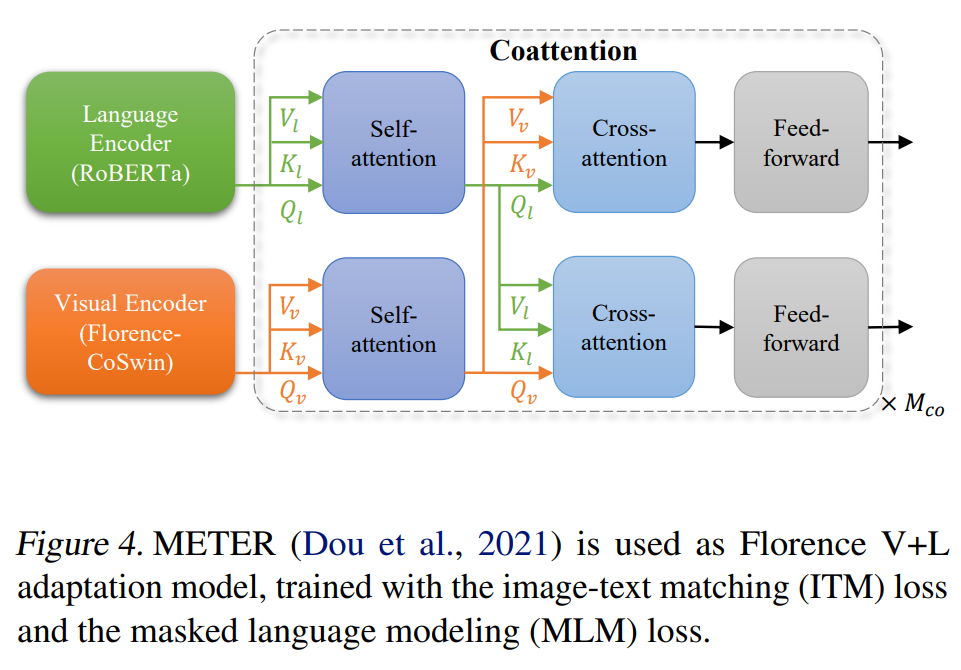
因此,在Florence的V+L(Vision+Language tasks)适应模型中,研究人员用预训练的CoSwin和预训练的Roberta作为语言编码器,以及METER作为adapter。
研究人员将上述两种模式融合在一起,用基于coattention的Transformer学习上下文表征。
共同注意力模型可以将文本和视觉特征分别送入两个Transformer,每个Transformer的顶层编码层包括一个自注意力块、一个交叉注意力块和一个前馈网络块。
训练时,先用图像-文本匹配损失和掩码语言建模损失来训练模型。然后,在下游的VQA任务上对模型进行微调。
三、实验结果

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









