






背景
- 搞了个很长的题目,原因是看了英特尔新发布了ultra2 系统。CPU,CPU、GPU、NPU啥都有,加上内存整合在了一个SoC芯片上,而且低功耗条件下的推理性能“可圈可点”,感觉有点心动——玩不起大算力还玩不起低功耗么,而且这个思路实际苹果M系列芯片也在用(但苹果太贵了),感觉提升低功耗推理能力,会是一个未来趋势。于是搞了一台258V+32G内存的轻薄本,想试试效果。
- 看了看B站视频,都在用stable diffusion和剪映做实验,结论是前者改吧改吧能跑英特尔的GPU、后者跑NPU、而且除了剪映,几乎没有应用能用到NPU,评论区都觉得这个东西没用。
- 英特尔出了自己的推理框架OpenVino,这个肯定支持自家的各种U,我就想如果基于这个东西,是否能找个例子,实现各种U混合跑的例子呢?至少看看潜力。
- 前端时间正好玩Deep live Cam ,就是那个人均马斯克的变脸应用,就是这个:
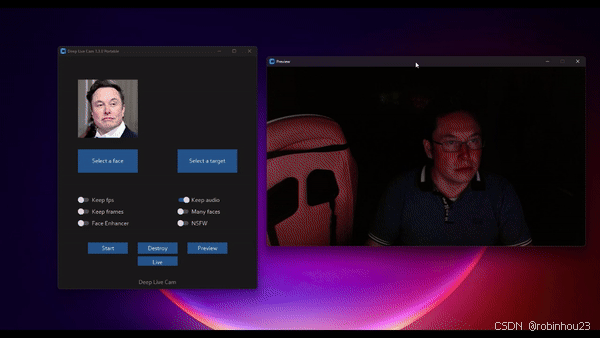
这个在CUDA118+英伟达显卡上跑起来很容易,官方教程很详细了。
我也试过在CPU上跑,卡的一批。条件所限,我用的最强的CPU是i7-13700KF+64G内存的台式机,明显的卡,然后在第十一代和十二代低功耗CPU的笔记本也试过,打开摄像头之后,几乎是10秒刷新一帧。 - 这个应用也提供了openvino下的跑法,但是教程太糙了,实际也是基于openvino跑CPU,其他的U都用不起来,和直接用CPU跑没有区别。
- 我这个记录,就是终于调通了openvino下的3U一起跑,感觉很流程了,画面基本是实时的了,性能监控大概是这个效果:
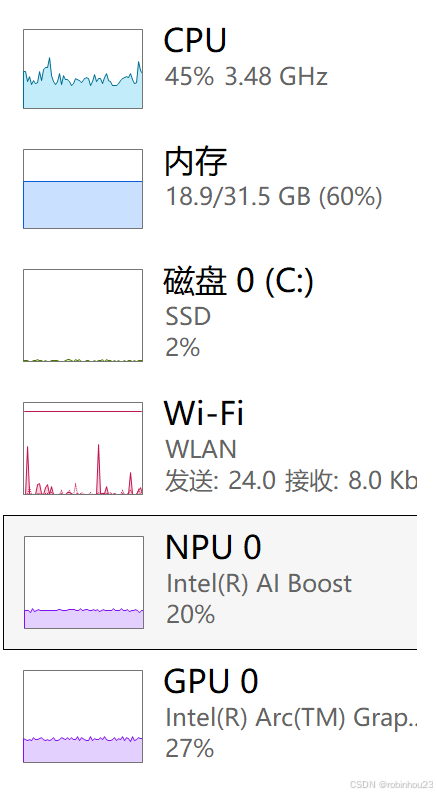
如果纯跑CPU,那么CPU会跑到100%,GPU和NPU没动静,而且效果卡,这个就不放图了。
准备步骤
- 根据官网步骤做准备,建议基于conda。
- 需要Visual Studio 2022 Runtimes (Windows),编译insightface用。
- 需要FFMPEG:建立了虚拟环境后可以,conda install FFmpeg,或者用别的方法按上就行。
- git clone这个项目到合适的位置。
- 进入虚拟环境,进入项目目录 pip install -r requirements.txt
- 提前下载模型,放到models目录下面,注意看官网的说明:
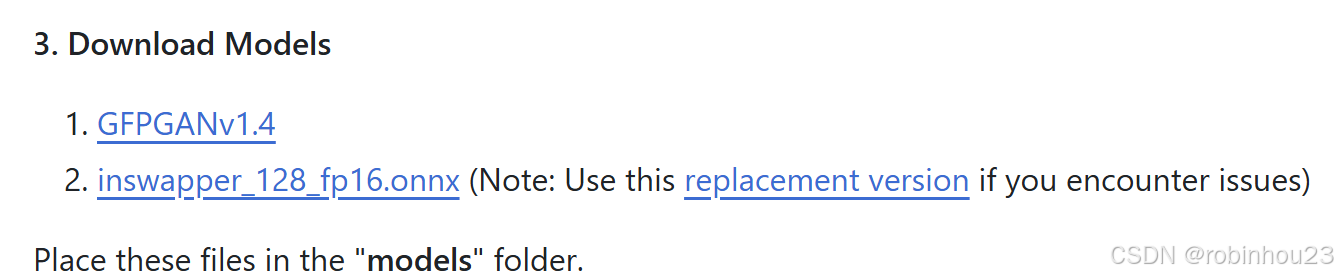
- 首先,inswapper建议这个和“replacement version”都下载。
- 其次,还需要提前下载一个:parsing_parsenet.pth,自己搜出来提前下载好,否则已启动又会遇到各种网络问题报错。
下面就是趟出来的东西了,只要是英特尔的ultra系列处理器,都可以试试:
7. 重新部署openvino和onnxruntime的版本:
pip install openvino==2024.3.0
pip install onnxruntime-gpu==1.19.0
pip uninstall onnxruntime onnxruntime-openvino
pip install onnxruntime-openvino==1.19.0
- 其实就是对应上openvino、onnxruntime-gpu和onnxruntime-openvino这三者的版本。
- 我自己猜,几个库的的大概关系是:onnxruntime-gpu提供了一个调用外部“GPU”等设备做provider的框架,onnxruntime-openvino基于这个框架提供了真正的openvino调用接口,openvino的库则提供实际驱动硬件设备的dll文件。
- onnxruntime-openvino的github页面的release页上,能看到它和openvino的版本对应关系,但没说onnxruntime-gpu也要严格对应。但如果三者版本不对齐,则运行的时候报一些错,然后就直接跑CPU了,相当于这个openvino没用上。
