







第三讲 malloc/free
3.1 VC6和VC10的malloc比较
- malloc/free是C层面的函数
- 源代码是来自于VC6.0;因为比较复杂,因此以图为主,辅以部分源代码,理解其运行机制;
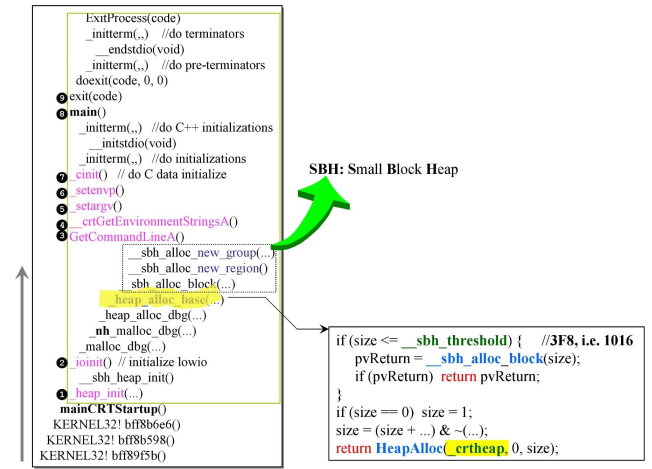
- 上面图从下往上看,在程序调用(第8步)main之前,可以看到有很多操作,以及调用Main之后的操作;
- 在这些操作中,有一个黄色标亮的
_heap_alloc_base(),size小于等于__sbh_thredshold==(1016)就执行__sbh_alloc_block(size),否则就执行window操作系统的一个函数HeapAlloc;
- VC10的如下,打叉是不存在的

- 新的VC10没有加判断,就是没有再最小块内存作特殊管理,都交给
HeapAlloc函数处理;- VC6的特殊处理,只是包装在一起到
HeapAlloc函数里了;
- 以下讲义都是以VC6为讲解对象:
- 首先看一下,第一个动作函数
_heap_init()
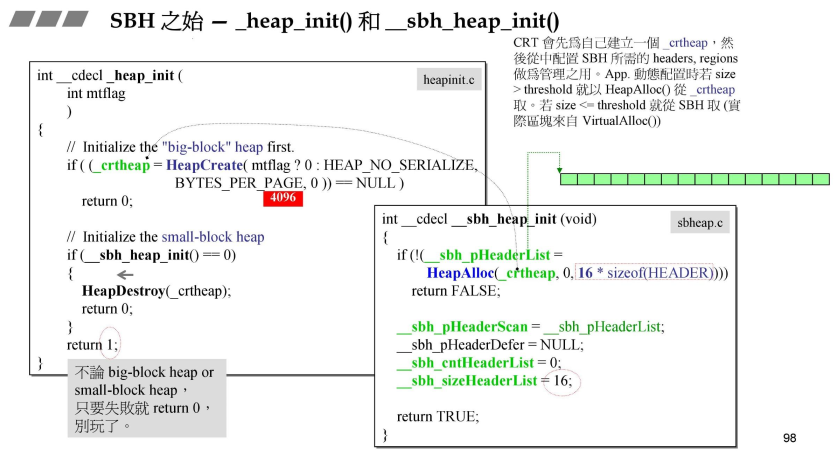
- 用以申请一块自己用的空间,调用
HeapCreate函数,- 然后执行
__sbh_heap_init()中调用HeapAlloc来,其中参数_crtheap就是指向刚刚申请的内存的指针,- 拿出16个HEADER大小的空间给这个指针,初始化就是将16个HEADER准备好;
- 具体HEADER就是下面展开样子,根据下方框的数据结构
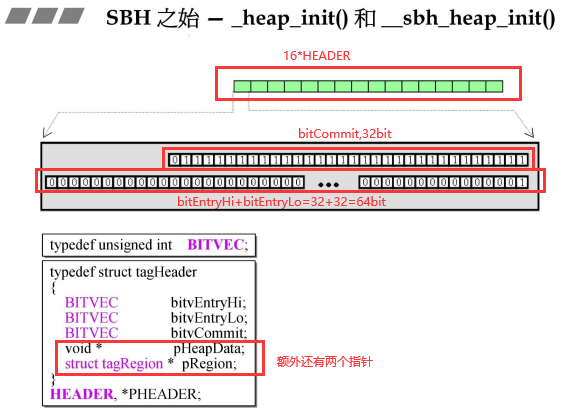
- BITVEC==unsigned int,3*32bit,其中有两个组合起来,一个是Hi,一个是Lo,将其组合起来其实是64个bit;
- SBH真正的面貌如下,为了进行内存管理而创建一个结构;是内存管理的消耗;
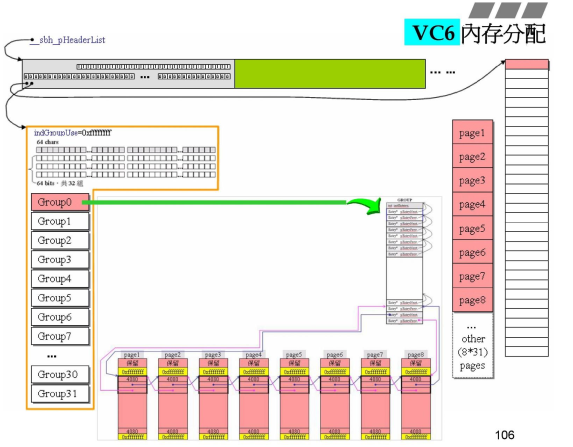
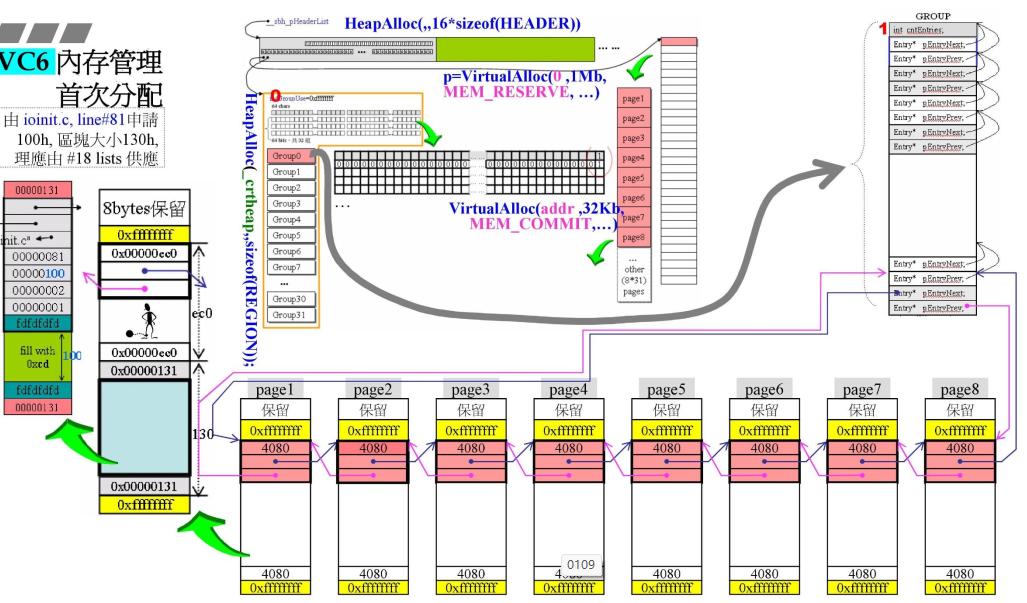
3.2 VC6内存分配
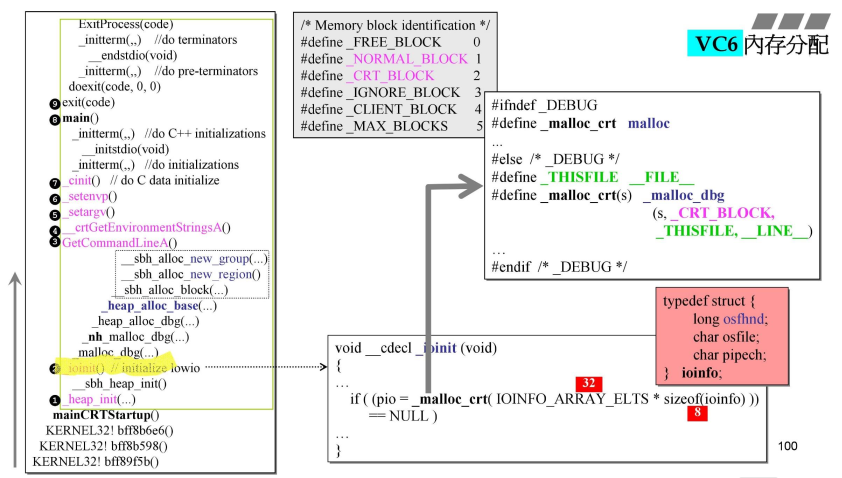
- 开始看第二步执行函数,黄色标注部分,其中源码有一部分如右框所示,
- 此处是第一次调用malloc,可看到右侧,
#ifndef _DEBUG,malloc_crt==malloc,else __malloc_dbg;_ioinit()中调用的malloc_crt()两个参数,申请的内存大小是32*8=256字节,十六进制就是100h,sizeof(ioinfo)的大小如右侧红色框所示,是8个字节,4+1+1=6->8;
- 红色框内函数,表示都是
_ioinit()函数,- 黄色标注函数,
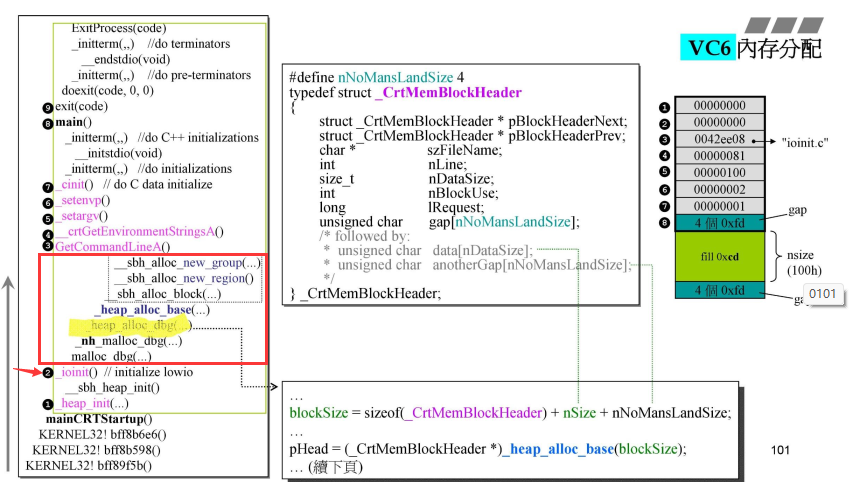
_heap_alloc_dbg()中传入的参数是nsize=256,就是上一页中的256个字节;另外加上了前后sizeof(_CrtMemBlockHeader)+nNoMansLandSize=4;这是在DEBUG模式下准备申请到那块内存;
- 将目前申请的三部分组成的
blockSize画成示意图如右图所示,DEBUG专用的;对于右侧3和4,就是两个指针,分别指向debug文件和具体行数,这里是ioinit.c和第81行;第5个DataSize记录真正的nSize的大小,就是100h;7是流水号,8是以字符形成的array;- 深绿色可以作为真正大小nSize的两个“篱笆”;
- 从malloc_dbg()第一次调用malloc到调用_-heap_alloc _dbg()大小在这里变大了,另加了两个部分,但是这里都还没有分配内存;
- 接着便调用了
_heap_alloc_base(blockSize)函数;这个参数已经是被调整过的blockSize大小;- 命名中,dbg一直在调整大小,block是调整好的大小;
- 在进入
_heap_alloc_base(blockSize)函数之前,还有一部分如下:

- 上图表示,每次malloc内存,虽然内存分配出去了,但是malloc过的每个内存,malloc都用链表串接起来了进行记录;
- 这就是为什么可以debug的原因;
- 因为在debug模式下,多了深灰色(实际申请内存之外)的东西;
- 上图中最后下方源代码,memset是预先填写一些特定的数值,在方框中的常量大小;
- **接下来是下一张图中的
_heap_alloc_baset()**之前提到的函数

- 为什么是1016呢,但是加上cookie=8字节,就是1024;
- 目前都是
_ioinit()中第一次调用malloc申请1024字节大小空间;

