









C++编程语言
数据类型
整型
没有小数部分的数字
类型 Short、int、long、long long
标准:
short 至少16位 ,2个字节
int至少与short一样长
long 至少32位,且至少与int一样长
long long至少64位,且至少与long一样长
表示无符号类型使用unsigned来修饰
unsigned 本身是unsigned int 的说缩写。
整形字面值:
显示书写的常量如 520 ,前两位为0X表示16进制,第一位是0,第二位是1~7 表示8进制。
位与字节:
8位单元可表示0256或者-128127 每增加以为,组合数值加倍
字节指8位的内存单元
16位int表示的范围 -32768~+32767 或者 0~65536 (无符号)
sizeof运算符返回类型或变量长度,单位为字节
char类型
char类型专为存储字符而设计
char占8位,一个字节。
对字符使用单引号,对字符串使用双引号
ascll码表:
wchar_t 宽字符类型,一般用于表示扩展字符集
wchar_t是一种整数类型,可以表示系统使用的最大扩展字符集。
c++11新增类型:char16_t char32_t
无符号,长16位和32位。
使用前缀u表示char16_t ,使用前缀U表示char32_t 。u’c’, U’C’;
浮点数
能够表示带有小数部分的数
类型:
float、 double 、long double
有效位数不依赖于小数点的位置
位数:
float至少32位
double至少48位,且不少于float
long double 至少和double一样多
三类型的有效位数可以一样多。
通常:float位32位,double为64位
long double 为80,96或128位
运算语句
逻辑运算
逻辑表达式
逻辑运算符将关系表达式或逻辑量连接起来的有意义的式子称为逻辑表达式
逻辑OR运算符:||
表达式中任何一个或者全为true 则表达式为true
逻辑AND运算符:&&
将两个表达式组合成一个表达式,仅当两个表达式都为true时,得到的表达式值才为true。
逻辑NOT运算符:!
将后面的表达式真值取反
运算优先级
OR和AND的优先级低于关系运算符
!的优先级高于所有的关系和算术运算符
AND的运算符优先级高于OR运算符。
从左向右计算逻辑表达式
运算符分类
- 算数运算符:*, — ,+ ,/ ,%
- 关系运算符:> ,< ,==, != ,>= ,<=
- 逻辑运算符:!, && ,||
- 位运算符:<<,>>,~,|.^,&
- 赋值运算符:=级扩展运算符
- 条件运算符:?
- 逗号运算符:,
- 指针运算符:*,&
- 求字节数运算符:sizeof
- 强制类型转化运算符:(类型)
- 分量运算符(成员指示符):.,->
- 下标运算符:[]
运算符优先级
第一级:() [] -> . 右结合性
第二级:【!】 【~】 【++ --】 【-】(负号运算符 ) ,类型转化【()】,指针和取地址【* &】长度【sizeof】单目运算符 右结合性
第三级:* / %
第四级:+ -
第五级:<< >>
第六级:关系运算符【< > <= >=】
第七级:等于【==】不等于【!=】
第八级:按位与【&】
第九级:按位异或【^】
第十级:按位或 【|】
第十一级:逻辑与 &&
第十二级:逻辑或 ||
第十三级:条件运算符 ? 三目运算 右结合性
第十四级:赋值运算符【= += -= /= %= >>= <<= &= |= ^=】 右结合性
第十五级:逗号运算符 ,
位运算符
& 按位与
| 按位或
^ 按位异或
~ 取反
<< 左移
>> 右移
& 参与运算的两数的各对应二进制数相与,对应二进制位均为1才为1,否则为0
| 参与运算的两数的各对应二进制数相或,对应二进制位有1就为1,全为0才为0
^ 参与运算的两数的各对应二进制数相异或,对应二进制位相异为1
~ 取反,单目运算符,对参与运算的数的各二进制位按位取反
<< 左移n位就是乘以2的n次方,功能把左边的运算数的各二进位全部左移若干位,由右边的数指定移动的位数,高位丢弃,低位补0。例如 a<<4,将a各位左移4位。
>> 右移 右移n位就是除以2的n次方 对于有符号数,在右移时,符号位将随同移动。当为正数时, 最高位补0,而为负数时,符号位为1,最高位是补0或是补1 取决于编译系统的规定
三目运算符
b? x:y
先计算条件b,b为yure,则结果为x的值,否则为y的值。
逗号运算符
当顺序点用,结合顺序是从左至右,用来顺序求值,完毕之后整个表达式的值是最后一个表达式的值。
求解过程:首先计算它的每一个操作数,然后返回最右边操作数作为整个操作的结果
例:x=(y=3,(z = ++y+2) +5);
是首先把y赋值为3,把y递增为4,然后把4加上2,把结果6赋值给z,接下来把z加5最后把
x赋为结果值11.
