






我想找的小说,网上没有下载的页面,想找个第三方得网站把小说里的内容直接复制到本地的txt文件里,于是就写了个python脚本来实现。
import requests
from bs4 import BeautifulSoup
# 定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
# 选择的页面范围
page_numbers = range(1, 100)
# 定义输出文件名
output_filename = "小说内容名.txt"
# 打开文件准备写入
with open(output_filename, 'w', encoding='utf-8') as file:
for page_number in page_numbers:
# 设置想要复制得目标URL
url = f"https://mp.csdn.net//{page_number}.html"
# 发送GET请求
response = requests.get(url, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取章节标题(对应你想复制得页面里HTML内容【 Title 】)
title = soup.find('h1', class_='Title').get_text(strip=True)
# 提取章节内容【 bookhome 】
content_div = soup.find('div', id='bookhome')
paragraphs = content_div.find_all('p')
content = '\n'.join([p.get_text(strip=True) for p in paragraphs])
# 写入章节标题和内容到文件
file.write(f"章节标题: {title}\n\n")
file.write(content)
file.write("\n\n\n") # 添加两个空行作为分隔
else:
print(f"请求失败,页面 {page_number} 的状态码:", response.status_code)
print(f"所有内容已保存到文件: {output_filename}")
这里的page_numbers 是每个网页里小说每章编号的范围,
title = soup.find('h1', class_='readTitle').get_text(strip=True)
content_div = soup.find('div', id='booktxt')
分别对应html元素包含的内容,记得每个网站有所不同也要更改。
如:(不对应以上代码)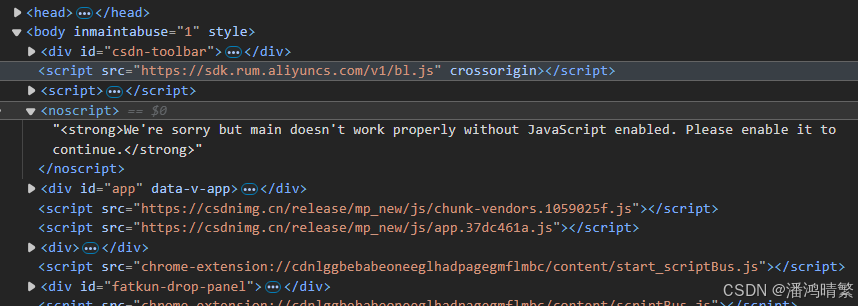

















 3069
3069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