_sbh_alloc_block()将其得到的大小intSize做进一步处理,+2*sizeof(int)=2 * 4=8字节,就是图中上下粉红色的两块,然后+的部分是ROUNDUP,调整到16的倍数;- 第一次申请的nsize就是100h,(256,16进制),然后加上了上下两部分,(8*4+4=36,就是ox24,16进制),最后+4 * 2(上下cookie),=0x12C,上调至16的倍数,0x130;
- 上下cookie应该记录的是130,目前是131,因为最后4个Bit都是0,借用最后一个Bit来标记是在自己手上还是已经分配出去;
- 到目前,都还在调整大小,没有分配内存;
- 前面都是计算大小,目前是第一块内存分配出去了,
_sbh_alloc_new_region
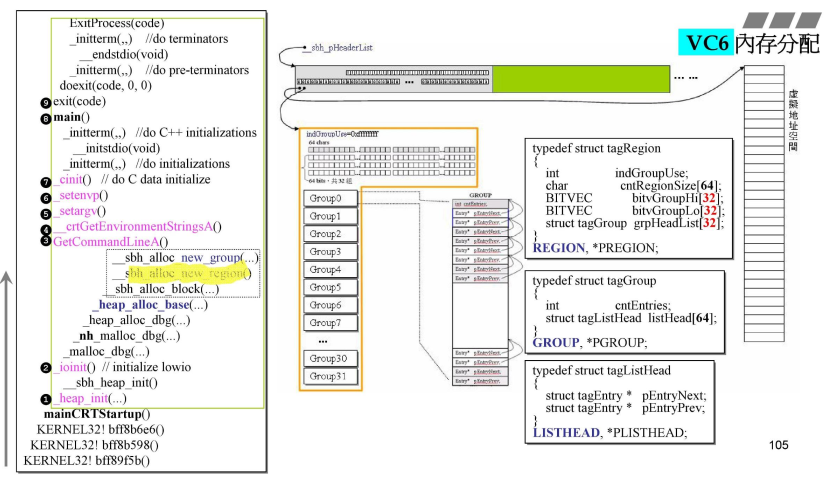
- 1个HEADER负责管理1M的内存;用下图所示的数据结构进行管理;其中一个指针指向真正的内存,另一个指针指向管理中心;
- 1M=1024KB,1KB=1024字节;
- 在黄色线框中,分别对应右侧数据结构,
- 一个int,一行char,
- 32行64bit的bitGroup,由高低位组成(作用:管理block区块是否存在的小细节);
- 下面就是32个Group0-Group31;
- 一个Group展开,就是右侧GROUP,对应右侧的tagGroup数据结构:
- 一个int,+64个listHead(类型是tagListHead),就是64对指针,128个指针;每两个指针指向一个双向链表;
- 为了管理1M内存,这些数据结构大小为16K;
_sbh_alloc_new_group,从1M中切出一块出来
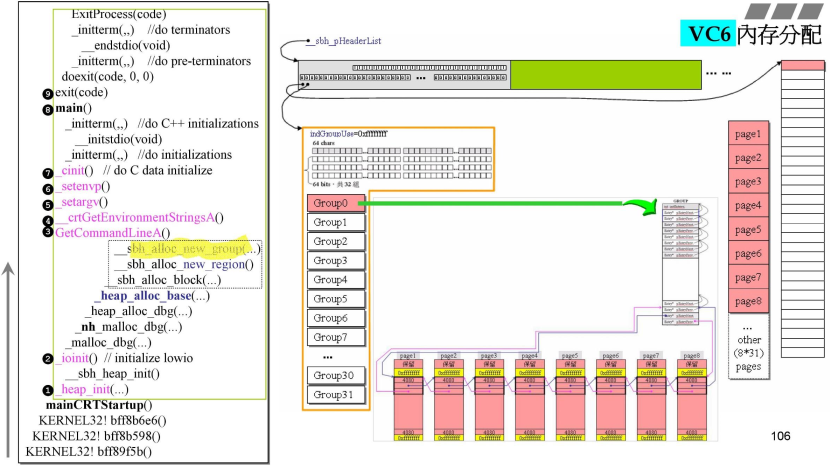
- 此时已经有1M内存;进入函数
_sbh_alloc_new_group,希望用32个GROUP对应右侧的1M,每一块(32K)由一个GROUP管理,每一个GROUP有64个链表;- 最右侧一个粉红块大小为32K,每一个32K再分为page1-page8.每一个page大小为4K,
- 16的倍数就是一段paragraph,这里4K就是1page;
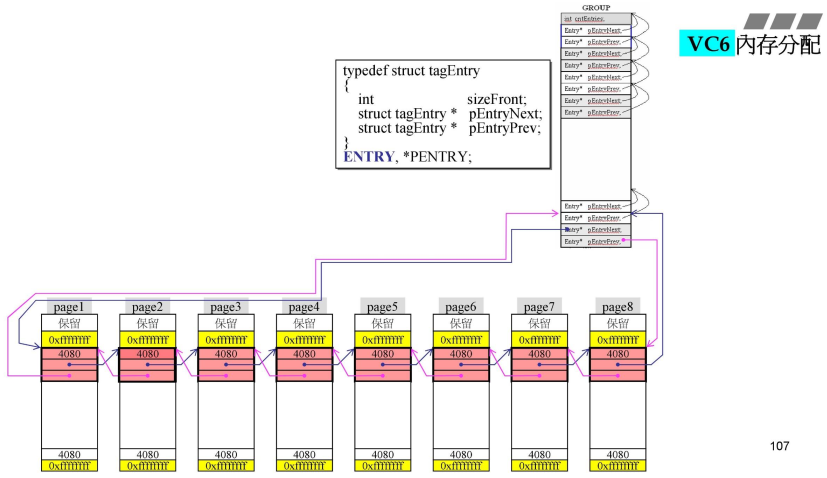
- 4080就是一块中两个黄色框之间的大小;本来是(4K)4096-8(两个黄色部分)=4088;但是要为16的倍数,缩小大小部分保留(8bit),真正可用的就是4080字节;
- 黄色上下都有cookie,就自己的大小为4080;
- 切第一刀
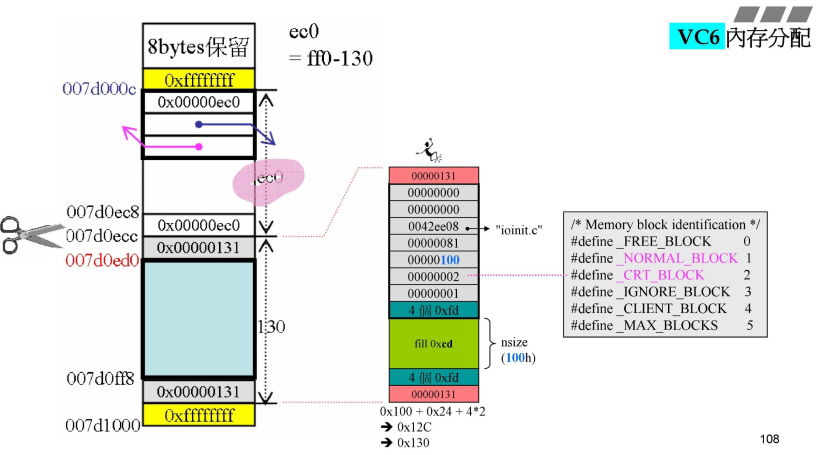
- 右侧就是切出去的第一个小内存,nsize=100h,
- 对应剩下了ec0h=ff0(4080)-130h;本来是130,因为是分配出去了,变成131;
- 切割动作,就是调整cookie+指针指出;
- 因为是debug模式,因此在真正要的nsie=100h中加上了上下信息调整大小到0x130;
- 注意,002代表
_CRT_BLOCK,之后进入main函数后,就是001代表_NORMAL_BLOCK;
3.3 SBH行为分析:分配+释放之连续工作图解

- 首次发出需求,就是在ioinit.c的第81行开始,申请100h(256)大小内存空间,经过调整为区块大小130h,如最左侧图所示;本来应该由64个链表中的#18进行操作,(130H/16-1,10进制);
- 最下面一行的8个page形成的链表,头尾指针指向最右侧的最后一格,最右侧的64个双向链表,比如,第一个负责16个字节,第二个负责32个字节,等等,但是最后这个就比较特殊,专门处理大于1K=1024字节的情况,
- 现在64个中,只有目前还有第63个为内存块;中间小格就是为了记录这些信息;
- 第二次开始分配内存;
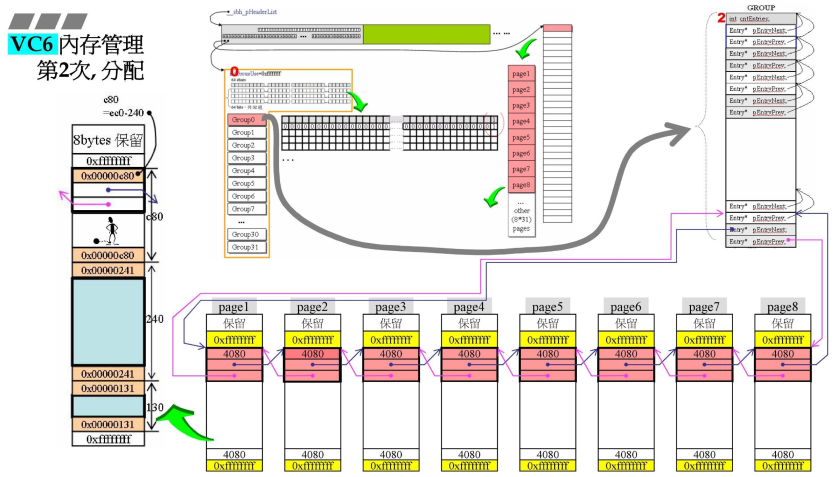
- 130h是第一次分配出去的内存,第二次就是上面的240h;
- 240h转化为十进制后,/16就可以得到应该对应的链表编号;(计算应该是#35号);
- 只有最后一个链表是1,就从最后一个链表中,开始分配;
- 最左侧:ec0-240=c80h;
- 注意,在最右侧的最上面,有一个int cntEntrys,每次分配都会+1;如果是0,就说明分配内存都已经回收完毕,就可以还给操作系统了;
- 注意,在画面中间的0,代表目前正在使用的是GROUP0;
- 第3次分配内存