函数
友元函数
达到类的接口扩展作用
让函数称为类的友元可以赋予该函数与类的成员函数相同但访问权限。
创建友元函数:
一:将函数原型放在类声明中,并在原型声明前加上关键字friend:
friend Time operator*(double m,const Time &t) ;
-
虽然此函数在类声明中定义,但不是成员函数,不能使用成员运算符来调用
-
虽然不是成员函数,但是与成员函数访问权限相同
二:编写定义
因为不是成员函数,不能使用::限定符,在定义中不使用关键字friend
函数指针
一个函数也有地址,函数的地址是存储其机器语言代码的内存的开始地址,可以编写一个将函数的地址作为参数的函数,这样此函数可以通过地址找到作为参数的函数并运行它。作用:可以运行在不同的时间段传递不同的参数,这样可以在不同的时间使用不同的函数。
过程:
- 获取函数的地址
- 声明一个函数指针
- 使用函数指针来调用函数
1、获取函数地址 : 使用函数名 不带括号和参数即可。 使用think作为参数传递的是函数地址,使用think()作为参数传递的是函数的返回值
2、声明函数指针 : 声明指向函数的指针时,必须指定指针指向的函数类型。声明应指明函数的返回类型以及参数列表
le:
double pam(int);//原型
double (*pf)(int);//函数指针
pf=pam;//将函数的首地址赋值给指针变量
//保证运算符优先级正确,必须在声明中使用括号将*pf括起来,括号优先级比*高,*pf(int)表示pf()是一个返回指针的函数,(*pf)(int)表示pf是一个指向函数的指针。
//使用函数指针
void estime (int lins,double (*pf)(int));//原型声明
estime(10,pam);//使用
3、使用函数指针来调用函数 : 使用指针来调用被指向的函数 (*pf)与函数名相同,将(*pf)看作函数名来使用。
ps:指向函数的指针变量没有 ++ 和 – 运算
深入函数指针:
有如下原型函数
const double * f1(const double ar[],int n);
const double * f2(const double *ar,int n);
const double * f3(const double *,int n);
//此三个函数原型其实特征标(参数)完全相同。
//const double ar[]与const double *ar含义完全相同
//函数原型中可省略标识符,const double ar[]可以简化为const double [],const double *ar可简化为const double *;
//上面三个特征标都可简化为const double *,或者const double [];
声明指针函数:
const double * (*p1)(const double *,int n);//返回类型 double*
const double * (*p1)(const double *,int n)=f1;//声明时初始化
//使用自动类型推断
auto p2=p1;