- 还有就是哪个uninstall的步骤,也最好加上,否则可能不认openvino的启动参数。
这个Deep live Cam在官网上列举了一大堆支持的推理框架,包括英伟达、苹果、AMD、微软和英特尔,但我试了DirectML和Openvino,给的教程都不太行。。。
改代码
1
在modules\globals.py ,在头部合适的地方加上:
import onnxruntime.tools.add_openvino_win_libs as utils
utils.add_openvino_libs_to_path()
如果不加这几句代码,onnxruntime会找不到openvino的dll,然后报一些126啥的错误,然后直接跑CPU。
2
找到modules\processors\frame\face_swapper.py,40行左右: get_face_swapper()函数,改大概43行,模型的名字为inswapper_128.onnx:
model_path = resolve_relative_path('../models/inswapper_128.onnx')#_fp16
还是get_face_swapper()函数,大概第44行,“FACE_SWAPPER = ……”语句,加一个provider_options参数:
FACE_SWAPPER = insightface.model_zoo.get_model(model_path,
providers=modules.globals.execution_providers,
provider_options= [{'device_type':'GPU'}])
provider_options选项的可选内容参见:OpenVINO-ExecutionProvider,往下拉有个“Summary of options”的表。
注意所有选项值是大小写敏感的,要大写!链接这个表里都是小写,这个不对,会报错,要写CPU、FP16这种。
此外,NPU只支持FP16,在face_swapper中,如果provider_options指定NPU,效果是乱套的(但不报错)。
3
在modules\face_analyser.py中,大概22行修改:
FACE_ANALYSER = insightface.app.FaceAnalysis(name='buffalo_l',
providers=modules.globals.execution_providers,
provider_options=[{'device_type': 'NPU'}] )
其实就是也加一个provider_options选项,指定了NPU。这里也可以试试GPU,但有多种搞法,有的好使有的不行,这里不再一一列举了。
运行:
python run.py --execution-provider openvino
不出意外就能看到流畅的效果了。提供个素材,祝大家都能变彦祖。

小结
改代码步骤的2到3,总共其实就是改三个东西:
- 一个是用哪个换脸模型(inswapper),FP16的还是另一个,差别应该在精度上,但我没仔细看。
- 另一个是检测人脸和换脸用哪个设备跑,这里检测人脸用NPU、换脸用GPU,但CPU也在起作用,这个从之前的系统监控图能看出来。
这三个东西的组合我试了好几种方案,最后大概有两三种能在ultra轻薄本上流畅跑,写出来这种是最顺的。体现了ultra 2三种U的能力。
目前的结论
- ultra2代这个258v,B站测评这个架构玩一些大游戏也能差强人意,而且兼顾体积和续航,这个很厉害了。
- OpenVino+ultra系列芯片感觉未来可期,至少这个例子能看懂三个U各自发挥作用的潜力——从监控图来看,在默认设置下三个U都是轻载运行,还有潜力。低功耗的高性能推理应该是能让AIGC普及的重要推手。
- NPU这个东西还需要继续研究,看看适合干啥,比如为啥换脸的时候只能用GPU,不能用NPU,也可能是我哪里没搞对吧。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









