










一、简介
Pandas DataFrame是带有标签轴(行和列)的二维大小可变的,可能是异构的表格数据结构。算术运算在行和列标签上对齐。可以将其视为Series对象的dict-like容器。它也是Pandas的主要数据结构。
二、常用函数
1. dataframe.columns
(1)作用:返回给定Dataframe的列标签组成的列表。
(2)语法:
DateFrame.columns
param:None
return:The column labels of the DataFrame.(列名)
(3)示例:
首先创建DataFrame类型数据。# 导入pandas包
import pandas as pd
# 创建DataFrame
df = pd.DataFrame({'Weight':[45, 88, 56, 15, 71],
'Name':['Sam', 'Andrea', 'Alex', 'Robin', 'Kia'],
'Age':[14, 25, 55, 8, 21]})
# 创建索引
index_ = ['Row_1', 'Row_2', 'Row_3', 'Row_4', 'Row_5']
# 设置索引
df.index = index_
# 打印 DataFrame
print(df)
创建好的DataFrame数据如下图所示。

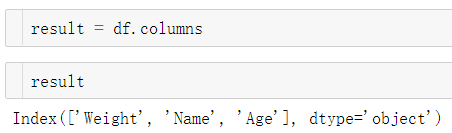
然后使用DataFrame.columns属性返回给定 DataFrame 的列标签列表。给定DataFrame的所有列标签如下所示。
result = df.columns
print(result)
2. len(DateFrame)
(1)作用:返回DateFrame中的总行数,不包括表头一行。
3. dataframe.rename()
(1)作用:修改Dataframe数据的某行名和某列名。
(2)语法:
dataframe.rename(columns,index,axis,inplace)
columns:列名
index:行名
axis:指定坐标轴
inplace:是否替换,默认为False。inplace为False时返回修改后结果,变量自身不修改。inplace为True时返回None,变量自身被修改。
(3)示例:
>>> import pandas as pd
>>> df
A B
0 1 4
1 2 5
2 3 6
# 方法一:不用axis修改
>>> df.rename(columns={"A": "a", "B": "c"}) # 修改columns。inplace未设置,返回修改后的结果
a c
0 1 4
1 2 5
2 3 6
>>> df # inplace未设置,默认为false,则df自身不被改变
A B
0 1 4
1 2 5
2 3 6
>>> df_re=df.rename(index={0:"0a",1:"1a"}) # 同样的方式修改行名
>>> df
A B
0 1 4
1 2 5
2 3 6
>>> df_re
A B
0a 1 4
1a 2 5
2 3 6
>>> df_re=df.rename(columns={"A": "a", "B": "c"},index={0:"0a",1:"1a"}) # 同时修改行名和列名
>>> df_re
a c
0a 1 4
1a 2 5
2 3 6
# 方法二:用axis修改,只修改行名列名之一时等价,无法同时修改
>>> df.rename({1: 2, 2: 4}, axis='index') # 修改行名
A B
0 1 4
2 2 5
4 3 6
>>> df.rename(str.lower, axis='columns') # 列名大写变小写
a b
0 1 4
1 2 5
2 3 6
# 让inplace为True
>>> df_re=df.rename(columns={"A": "a", "B": "c"},inplace=True)
>>> print(df_re) # inplace为True时返回空值
None
>>> df # 自身被修改,可对照上面进行理解
a c
0 1 4
1 2 5
2 3 6
4. dataframe.to_csv()
(1)作用:将dataframe格式的数据写入到csv文件中。
(2)语法:该函数有很多参数,完整参考 官方说明文档,常用的几个参数如下:
path_or_buf:文件路径,默认为None
sep:分隔符,默认为“,”
index:是否要行索引,默认为True,写行索引
encoding:csv文件的编码方式,默认为utf-8
5. dataframe.fillna()
(1)作用:用来填充缺失数据。
(2)语法:
inplace:是否替换,默认为False。inplace为False时返回修改后结果,变量自身不修改。inplace为True时返回None,变量自身被修改。
6. dataframe.values()
(1)作用:返回dataframe中的所有值或者单独取出某一列的值。
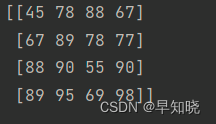
(2)示例:df如下。

用法一:将df转化为列表。
list = df.values
print(list)
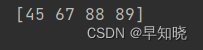
用法二:获取某一列数据。
print(df['英语'].values)
Reference:
1.https://blog.csdn.net/weixin_44852067/article/details/122238481
2.https://blog.csdn.net/weixin_40539826/article/details/110224590
3.https://blog.csdn.net/qq_53817374/article/details/123029099
















 5204
5204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