//这里使用多个函数,使用函数指针数组将很方便。
const double * (*pa[3])(const double *,int n)={f1,f2,f3};//使用函数指针数组并初始化
auto pb=pa;
//数组名是指针第一个元素的指针,因此pa,pb都是指向函数指针的指针。
double numa=*pa[0](av,3);
double numb=*(*pb[1])(av,3);//获取double 的值
//创建指向整个数组的指针
const double *(*(*pd)[3])(const double *,int)=&pa;
auto pc=&pa;
//pd指向数组,*pd就是数组,(*pd)[i]为数组的元素,即为函数指针。
//调用一
(*pd)[i](av,3);//简单函数调用
*(*pd)[i](av,3);//返回指针所指向的值
//调用二
(*(*pd)[i])(av,3);//函数调用
*(*(*pd)[i])(av,3);//指向double的值
上面pa和&pa的差别 pa(数组名,表示地址)是数组第一个元素地址,即&pa[0]; &pa表示整个数组,即三个指针块地址。
两者数字上相同,但是类型不同,pa+1为数组下一元素地址,&pa+1为数组后面一个12字节内存块地址。
要得到第一个元素的值,只需要对pa进行一次解除引用,对&pa需要两次。
内存
动态内存
在C++程序中,所有内存需求都是在程序执行之前通过定义所需的变量来确定的。 但是可能存在程序的内存需求只能在运行时确定的情况。 例如,当需要的内存取决于用户输入。 在这些情况下,程序需要动态分配内存,C ++语言将运算符new和delete合成在一起
特点
| 1.C++中通过new关键字进行动态内存申请 |
|---|
| 2.C++中的动态内存分配是基于类型进行的 |
| 3.delete关键字用于内存释放 |
new 和 delete 原型
c++语言标准库的库函数,原型如下:
void *operator new(size_t); //allocate an object
void *operator delete(void *); //free an object
void *operator new[](size_t); //allocate an array
void *operator delete[](void *); //free an array
new
new其实就是告诉计算机开辟一段新的空间,但是和一般的声明不同的是,new开辟的空间在堆上,而一般声明的变量存放在栈上。通常来说,当在局部函数中new出一段新的空间,该段空间在局部函数调用结束后仍然能够使用,可以用来向主函数传递参数。另外需要注意的是,new的使用格式,new出来的是一段空间的首地址。所以一般需要用指针来存放这段地址。
new的完成机制
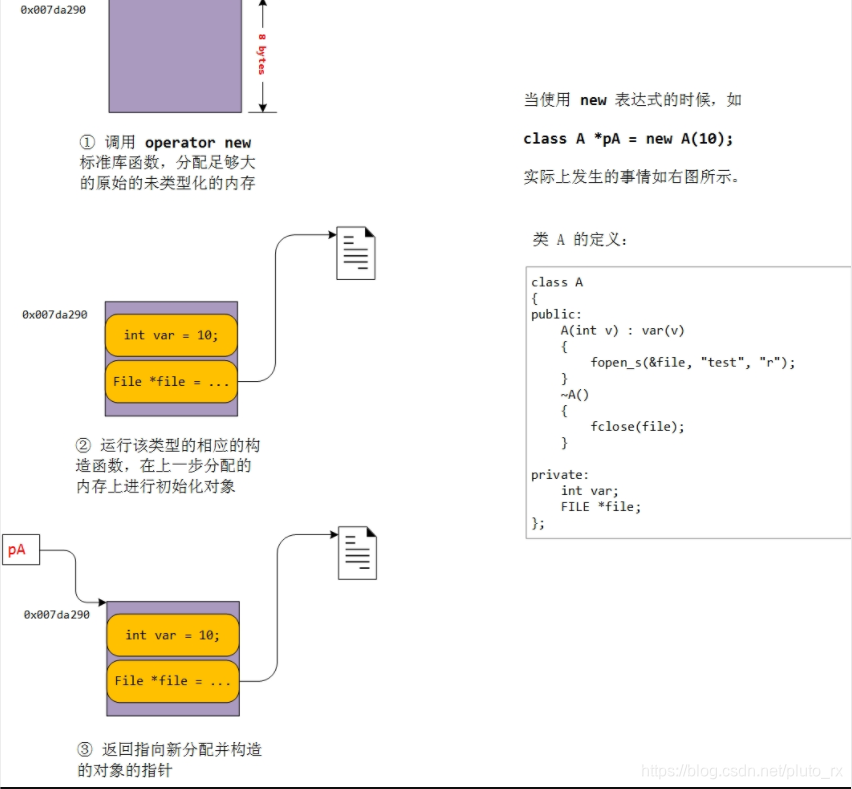
过程:
-
首先需要调用上面提到的 operator new 标准库函数,传入的参数为 class A 的大小,这里为 8 个字节,。这样函数返回的是分配内存的起始地址,这里假设是 0x007da290。