- 步骤
- 1、根据70h,转化为10进制/16,计算应该对应的链表编号,;
- 2、根据链表编号查询中间表达,发现为0,那么从最后一个1(链表)开始;
- 3、来到page1,开始切割;(这里用的是嵌入式指针);
- 假设在第15次释放,调用了free函数(前面都是malloc)
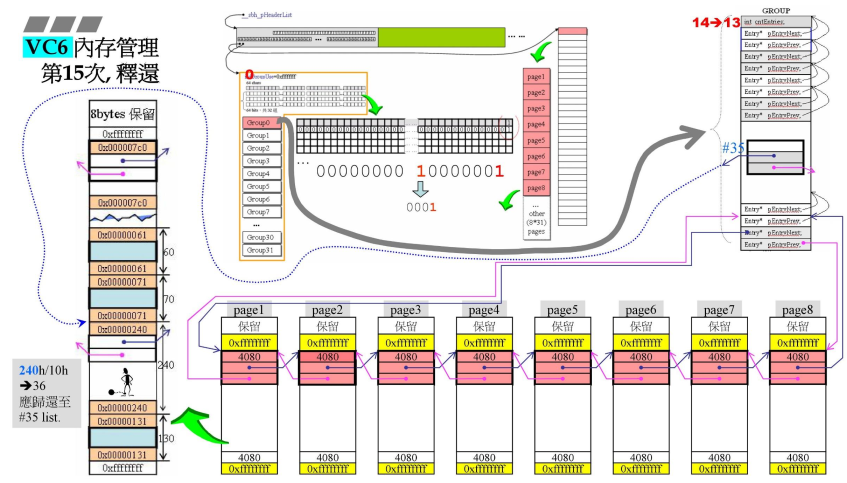
- 释放,因此右侧14-1=13;
- 目前释放第二次申请的240h空间;是将之前的cookie=241改为240,说明回收,利用嵌入式指针,(240h=576/16=36-1=35)将其挂在第#35号链表回收,那么中间bit第#35号bit置1,说明#35号链表也有区块;
- 第16次分配
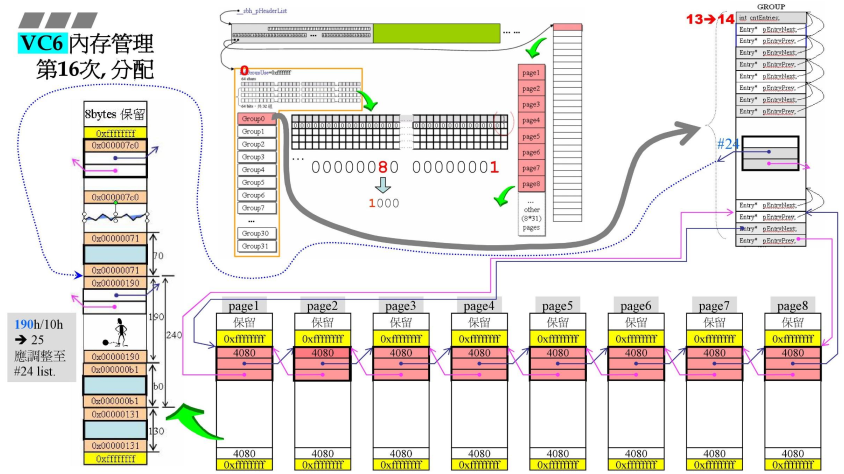
- 这次是bh大小,
(b0h=176/16=11-1=10)第#10号链表bit=0,那么就从10号往后找,那么从35号链表240h-b0h=190h需要重新安排这个剩余块,190h/16=25-1=24,应该挂在#24号链表之上;
- 第n次开始分配,这里GROUP1被分配完成,
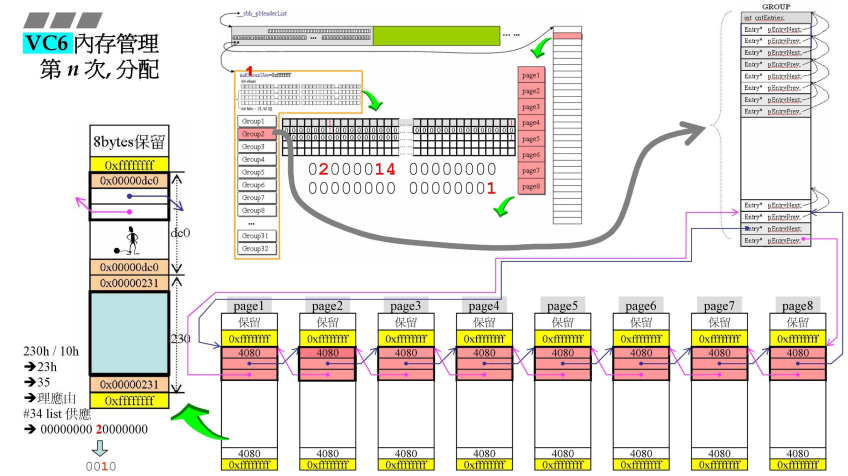
- 中间链表为02000014,表示有3处链表挂载有区块,
- 本次申请内存大小为230,因为前面的都不满足,因此重开一个链表,重新开始切割;
3.3.2 内存合并
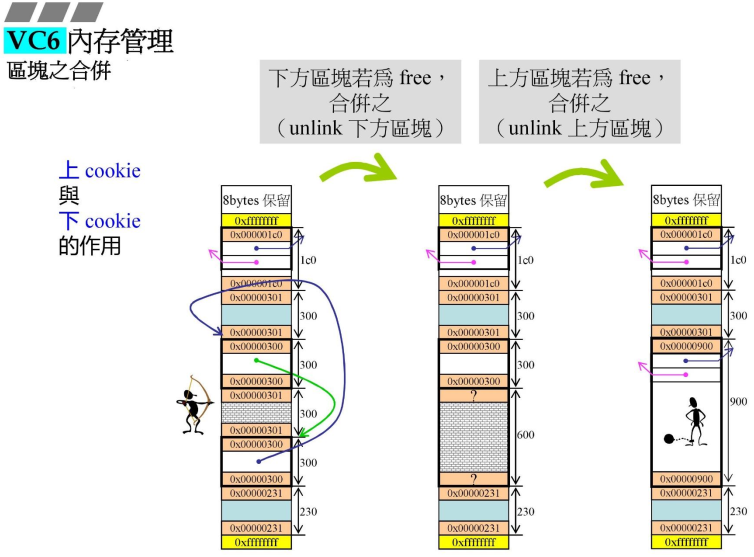
- 白色是应该要合并的部分,cookie的最后一个Bit是0,说明是已经回收的;300h应该都落在同一个链表上,
- 目前已经有两块了,归还的内存是灰色部分,怎么和上下已经归还的两个块进行合并?
- 首先检测到灰色下方的cookie最后一位是0,那么就先与下方那个合并,继续往上看4个字节,就到了上一块的下cookie,就继续向上调整;
- 因此,下cookie很有必要;
3.4 VC6内存管理
3.4.1 free(p)
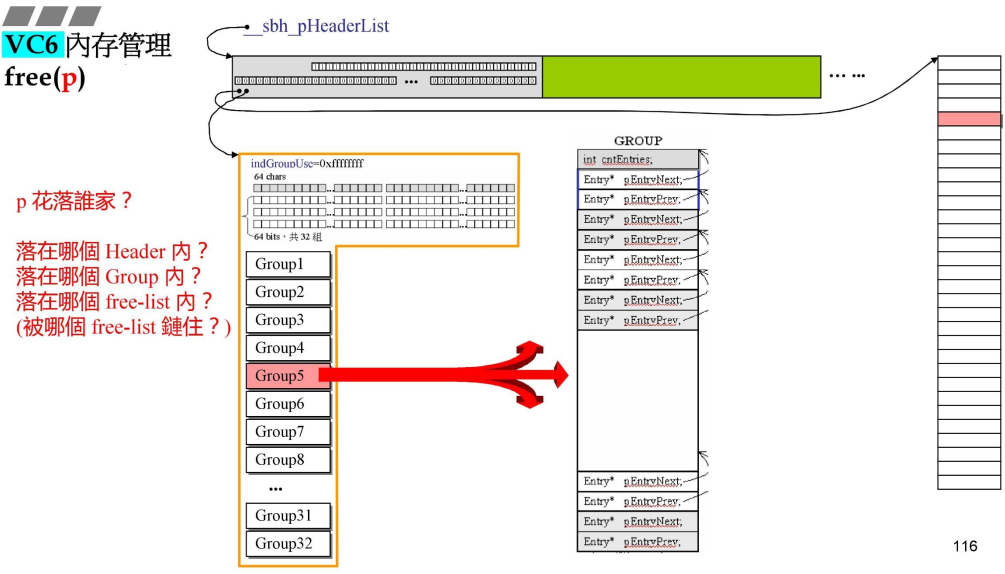
- 根据p来寻找,哪一个HEADER,pointer再确定是哪一段(一共32段,对应32GROUP)
- (16个)HEADER确定:有头尾指针,限定范围,一个一个找;
- (32个)GROUP就使用pointer-头指针/一段的长度(32K);
- 链表可以一直连接,为什么要分成32段?
3.4.2 分段管理
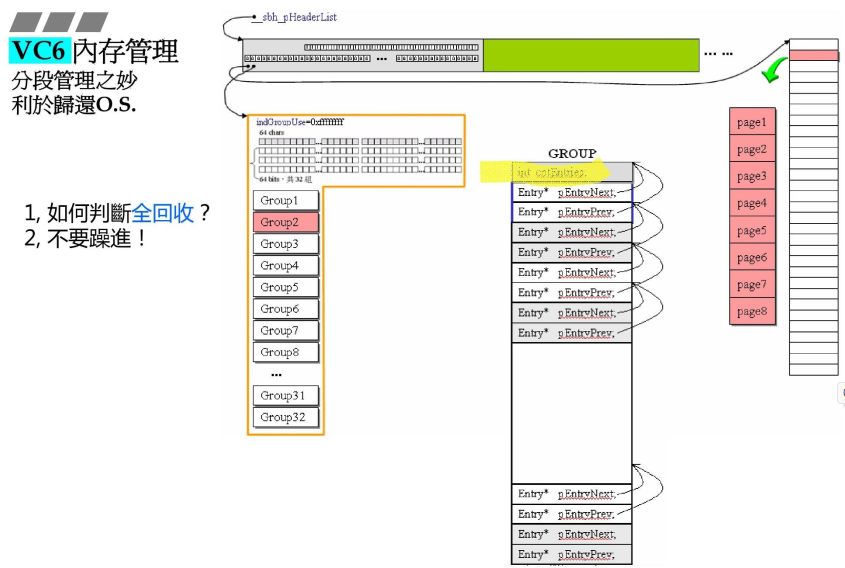
- 以一段(GROUP,32K)为更小单位,全部回收成功的机会更大;
- 根据每个GROUP最上面的cntEntries来确定是否真的全回收了,==0就完全回收;
- 完全回收时,就回到初始状态如下:
- 都回到最后一个链表的8个page,
- 之前分割出去挂在64个不同链表的内存都回收到初始状态;
- 这8个page不可以再重新组成一个完整的32K,因为有黄色部分
0xfffff阻挡;
- 不着急还,有两个全回收才会归回;
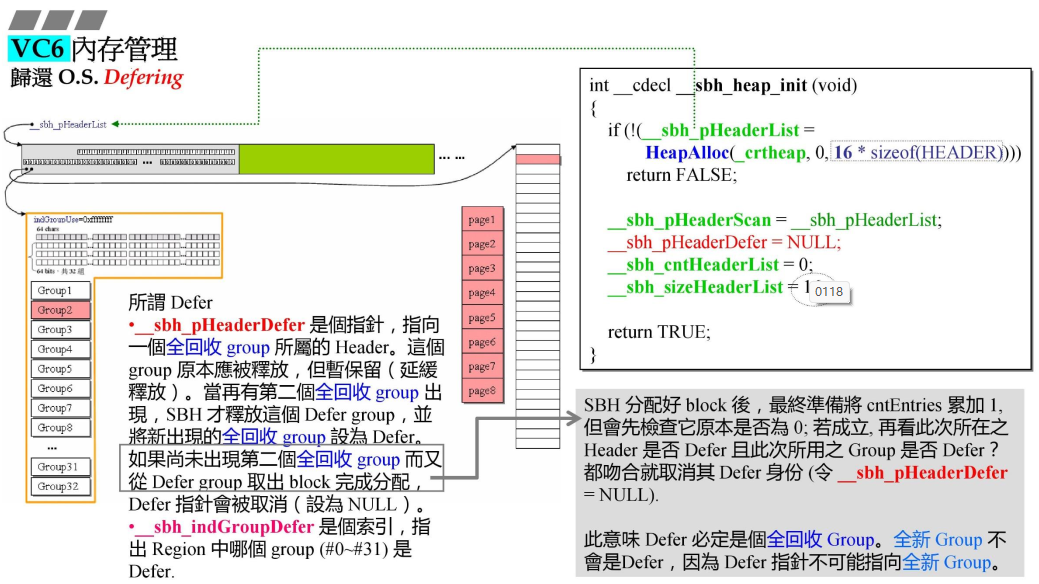
- 在右侧函数中,有一个全局变量指针
__sbh_pHeaderDefer=NULL,
- 指向一个全回收group所属的HEADER,此时延缓释放,
- 等待第二个出现,才会释放当前HEADER,
- 手上始终保留一个全回收HEADER;
- 当没有全回收,设为NULL;
- 当释放所有内存,SBH系统将会呈现的面貌;
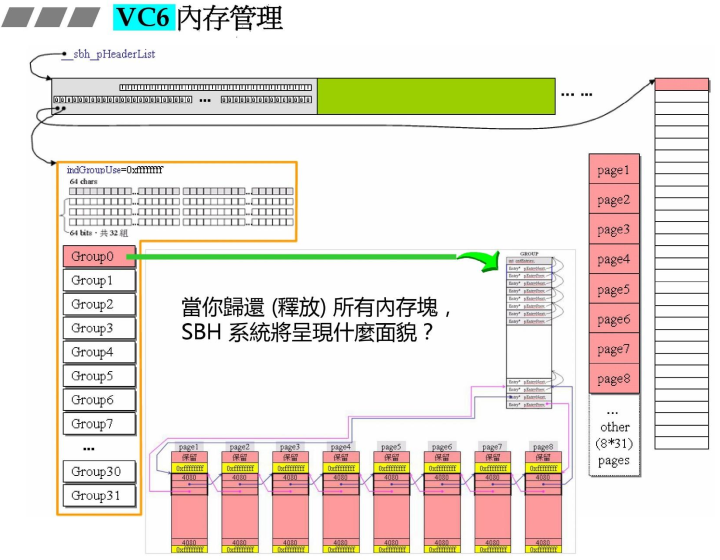
- VC6中提供的,像debug追踪链表状态的函数;