-
上面分配的内存是未初始化的,也是未类型化的,第二步就在这一块原始的内存上对类对象进行初始化,调用的是相应的构造函数,这里是调用
A:A(10);这个函数,从图中也可以看到对这块申请的内存进行了初始化,var=10, file 指向打开的文件。 -
最后一步就是返回新分配并构造好的对象的指针,这里 pA 就指向 0x007da290 这块内存,pA 的类型为类 A 对象的指针。
delete
使用delete释放内存
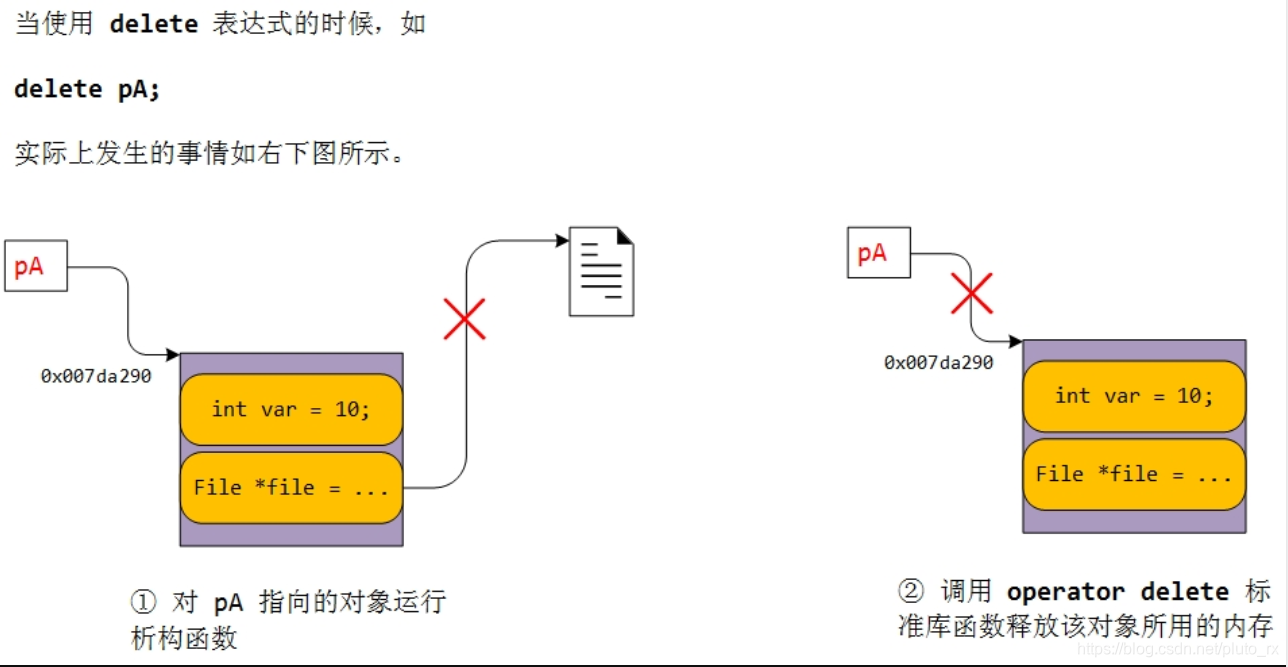
delete 做了两件事情:
-
调用 pA 指向对象的析构函数,对打开的文件进行关闭。
-
通过上面提到的标准库函数 operator delete 来释放该对象的内存,传入函数的参数为 pA 的值,也就是 0x007d290。
new/delete 和 new[]/delete[] 的使用
★最好配套使用
申请数组
string *psa = new string[10]; //array of 10 empty strings
int *pia = new int[10]; //array of 10 uninitialized ints
上面在申请一个数组时都用到了 new [] 这个表达式来完成,第一个数组是 string 类型,分配了保存对象的内存空间之后,将调用 string 类型的默认构造函数依次初始化数组中每个元素;第二个是申请具有内置类型的数组,分配了存储 10 个 int 对象的内存空间,但并没有初始化。
释放数组:
delete [] psa;
delete [] pia;
这里有一个问题:
我们如何知道 psa 指向对象的数组的大小?怎么知道调用几次析构函数?
这个问题直接导致我们需要在 new [] 一个对象数组时,需要保存数组的维度,C++ 的做法是在分配数组空间时多分配了 4 个字节的大小,专门保存数组的大小,在 delete [] 时就可以取出这个保存的数,就知道了需要调用析构函数多少次了。
★
使用 new [] 用 delete 来释放对象的提前是:对象的类型是内置类型或者是无自定义的析构函数的类类型 例如int
类
类成员
成员变量可以是任何类型,如基本数据类型、引用、另一个类的对象或指针、自身类的引用或指针,但不能是自身类的对象;
成员变量不能指定为auto、register、extern 存储类型。
普通成员
普通成员变量是属于对象的,其生命周期就是对象的生命周期,只能通过构造函数的初始化列表进行初始化,也可以在构造函数中赋值。
如果是成员变量是一个类的对象,那么只能并且必须使用初始化列表。
静态成员(static)
静态成员变量是属于整个类的,整个类(所有类的对象中)只有一份拷贝,相当于类的全局变量(这是对于同一进程内而言, 多进程间无效)。
静态成员变量不能在类的内部初始化,在类的内部只是声明,定义必须在类外 ,定义时不能加上static关键字,
静态类成员:无论创建多少对象,程序程序都只创建一个静态类变量副本,类的所有变量共享一个静态类成员
定义时可以指定初始值,也可以不指定,不指定时系统默认其初始值为0.