3.4.3 VC malloc+ GCC allocator
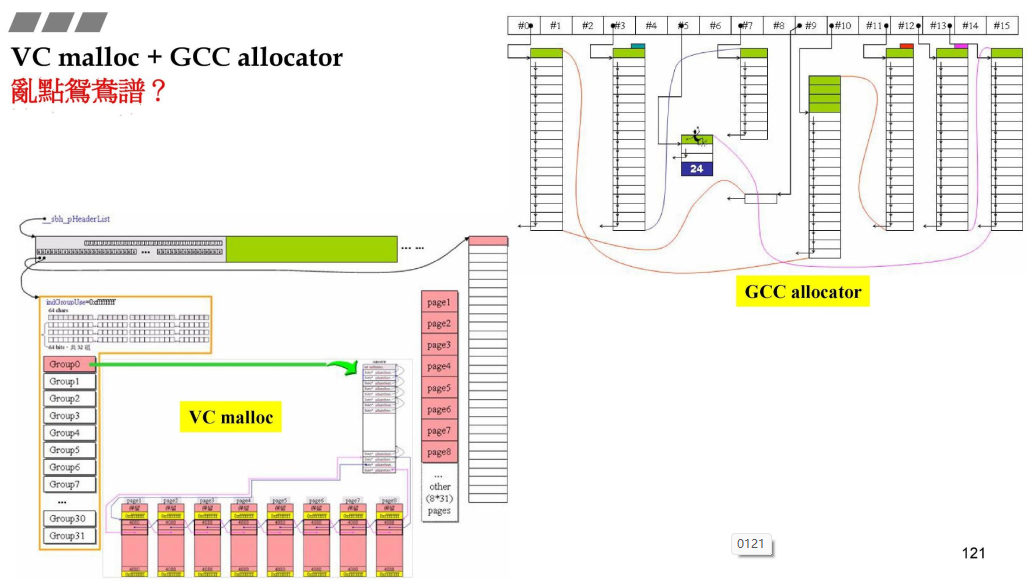
- 第二讲是GCC allocator;
- 第三讲是VC malloc;
- 但是都是相似的;
- 分配器要的都是从malloc申请内存的,分配器链表最高管理128字节,
- 使用allocator目的不是在于减少时间,而是为了减少调用malloc,从而减少cookie的内存消耗;
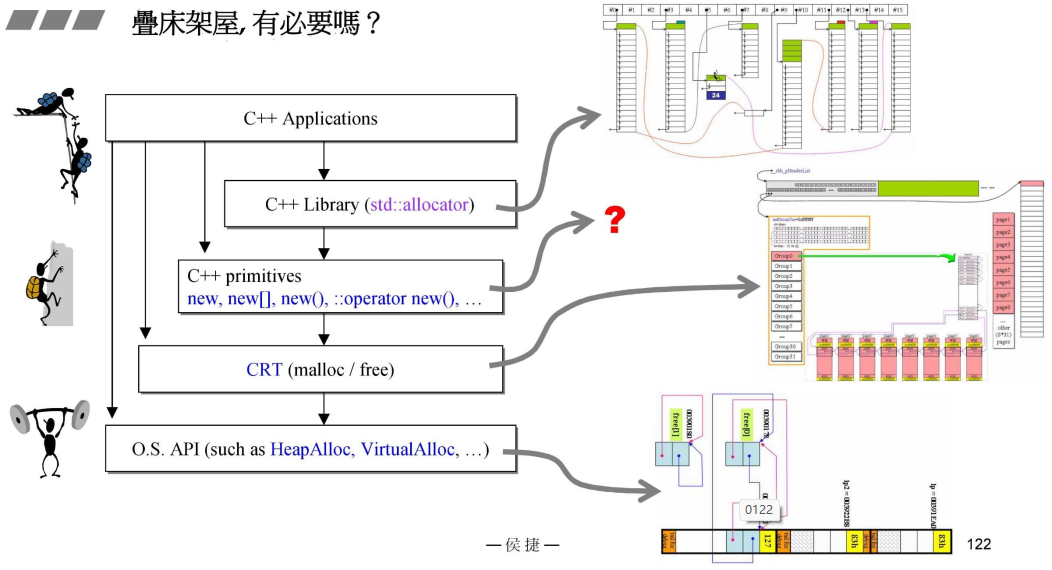
- 1、allocator减少cookie,缺点是没有free;
- 2、malloc调用OS也有类似自由链表的设计的内存管理;
- 3、叠床架屋有浪费!但是优点是CRT(malloc/free)是C语言跨平台的,不依赖于操作系统,不预设/依赖下层是否内存管理;
- 4、VC10就没有malloc/free设计,依赖于操作系统win,自己家产品了解;
第四讲 loki::allocator
4.1 loki的三个classes分析
- loki library
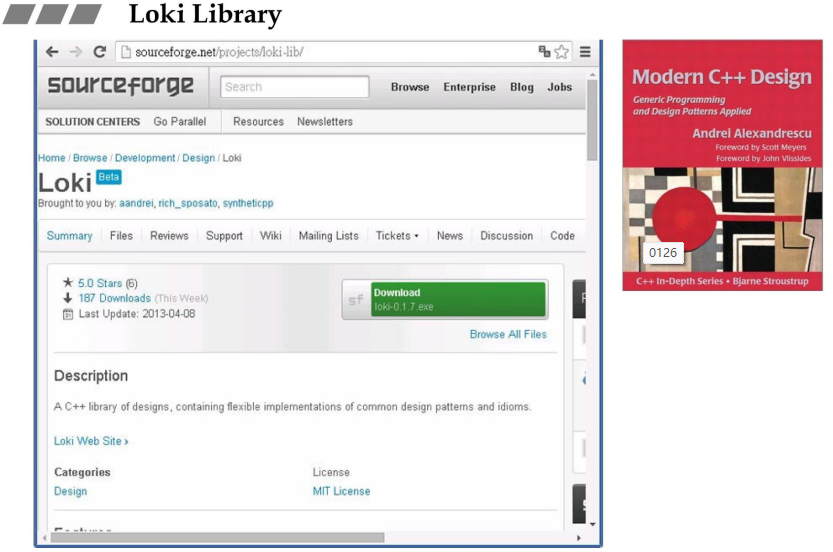
- loki library中的一个分配器alloctor;
- 很精简,GCC中分配器的缺点是没有free,但是这个loki是有free的,可以归还操作系统;
- 三个classes
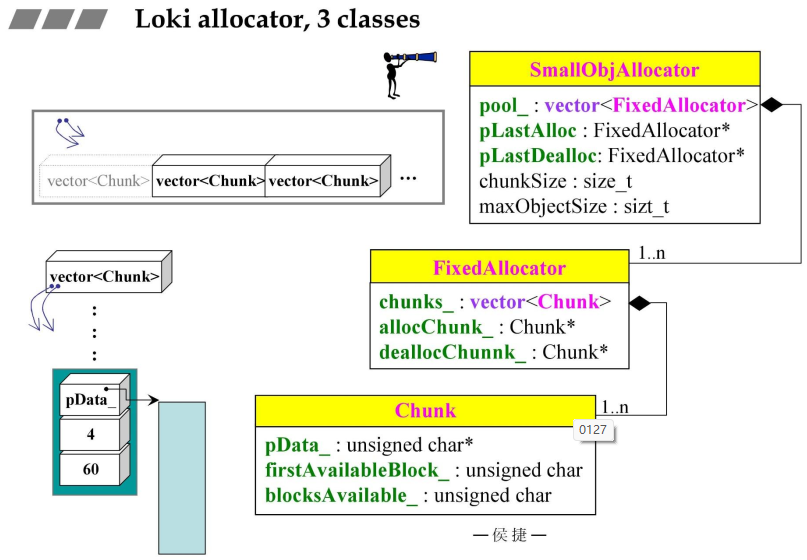
- 使用者面对的是
SmallObjAllocator类;Chunk的三个数据:
- 1)
pData是指针,指向unsigned char;- 2)
firstAvailableBlock是一个索引值(不是指针,特殊设计),表示当前供应的编号;- 3)
blockAvailable:目前还可以使用的区块数目;FixedAllocator:
- 有一个Chunk数组+两个指向Chunk的指针;
SmallObjAllocator:
- 有一个
FixedAllocator数组+两个指向FixedAllocator的指针+两个int;
4.2 Loki_allocator行为图解
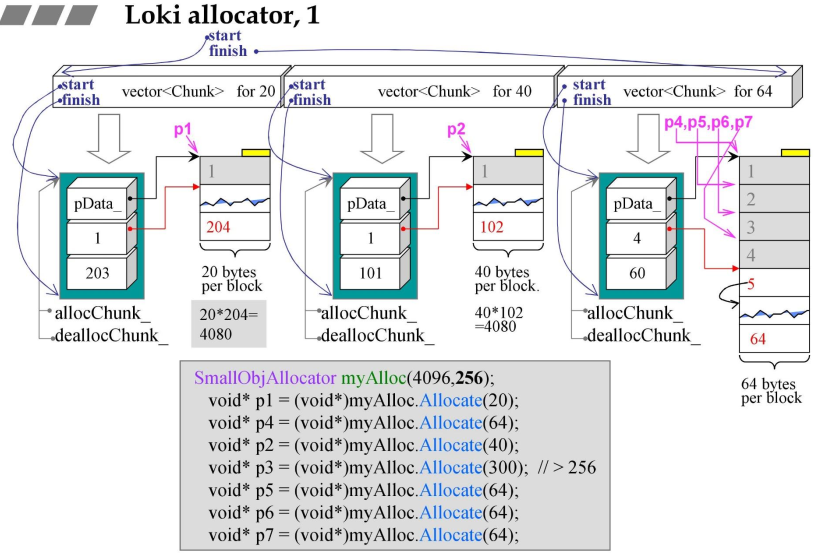
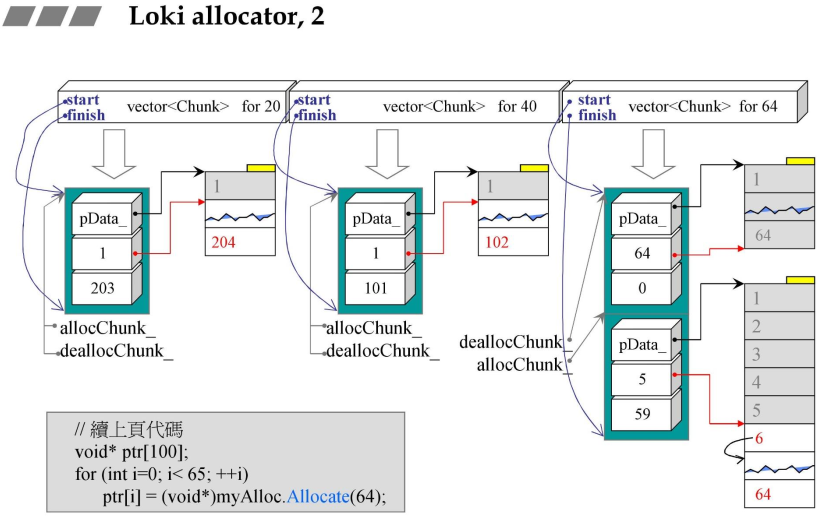
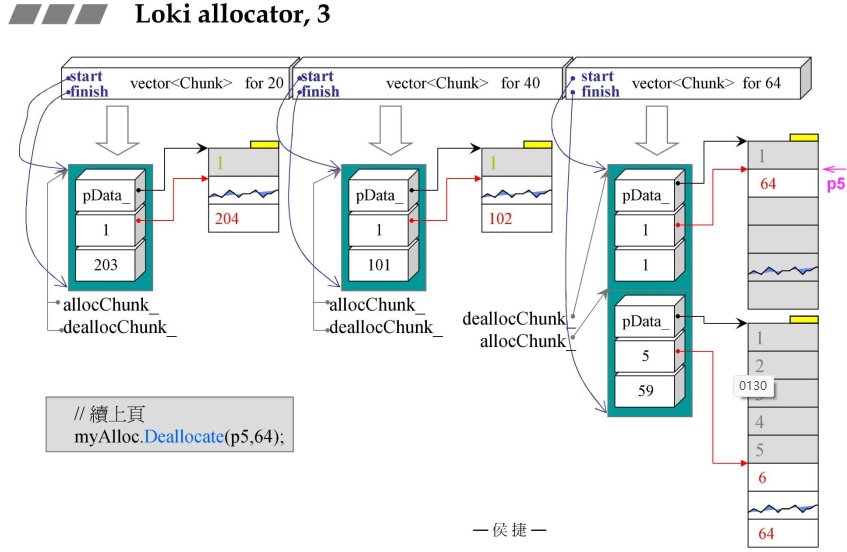
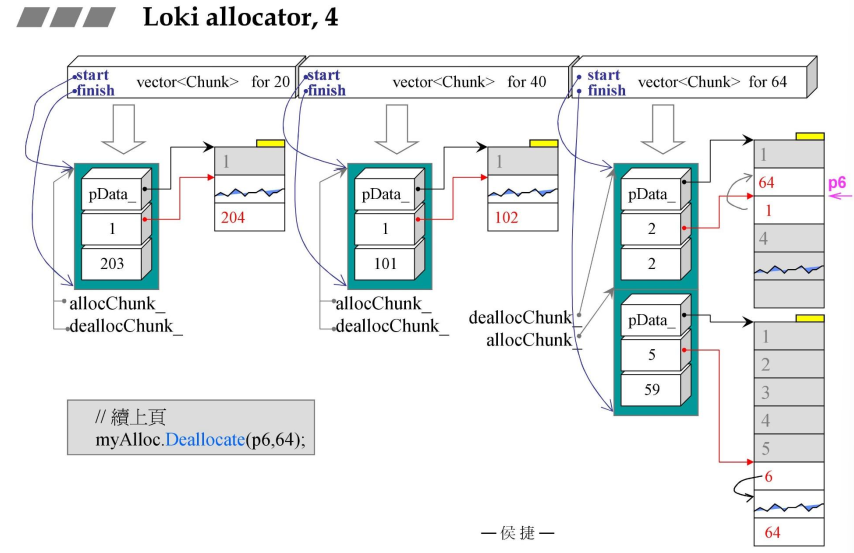
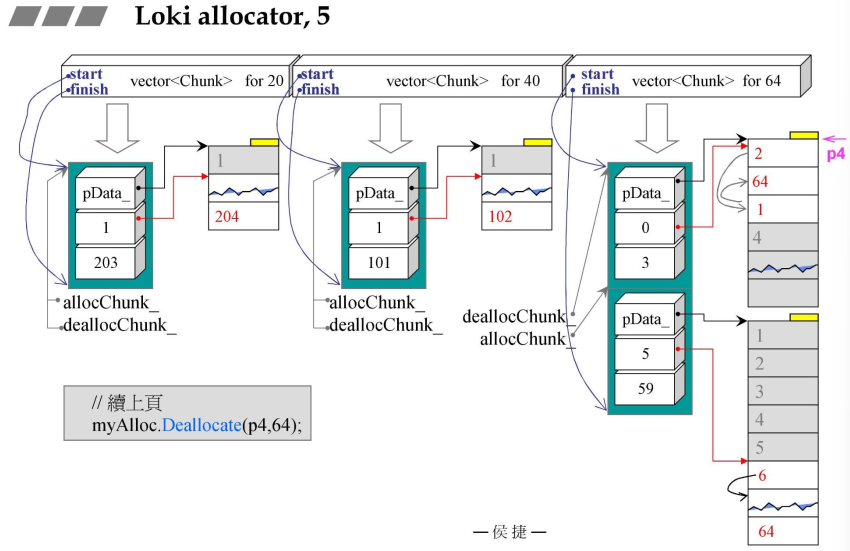
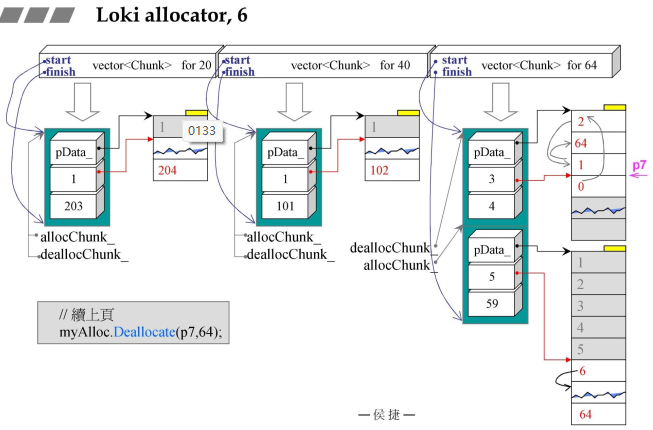
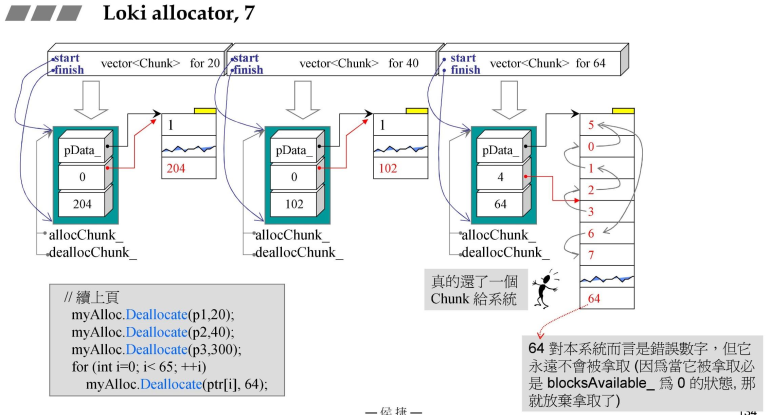
4.3 第一个class:Loki allocator,Chunk
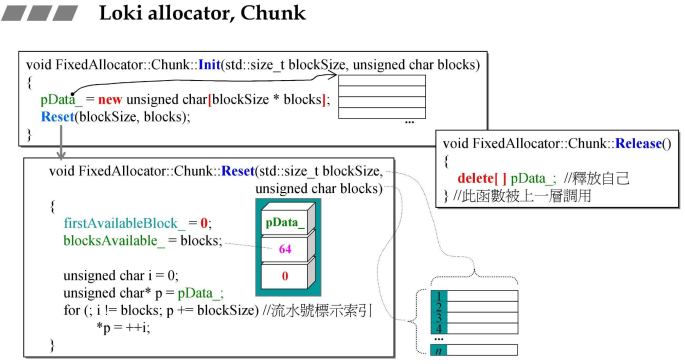
- init函数首先new一块内存,然后调用reset函数;
- reset函数将其分成64块,将最前面的一个Byte作为索引号,类似于嵌入式指针;
- 注意,右侧,是在delete[]还给操作系统;
- Chunk::Allocate()-分配内存
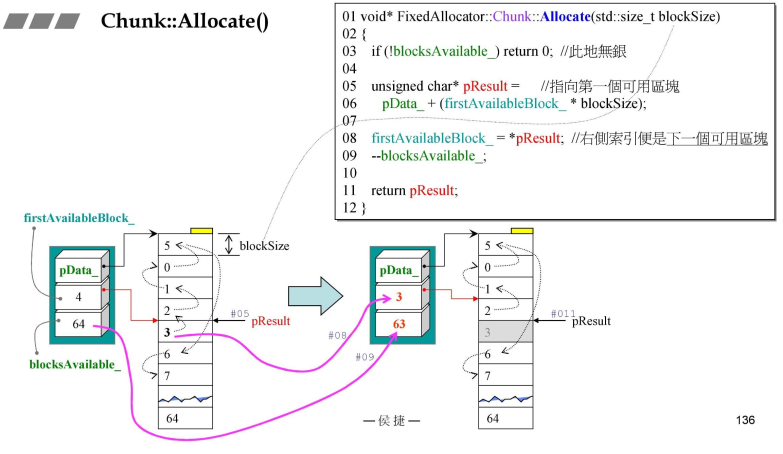
- 假设目前索引如左侧图所示,然后申请一块内存,首先给出去的是4号;4是索引号,不是指针;
- 然后4变成3,次高优先级变为最高优先级;
- 总结:数组代替链表,索引代替指针;
- Chunk::Deallocate()-回收,释放,归还
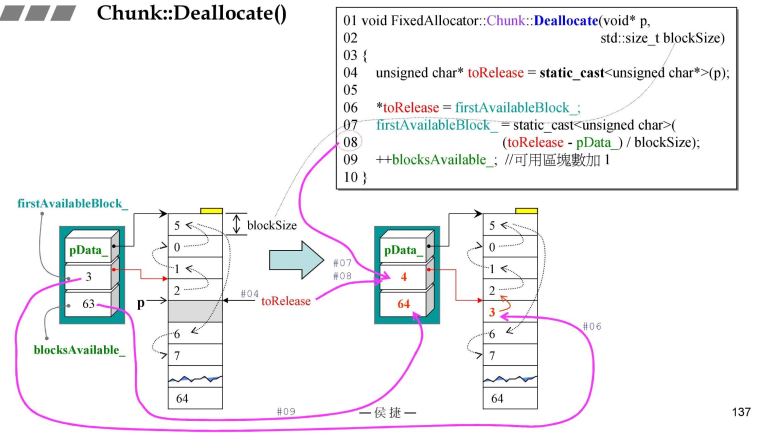
FixedAllocator::Chunk::Deallocate因为Chunk是FixedAllocator的内置类;- 假设目前的索引如作图所示,索引优先级依次为:3->2->1->0->5->6->7;
- Deallocate接收一个指针和一个大小,首先确定指针的位置,在哪一个Chunk中,然后再会进入到左侧图中,(p-头指针)/每段长度得到#08行代码;
- 要释放哪一个索引值,那么就是将其置为最高优先级(类似于单向链表,将其转移到头指针位置,进行删除),(删除的4与原先的3进行交换)
4.4 第二个class: FixedAllocator
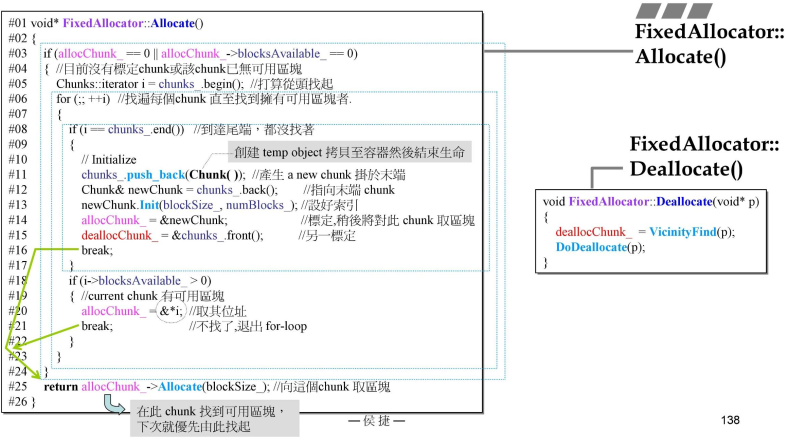
- FixedAllocator::Allocate()
- Deallcate的两个切割到的函数分别是
VicinityFind()和DoDeallocate();- FixedAllocator的两个指针:

- 用来标记最近一次满足分配要求的Chunk;(数据具有内聚性,区域性);
- #03行判断如果是初始状态,或者上一块已经用完了,那么就#05从头开始找起;找到后用break跳出来;
- #05使用迭代器找,
- 如果没有到尾巴end,那么到#18,判断是否有可用,标志起来allocChunk目前可用区块;#25开始return;
- 有一个特殊语法
&*i,i是一个迭代器,*解引用变成一个Chunk,对Chunk取地址,返回Chunk的头指针;- 如果到尾端都没有找到#08;加一个新的Chunk,push_back()一个临时对象使用;临时对象拷贝一份push_back之后,结束生命;allocChunk指向新的那块;
- FixedAllocator::Deallocate()中的VicinityFind()
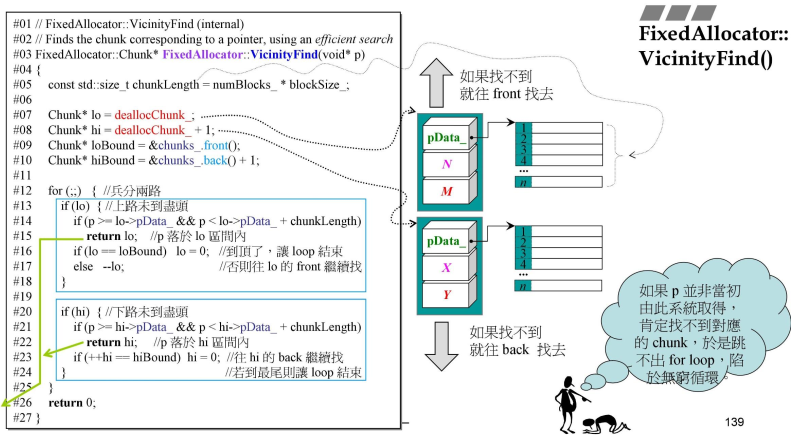
- 确定归还指针在哪一个地方
VicinityFind(),然后再DoDeallote();- VicinityFind是临近查找法,#05行,先确定好一段的长度。# 07的lo就是上一次归还的地方,hi就是lo+1;loBound是整个的起点,hiBound是整个vector < Chunk >的终点;
- #12,就是兵分两路,开始一路上找lo–,一路下找hi++;
- 但是这里循环,会出现如果找不到,会一直循环;没有做处理;
- 如果找到就return回去,开始执行DoDeallocate();