静态成员变量同样遵守public\private\protected限定,当静态成员变量是公有成员时可以使用类名::静态成员变量名或者对象名.静态成员变量名
常量成员(const)
const成员变量是属于对象的,其生命周期就是对象的生命周期,在这个生命周期中其值是不可改变的。
常成员变量不能在类的内部初始化,在类的内部只是声明,只能通过构造函数的初始化列表进行初始化,并且必须进行初始化。
常变量只能初始化不能赋值,所以在构造函数中赋值,或者使用自定义的成员函数赋值 都是错误的。
静态常量成员(const static)
成员变量在整个类中不可变
就是将 常成员变量 和 静态成员变量 结合起来,使用const static 或者 static const定义变量,注意2者没有区别。当然使用enum定义也是很好的方法。
常静态成员变量有2种初始化的方式,1种是在类内(声明时)初始化,另一种是在类外初始化,类外初始化时要加const限定不能加static限定。
对象成员
当类的成员是其他对象是,称该成员为对象成员,构造顺序:先调用对象成员构造函数,再调用本类的构造函数
析构顺序相反。
类成员函数
把定义和原型写在类定义内部的函数,就像类定义中的其他变量一样。类成员函数是类的一个成员,它可以操作类的任意对象,可以访问对象中的所有成员。
普通成员函数:
普通成员函数可以访问该类的所有成员变量 和 成员函数。
常成员函数(const)
将函数设置为常成员函数,可以禁止成员函数修改数据成员。
设置的方法是在函数的参数列表后面加上const,注意类内声明和类外定义都要加const限定。
void SetInt(int a)const;
静态成员函数(staitc):
静态成员函数是属于整个类的,它只能访问该类的静态成员变量 和 其他静态成员函数。
友元类
友元函数是指某些虽然不是类成员函数却能够访问类的所有成员的函数。类授予它的友元特别的访问权,这样该友元函数就能访问到类中的所有成员。
友元类:
友元类的所有成员函数都是另一个类的友元函数,都可以访问另一个类中的隐藏信息(包括私有成员和保护成员)。当希望一个类可以存取另一个类的私有成员时,可以将该类声明为另一类的友元类。
(1) 友元关系不能被继承。
(2) 友元关系是单向的,不具有交换性。若类B是类A的友元,类A不一定是类B的友元,要看在类中是否有相应的声明。
(3) 友元关系不具有传递性。若类B是类A的友元,类C是B的友元,类C不一定是类A的友元,同样要看类中是否有相应的申明。
友元成员函数:
使类B中的成员函数成为类A的友元函数,这样类B的该成员函数就可以访问类A的所有成员了。
当用到友元成员函数时,需注意友元声明和友元定义之间的相互依赖,即类的定义顺序。 当遇到循环依赖时,此时需要使用前向声明
例如有两个类 一个Tv类,一个遥控器类Remote,在Tv类中将Remote的一个方法设置为友元
class Tv{
friend void Remode::set_chan(Tv &t,int c)
}
要能够编译通过,编译器必须要知道Remote的定义。这需要将Remote定义在Tv前面,但是在Remote的方法中提到了Tv,意味着Tv要定义在Remote前面,造成了循环依赖。
使用前向声明
class Tv;//前向声明
class Remote{......};
class Tv{......};
嵌套类
将类声明放在另一个类中;声明于另一个类中的类称之为嵌套类,声明的类称之为包含类。
包含类的成员函数可以创建和使用嵌套类的对象。
只有声明与公有部分,才能在包含类外使用嵌套类,并且必须使用作用域解析运算符。
作用域:
| 嵌套类 | 结构 | 枚举 | |
|---|---|---|---|
| 声明位置 | 包含它的类是否可以使用它 | 从包含它的类派生而来的类是否可以使用它 | 在外部是否可以使用 |
| 私有部分 | 是 | 否 | 否 |
| 保护部分 | 是 | 是 | 否 |
| 公有部分 | 是 | 是 | 是,通过类限定符来使用 |
类声明的位置决定了类的作用域或可见性,在类可见后,访问控制规则(公有,私有,保护,友元)将决定程序对嵌套类成员的访问权限。
String 类
string由头文件string支持
string构造函数实例:(7大构造函数)
#include <string>
int main()
{
using namespace std;
string one(" hello c++");//将string对象初始化为常规c-风格字符串
cout<<one<<endl;
string two(20,"s");//将string对象two初始化为20个s组成的字符串
cout<<two<<endl;
string three(one);//复制构造函数将three初始化为string对象one
cout<<three<<endl;
one+="oops";//重载运算符+=
/*+=被多次重载,可以附加string对象,c-风格字符串和单个字符
=运算符也被重载,可以将string对象,c-风格字符串或char值赋值给string对象
*/
cout<<one<<endl;
two="sorry that was";
three[0]='p';//重载[]运算符,可以使用数组表示法来访问string对象中的各个字符
string four;//默认构造函数创建一个以后可以对其赋值的空字符串
four=two+three;//重载+运算符
cout<<four<<endl;
char alls[]="All well that ends well";
string five(alls,20);//参数为c-风格字符串和一整数,整数表示要复制多少字符,整数超过字符串长度部分会复制无用字符到five后面
cout<<five<<endl;
string six(alls+6,alls+10);
/*参数模板 template<class Item>string (Item begin,Item end);
构造函数使用begin和end直接的值,其范围为[begin,end),
这里alls为数组名,相当于指针 alls类型为char*
若 string six(five+6,five+10)将发生错误,以为对象名不能看作对象的地址
*/
cout<<six<<endl;
string seven(&five[6],&five[10]);//&five[6]是一个地址,符合上述要求
cout<<seven<<endl;
string eigth(four,7,16);//将一个string对象的部分类容复制到构造的对象中 从位置7开始将16个字符复制到eigth中。
cout<<eight<<"in motion!";
return 0;
}
c++11新增构造函数
string ( string && str)
类似于复制构造函数,导致新创建的string为str的副本,但是不保证将str视为const;
string ( initializer_list<char> il )
这样可以使用列表初始化语法用于string类
例如:string piano={‘L’, ‘i’ , ‘s’ , ‘z’ , ‘t’ };
string类的输入
string buffer;
cin>>buffer;
getline(cin,buffer);
getline()有个可选参数,用来指定使用哪个字符来确定输入边界
getline(buffer , ‘:’ ); 使用:作为边界
字符串使用
使用关系运算符进行比较
string对6个关系运算符都进行了重载 > ,< ,==, != ,>= ,<=
能够将string对象与另一个string对象,c-风格字符串进行比较
确定字符串的长度
成员函数 length() 和size() ,都返回字符串中的字符数
str.length() str.size()
find()方法,用于查找字符子串和字符
string类提供了6种查找函数,每种函数以不同形式的find命名。这些操作全都返回string::size_type类型的值,以下标的形式返回匹配的位置。当没有匹配到时返回一个string::npos的特殊值。npos定义为保证大于任何有效的下标值。
/*string类型的查找操作,其参数args在下表*/
s.find(args); 在s中查找args的第一次出现
s.rfind(args); 在s中查找args的最后一次出现
s.find_first_of(args); 在s中查找args的任意字符的第一次出现
s.find_last_of(args); 在s中查找args的任意字符的最后一次出现
s.find_first_not_of(args); 在s中查第一个不属于args的字符
s.find_last_not_of(args); 在s中查找最后一一个不属于args的字符
string字符处理
我们经常要对string对象的单个字符进行处理,在cctype头文件中包含了各种字符操作函数。下面列出了这些函数:
isalnum(c); 如果c是数字或字母,则为true
isalpha(c); 如果c是字母,则为true
iscntrl(c); 如果c是控制字符,则为true
isdigit(c); 如果c是数字,则为true
isgraph(c); 如果c不是空格,但可打印,则为true
islower(c); 如果c是小写字母,则为true
isprint(c); 如果c是可打印的字符,则为true
ispunct(c); 如果c是标点符号,则为true
isspace(c); 如果c是空白字符,则为true
isupper(c); 如果c是大写字母,则为true
isxdigi(c); 如果c是十六进制,则为true