- FixedAllocator::DoDeallocate()
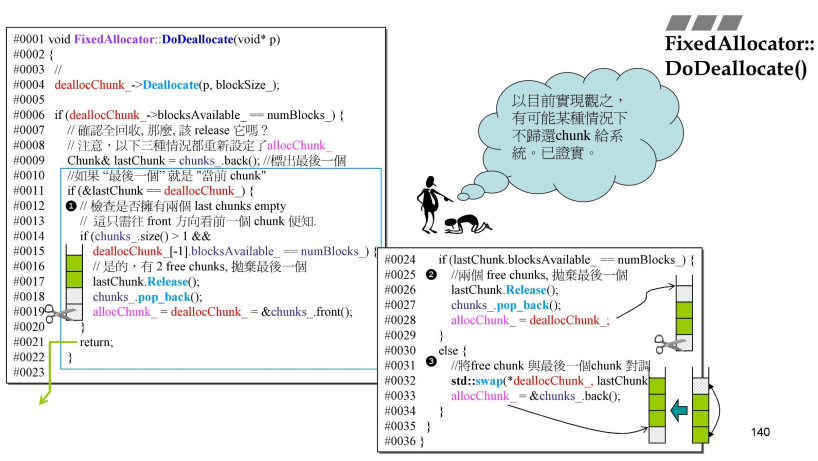
- 红色指针deallocChunk,就执行之前讲的
Chunk::Deallocate进行回收,- #06行判断,可用区块是否等于之前登记数量(加判断是否全回收)如果
- 不等就直接跳出来了;
- 如果已经相等了,就是执行等待第二个全回收出现之后,才会释放这个全回收;–延缓释放;
4.5 Loki allocator检讨

第五讲 other issue
- GCC下的其他的分配器allocator
5.1 GNC C++对allocators的描述
- 文件位置
- 官方解释allocator

- 1)string也是一个正规的容器;
- 2)每个元素类型为T的Allocator模板参数默认为allocator;主要两个接口就是allocate和deallocate;
- 3)n指的是客户申请的元素个数,不是指空间总量;

- 本讲要讲的七个分配器之二就是这两个
gnu_cxx::new_allocator,gnu_cxx::malloc_allocator,在别的名称空间;
- 这两个可以看右侧源码,并没有内存池的设计,申请一个调用一次malloc;
- 不同的是,第一个new分配器是分别调用的operator::new和operator::delete,可以有重载函数改变行为的机会;但是第二个malloc直接调用的std::malloc和std::free,不可以重载;

- 智能型:内存池
fixed-size pooling cache指的是,固定大小,比如#1负责8字节,#2链表负责16字节…#16负责128字节;- 相较之更复杂的是
bitmap index;- 使用cache(内存池),可以减少调用operator::new和operator·::delete;
- 黄色标出来的,malloc本身就是内存池设计,本身并不慢,减少调用次数带来的速度优势并不明显;主要在于减少cookie,提升空间利用率;
- 对应的分配器分别是
gnu_exx::bitmap_allocator,_gnu_cxx::pool_allocator,最后一个其实是多线程allocator_gnu_cxx::_mt_alloc,

- 现在将分配器切成父类与子类,分别做不同的事情,不过大部分都是父类做;没有功能增加;
- 父类是终端用户无法操控的;

- 另外两个智能型的分配器allocator,
gnu_cxx::debug_allocator,是一个外覆器,本身就需要一个分配器,自己本身不分配内存;添加一些记录客户申请量就将任务分配器完成,回收用assert检查;_gnu_cxx::array _allocator,允许分配一已知且固定大小的内存;array是新增加的容器,容器内部就是C++的数组,用上这种allocator,大小固定的容器就无需调用operator:: new和operator::delete;- 右侧代码描述在进入之前有一些动作,进入main之后还有一些动作;在进入main之前就可以调用array_allocator用的是C++的静态数组,其他的都是动态内存分配malloc出来的;其实Startup的第一步就是内存分配管理;
- 后序重点就是bitmap_allocator;
5.2 VC2013标准分配器 & G4.9标准分配器 与new_allocator
- VC下的标准分配器-没有特殊操作

- 默认分配器allocator;
- 主要两个函数allocate和deallocate,没有什么特殊操作,就是调用operaor::new和operator::delete;
- G4.9下的标准分配器new_allocator-“阳春白雪
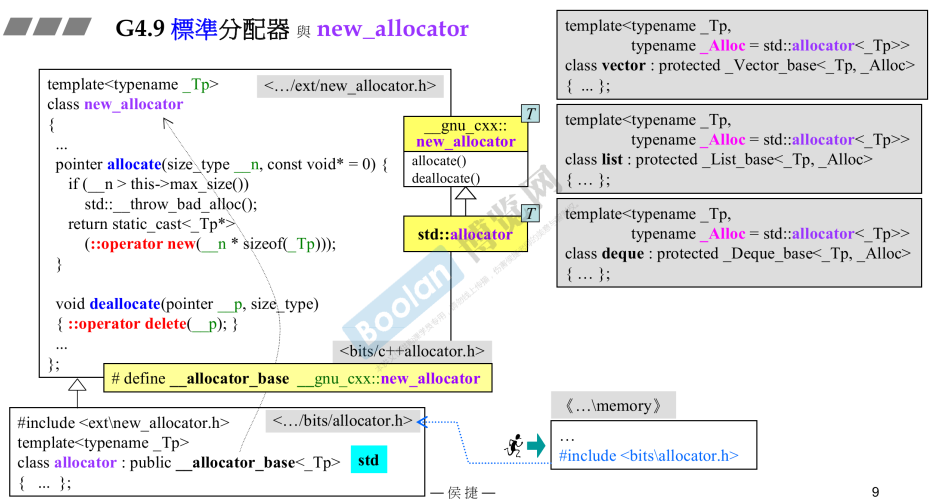
- new_allocator也是"阳春白雪",不做特殊设计;
- G4.9 malloc_allocator-直接调用malloc和free

5.3 G4.9 array_allocator
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ibedxEXg-1656208249892)(https://raw.githubusercontent.com/caterpillar-0/picture/main/image-20220623172609308.png)]
array_type只是一个指针,指向蓝色部分,蓝色部分typename黄色部分,就是一个array数组;- 分配与释放动作都是针对这个数组,是静态内存,其实不需要释放,因此它没有deallocate(),是继承自父类的空函数;
- allocate函数具体动作如右侧所示;
- G4.9 array_allocator的使用
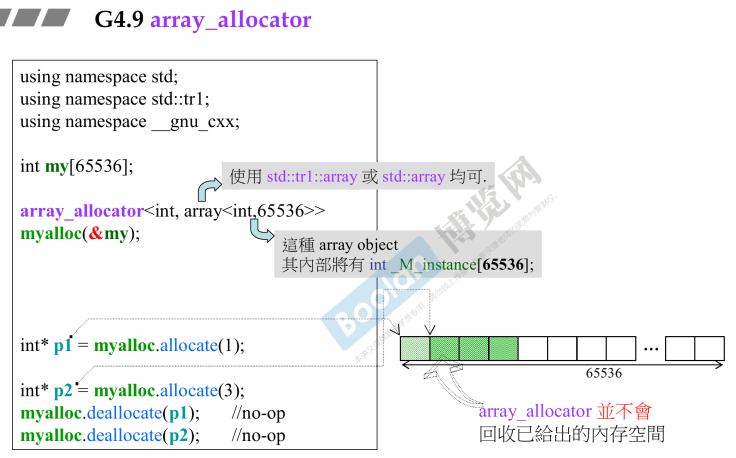
- array_allocator传入一个数据类型,和一个数组;
- 使用分配内存,使用.allocate();
- array_allocator并不会回收已给出的内存空间;
- 如果new分配动态数组?使用array_allocator?
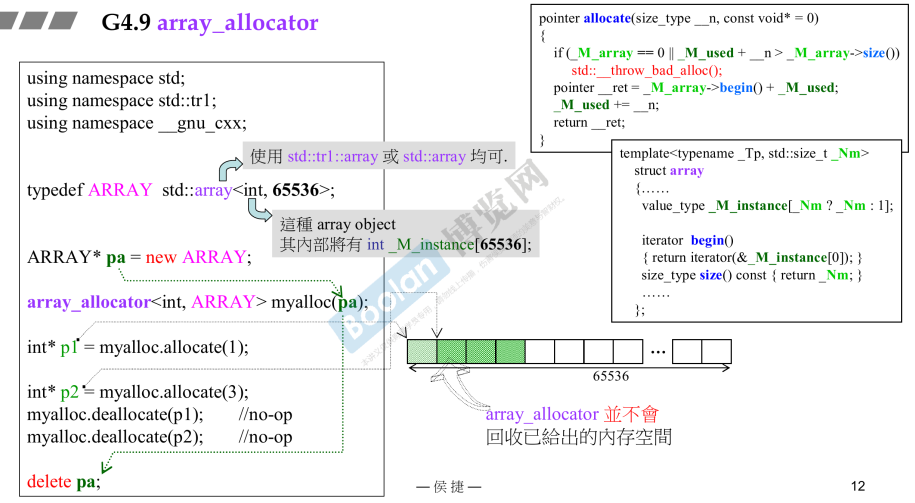
- 不同之处就是,静态数组和new动态数组;
5.4 G4.9 debug_allocator
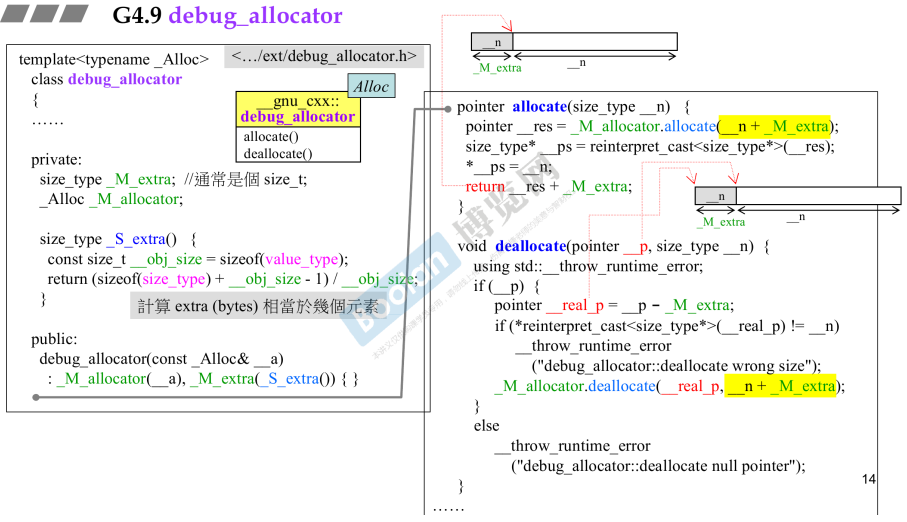
- debug_allocator没有父类,有一个模板参数,包装分配器;
_Alloc就是内部的分配器,_M_extra就是额外的记录大小的数据量;- 构造函数,就是传入分配器,赋值
_S_extra()函数参数;
_S_extra()如右上角图素食,就是原本大小+_M_extra(通常为4字节);计算这个——M——extra大小(4个字节)占几个区块元素;- 因此,在allocate的时候,计算的分配内存的总大小就是客户申请内存+自己加上的变量;
- return的时候,客户只看到分配给它的部分;
- 总结:包覆起另外一个分配器,那分配的区块多带一块
_M_extra空间,用以记录区块大小;–扮演了cookie的作用,大概没有用处;
- 之前讲的G2.9的std::alloc
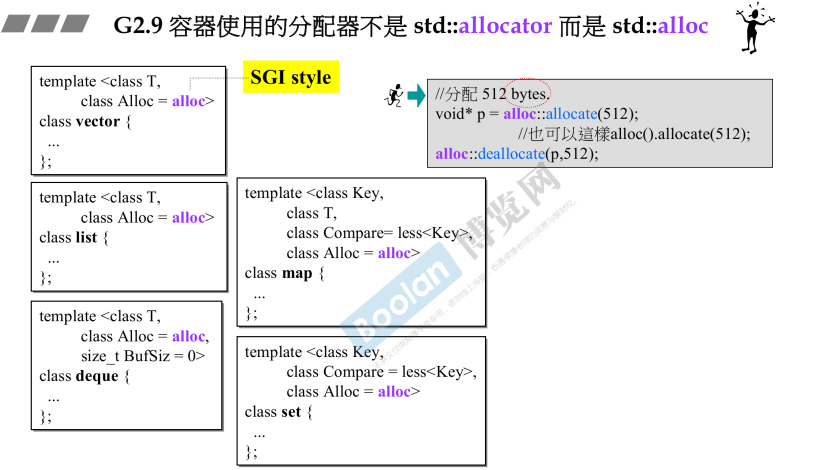
- 更名为__pool _ alloc,缺点是没有free,G4.9仍然没有改善
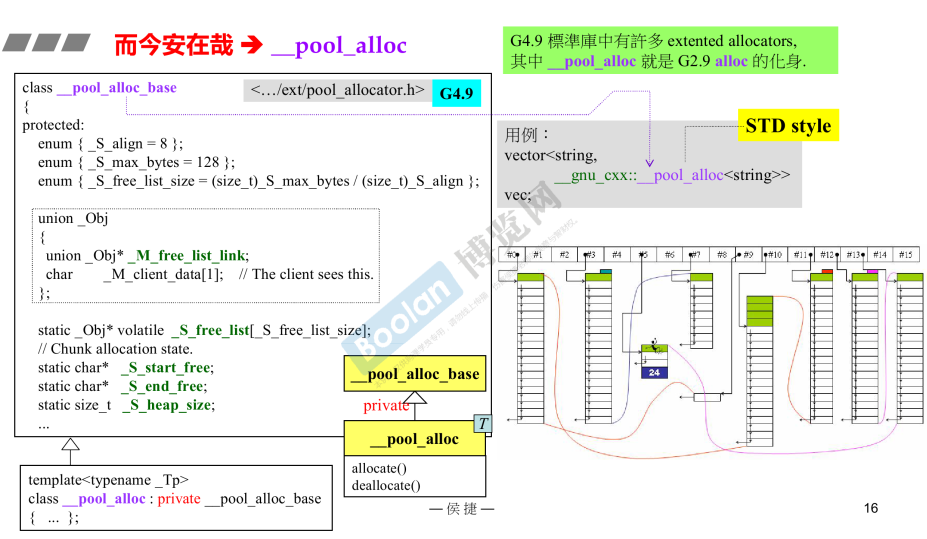
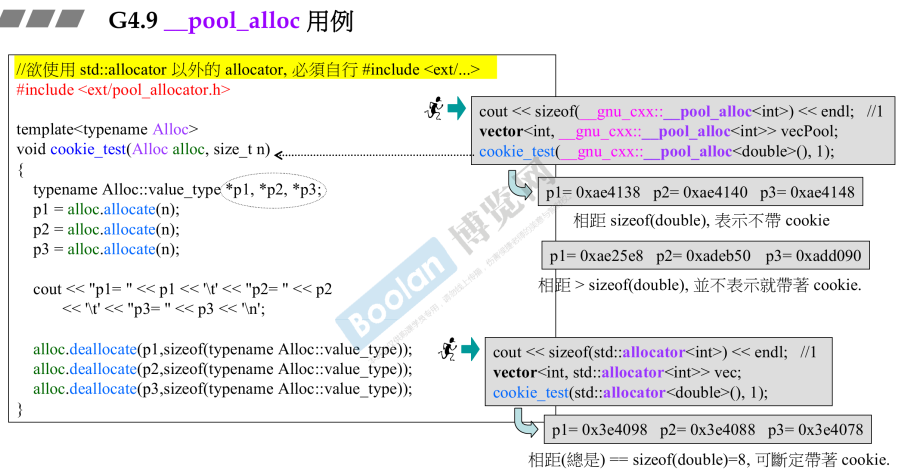
- G4.9 __ pool _ alloc用例
5.6 G4.9 bitmap_allocator