tolower(c); 返回其小写字母形式
toupper(c); 返回其大写字母形式
append和replace函数
string类型提供了容器类型不支持的几种操作:append、replace、substr和一系列find函数。
其中append和replace函数用于修改string对象。
append操作提供了在字符串尾部插入的捷径。
replace操作用于删除指定一段范围内的字符,然后在删除位置插入一组新字符,等效于调用insert和erase函数。
/*修改string对象的操作*/
s.append(args); 将args串接在s后面。返回s的引用
s.replace(pos,len,args); 删除s中从下标pos开始的len个字符,用args指定的字符替换之,返回s的引用
s.replace(b,e,args); 删除迭代器b和e标记的范围内所有的字符,用args替换它。返回s的引用
string子串
子串操作substr函数
使用substr操作可以在指定的string对象中检索需要的子串。
- s.substr(pos,n); 返回一个string类型的字符串,它包含从s从下标pos开始的n个字符
- s.substr(pos); 返回一个string类型的字符串,它包含从下标pos开始到s的末尾的所有字符
- s.substr(); 返回s的副本
常用操作
string对象的常用操作。
s.empty(); 如果s为空串,则返回true,否则返回false
s.size(); 返回s中字符的个数
s[n]; 返回s中位置为n的字符,从0开始计数
s1+s2; 把s1和s2拼接成一个新的字符串,返回新生成的字符串
s1=s2; 把s1的内容替换为s2的一个副本
s1==s2; 比较s1和s2的内容,相等则返回true,否则返回false
!=,<,<=,>和>= 保持这些操作符惯有的含义
比较操作
compare函数用于实现string类型的字典顺序的比价
ompare返回下面是三种可能之一:
- 正数,此时s1大于args所代表的string对象。
- 负数,此时s1小于args所代表的string对象。
- 0,相等。
s.compare(s2); 比较s和s2
s.compare(pos1,n1,s2); 让s中从pos1下标位置开始的n1个字符与s2做比较
s.compare(pos1,n1,s2,pos2,n2); 让s中从pos1下标位置开始的n1个字符与s2中从pos2开始的n2个字符相比较
s.compare(cp); 比较s和cp所指向的以空字符结束的字符串
s.compare(pos1,n1,cp); 让s中从pos1下标位置开始的n1个字符与cp所指向的以空字符结束的字符串比较
s.compare(pos1,n1,cp,n2); 让s中从pos1下标位置开始的n1个字符与cp所指向的字符串的前n2个字符串比较
智能指针模板类
头文件包含 <memory>
三大智能指针
auto_ptr、unique_ptr、shared_ptr
定义了类似指针的对象,可以将new获得的地址赋值给这种对象,当智能指针过期时,其析构函数将使用detele来释放内存。
使用:
using namespace std;
auto_ptr<double> pd(new double);
auto_ptr<string> ps(new string);
unique_ptr<double> pdd(new double);
shared_ptr<string> pss(new string);
智能指针模板位于名称空间std中;
所有智能指针都有一个explicit构造函数,该构造函数将指针作为参数,因此不需要自动将指针转化为智能指针对象。
代码重用
当您调用一个重载函数或重载运算符时,编译器通过把您所使用的参数类型与定义中的参数类型进行比较,决定选用最合适的定义。选择最合适的重载函数或重载运算符的过程,称为重载决策。
操作符重载
扩展C++中提供的运算符的适用范围,以用于类所表示的抽象数据类型。同一个运算符,对不同类型的操作数,所发生的行为不同。
操作符重载的基本前提:
1.只能为自定义类型重载操作符;
2.不能对操作符的语法(优先级、结合性、操作数个数、语法结构) 、语义进行颠覆;
3.不能引入新的自定义操作符。
| 可重载运算符 | |
|---|---|
| 双目算术运算符 | + (加),-(减),*(乘),/(除),% (取模) |
| 关系运算符 | ==(等于),!= (不等于),< (小于),> (大于),<=(小于等于),>=(大于等于) |
| 逻辑运算符 | ||(逻辑或),&&(逻辑与),!(逻辑非) |
| 单目运算符 | + (正),-(负),*(指针),&(取地址) |
| 自增自减运算符 | ++(自增),–(自减) |
| 位运算符 | | (按位或),& (按位与),~(按位取反),^(按位异或),,<< (左移),>>(右移) |