- 可以不必注意,为了它本身分配器的实现而继承的free_list父类;
- 两个最重要的函数分别是allocate和deallocate·:
- 其中重要的两个行为,1和2;
- 通过n==1的判断看出,它只为用户申请一个元素的行为服务;其他调用operator::new和operator::delete;
- 利用图形解释原理行为模式
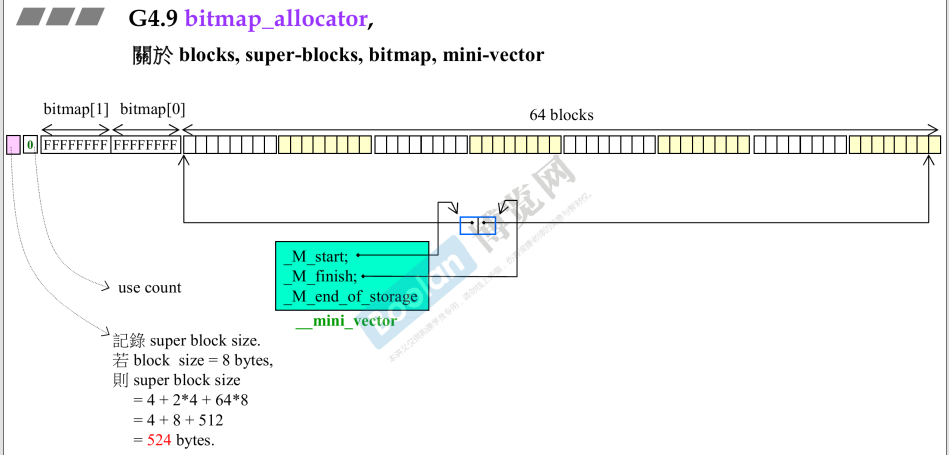
super_block的组成:
- 1)
block就是后面,客户(容器)需要的一个元素大小;一次性挖64blocks,每次二倍增长扩容;会越来越大;- 2)整个一长条称为
super-blocks;- 2)
bitmap用来记录后面block是是否已经分配出去;需要两个Int整型,2*32bit=64bit;- 3)
use count是一个int,代表已经用掉的block数量;- 4)最前面粉色,记录整个
super_block的大小,不包括粉色;这里计算时524字节;_mini_vector来控制这种长条super_block;
- 有两格(两个指针)表现一个单元,分别指向64block的头和尾指针;
- 如果有第二个
super_block就有第二个单元,这些单元会放在__mini_vector,自己实现的,不是使用容器;__mini_vector中三个指针,start和finish分别指向vector的头尾,end_of_storage指向vecor容量的最后地方;
- 开始在bitmap_allocator分配第一个内存
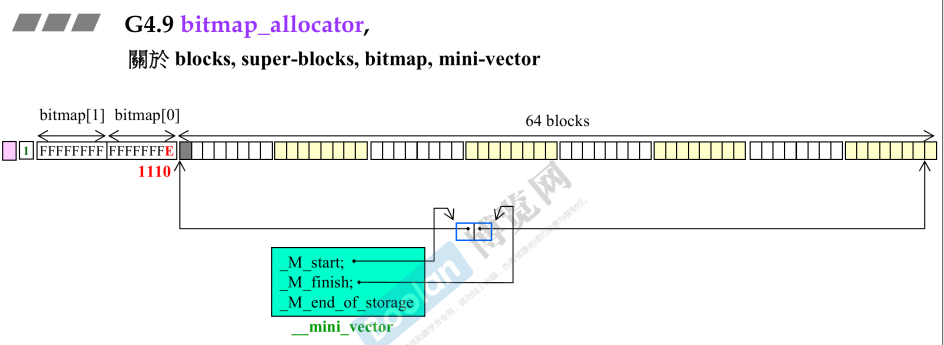
- 第一格变灰,分配出去第一个,对应bitmap最后一个bit=0;
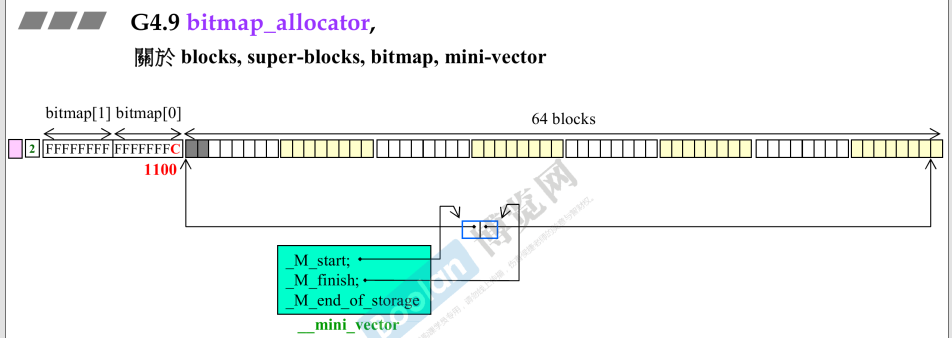
- 第2格变灰,被分配出去第二个,对应bitmap最后两位变成0;

- 一直到64个都被分配出去,此时bitmap如图所示;
- 到目前位置,都还是一个super_block;vector只有一个元素;
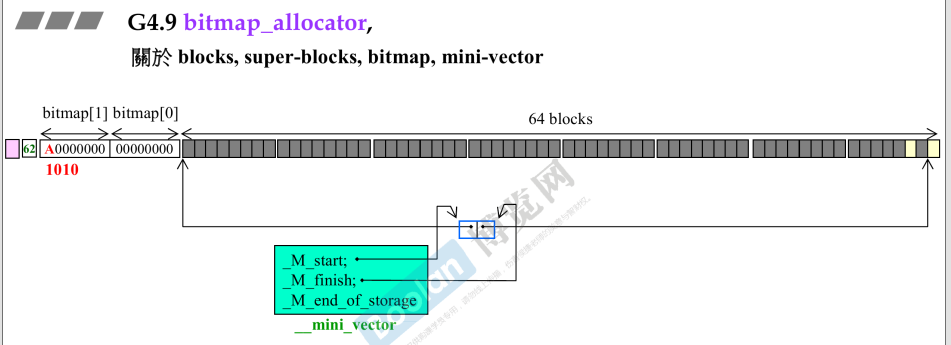
- 有一个block归还时的状态;
- 当一个
super_block用光时:
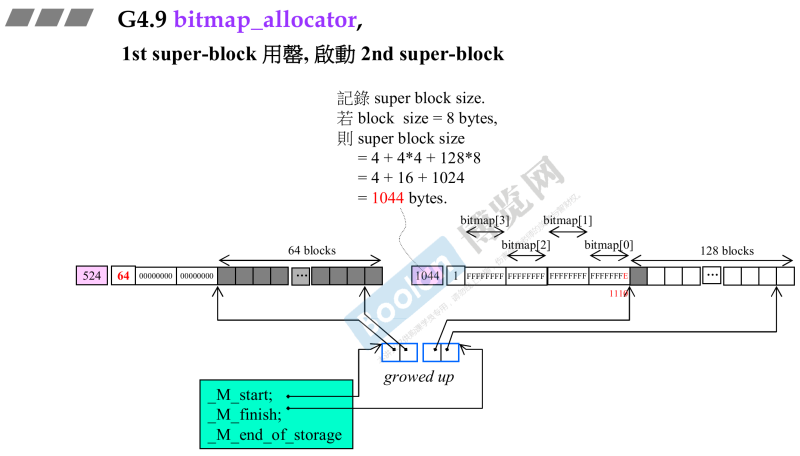
- 第二个
super_block是第一个的两倍就是64*2=128,就需要128个bit表示状态;- 管理器vector会两倍扩容,并且会转移地址,重新copy转移;
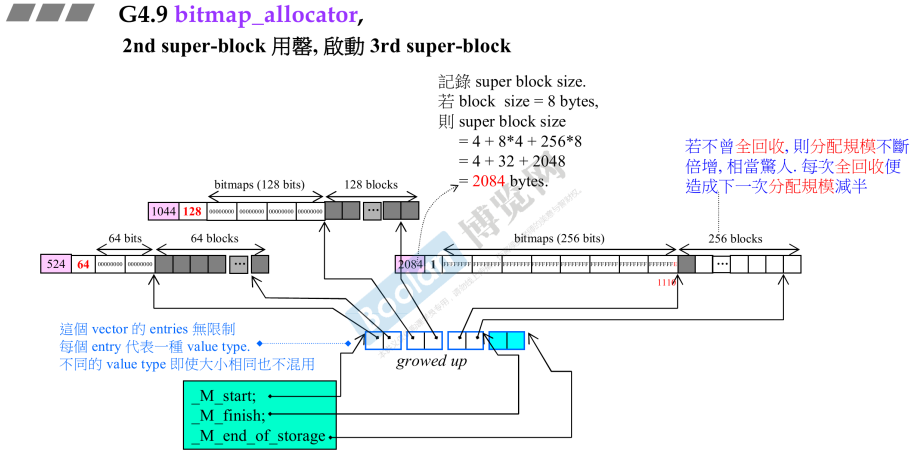
- 如果不全回收,那么分配规模会指数级增长!
- 第一个super_block全回收
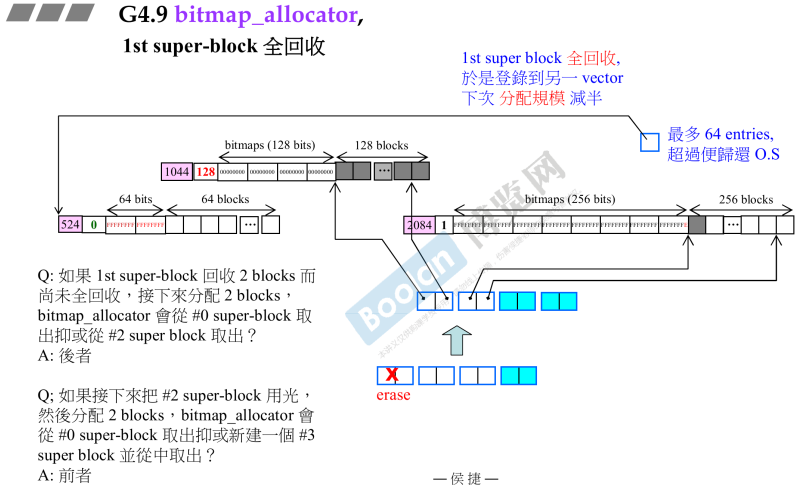
- 假设将第一个
super_block全部归还,全回收,
- 此时会用另外一个
_mini_vector自由链表管理,下一次分配规模减半;- 当free_list的单元数(entries==64)就会归还给操作系统;
_mini_vector由于第一个全回收,erase操作那么后面的依次往前移动一格;
- 第二个super_block全回收

- 当free_list达到64个阈值,那么比较谁的suer_block大,就释放哪个super_block;
- 第三个super_block全回收
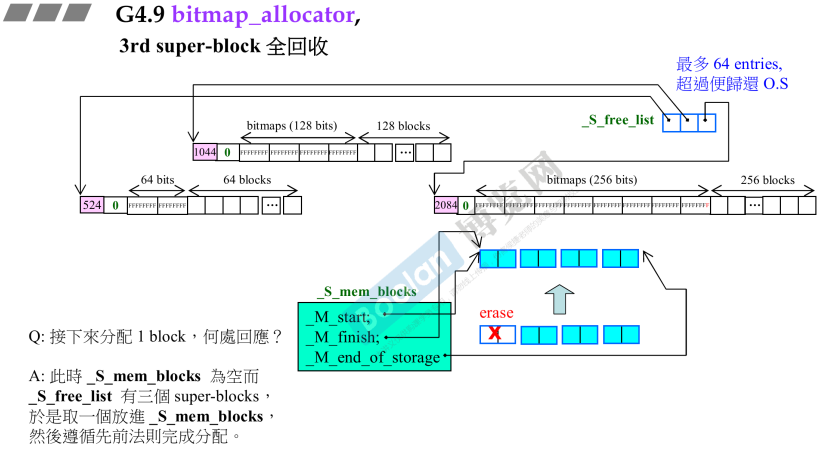
- 但是
__mini_vector并不会缩小;- 此时有新的申请,那么就将free_list的三个挂回来一个。
5.7 使用G4.9分配器
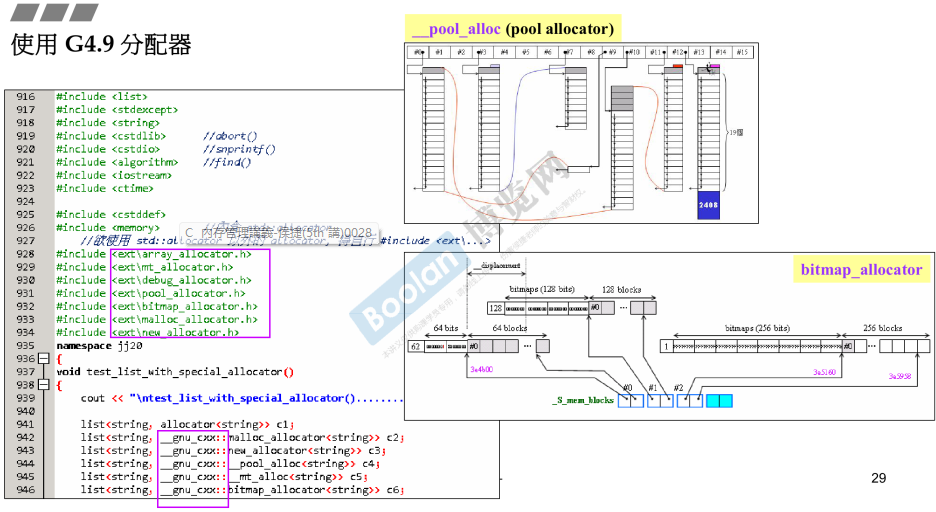
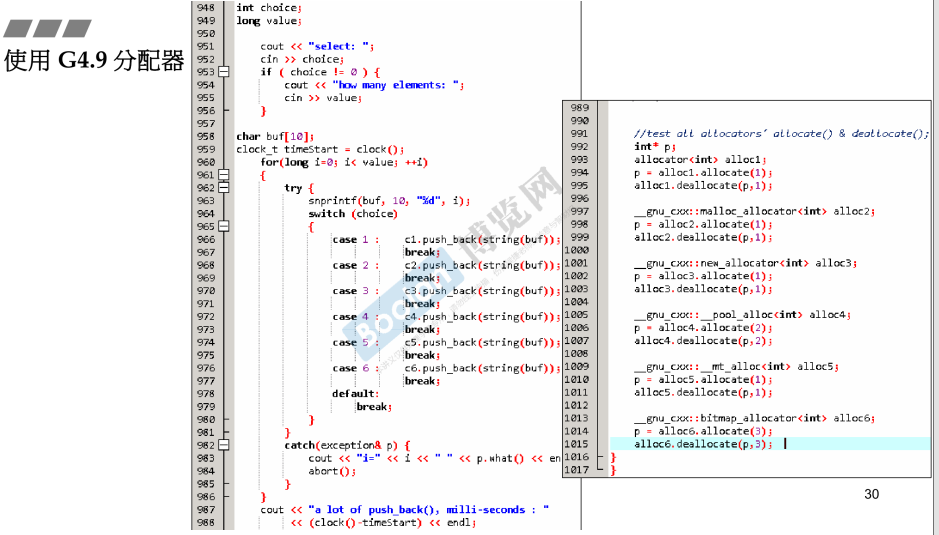
第六讲 补充
6.1 谈谈const

- 当const处于这种位置中:
- 意图是修饰成员函数,这个成员函数不打算修改类中的数据;
- 一般全局函数是不可以const这个位置的;
- 加不加const很重要!!

- const对象不可以调用non-const成员函数;
- 例如图中的例子,const string对象,本来就应该可以调用本是const的print,如果自己的写的print没有const,设计就不好;
- 右侧标准库中string有两个重载的成员函数,const和非const版本,
- 引用reference,共享同一个内存内容,(数据变化怎么办);
- 如果有一个共享要修改,那就拷贝单独一份,修改;
- []有可能会被修改,因此
COW:Copy on Write- 如果是常量字符串,是不必考虑COW,就使用const分开两种情况,是否考虑COW;
- 因为const和非const都可以调用const版本,因此还有一个规则:
- 当成员函数的const和non-const版本同时存在,const只能调用const;non-const只能调用non-const;
6.2 new和delete
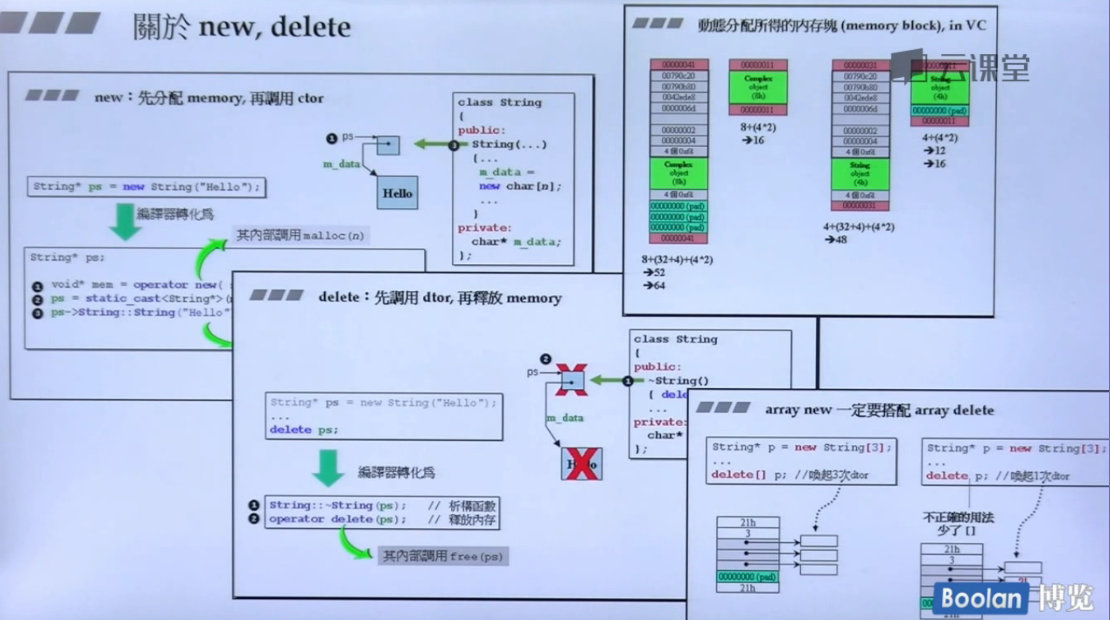
- new和delete是表达式,是不可以重载修改的,但是它们分解动作operator::new和operator::delete是可以重载的;
- 如何重载?
- 1、重载的全局operator::new和operator::delete
- new和delete是表达式,是不可以重载修改的,但是它们分解动作operator::new和operator::delete是可以重载的;
- 如何重载?
- 1、重载的全局operator::new和operator::delete

- 重载成员函数operator::new和operator::delete

- 重载成员函数operator new[]/delete[]
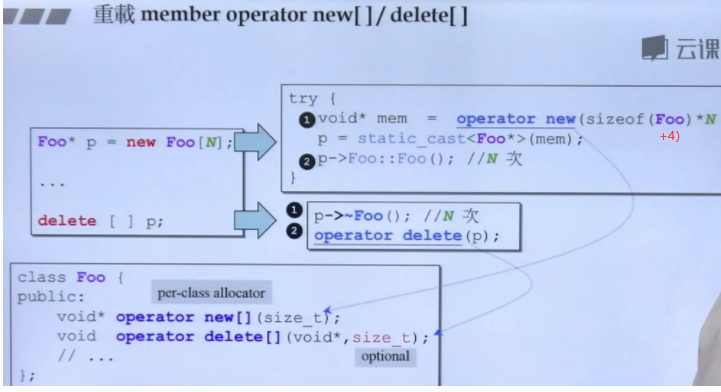
- 实例,接口
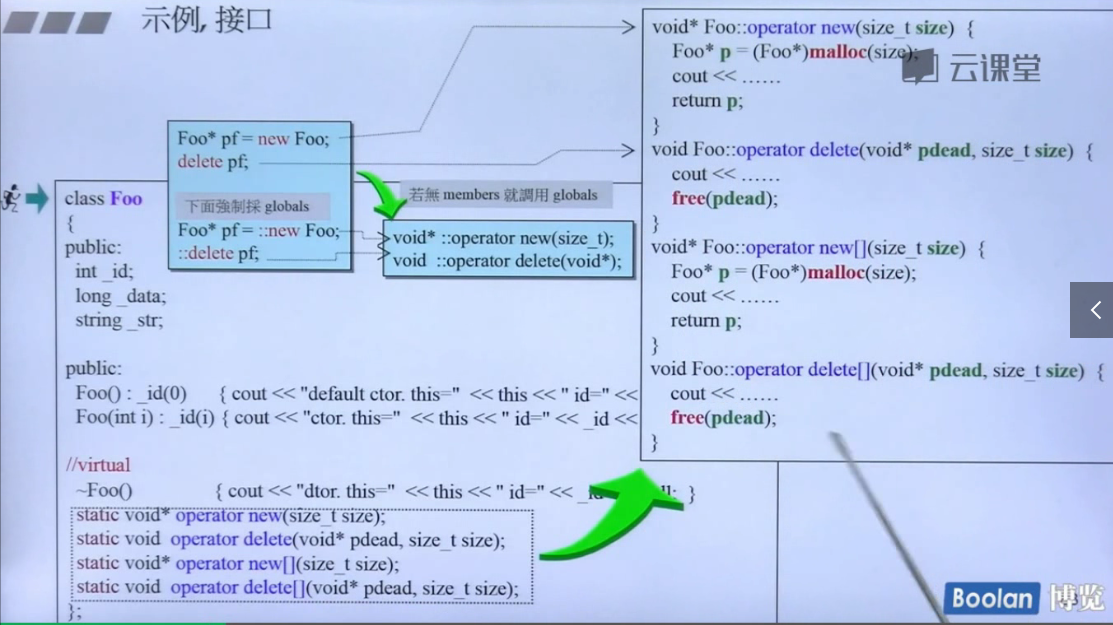
- 如果刻意要绕过重载版本,指定使用全局函数,可以加上::全局作用域指定!














 4560
4560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