| 赋值运算符 | =, +=, -=, *=, /= , % = , &=, |=, ^=, <<=, >>= |
| 空间申请与释放 | new, delete, new[ ] , delete[] |
| 其他运算符 | ()(函数调用),->(成员访问),,(逗号),[](下标) |
不可重载的运算符列表:
- .:成员访问运算符
- .*, ->*:成员指针访问运算符
- :::域运算符
- sizeof:长度运算符
- ?::条件运算符
- #: 预处理符号
要求:
它们与基本类型用操作符表示的操作、与其他用户自定义类型用操作符表示的操作之间不存在冲突与二义性
运算符重载的方法是定义一个重载运算符的函数,在需要执行被重载的运算符时,系统就自动调用该函数,以实现相应的运算。**从某种程度上看,运算符重载也是函数的重载。**但运算符重载的关键并不在于实现函数功能,而是由于每种运算符都有其约定俗成的含义,重载它们应是在保留原有含义的基础上对功能的扩展,而非改变。
函数格式
函数类型 operator 运算符名称 (形参表列)
{
对运算符的重载处理
}
实质操作符的重载就是函数的重载,在程序编译时把指定的运算表达式转换成对运算符的调用,把运算的操作数转换成运算符函数的参数,根据实参的类型决定调用哪个操作符函数。
对于单目运算符++和–有两种使用方式,前置运算和后置运算,它们是不同的。针对这一特性,C++约定:如果在自增(自减)运算符重载函数中,无参数表示前置运算符函数,若加一个int型形参,就表示后置运算符函数。
Complex operator ++();//前缀自增
Complex operator ++(int);//后缀自增,参数需要加int
Complex operator++(int);中,注意有个int,在这里int并不是真正的参数,也不代表整数,只是一个用来表示后缀的标志!!
运算符重载的函数一般地采用如下两种形式:成员函数形式和友元函数形式。这两种形式都可访问类中的私有成员。
友元函数是一种对面对对象程序中类的破坏,可以访问私有成员。
friend函数类型 operator 运算符名称 (形参表列)
{
对运算符的重载处理
}
类成员函数
对象作为参数进行传递,对象属性使用 this运算符进行访问:
Box operator+(const Box& b)
{
Box box;
box.length = this->length + b.length;
box.breadth = this->breadth + b.breadth;
box.height = this->height + b.height;
return box;
}
函数重载
是一种静态多态
函数重载是一种特殊情况,C++允许在同一作用域中声明几个类似的同名函数,这些同名函数的形参列表(参数个数,类型,顺序)必须不同,常用来处理实现功能类似数据类型不同的问题。
注意:重载函数的参数个数,参数类型或参数顺序三者中必须有一个不同
函数重载的规则:
- 函数名称必须相同。
- 参数列表必须不同(个数不同、类型不同、参数排列顺序不同等)。
- 函数的返回类型可以相同也可以不相同。
- 仅仅返回类型不同不足以成为函数的重载。
作用:重载函数通常用来在同一个作用域内 用同一个函数名 命名一组功能相似的函数,这样做减少了函数名的数量,避免了名字空间的污染,对于程序的可读性有很大的好处。
代码重写
也叫代码覆盖
是指在派生类中重新对基类中的虚函数(注意是虚函数)重新实现。
函数名和参数都一样,只是函数的实现体不一样。
特征:
(1)不同的范围(分别位于派生类与基类);
(2)函数名字相同;
(3)参数相同;
(4)基类函数必须有virtual 关键字。
隐藏
隐藏是指派生类中的函数把基类中相同名字的函数屏蔽掉了。这里是普通函数,不是基函数。
规则:
(1)如果派生类的函数与基类的函数同名,但是参数不同。此时,不论有无virtual关键字,基类的函数将被隐藏(注意别与重载混淆)。
(2)如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual 关键字。此时,基类的函数被隐藏(注意别与覆盖混淆)
异常
c++在运行阶段遇到的错误
异常处理
abort()函数
向标准错误流发送消息abnormal program termination(程序异常终止),然后终止程序。
在程序中调用abort()函数将直接终止程序。
返回错误码
可使用函数的返回值来指出问题,在任何数值的返回值都是有效值时,可使用指针参数或引用参数来将值返回给调用程序,并使用函数的返回值来指出成功还是失败。
异常机制
异常处理的三个组成部分
- 引发异常
- 使用处理程序捕获异常
- 使用try块
处理语句
throw:
throw语句作用为跳转,即命令程序跳转到另一语句。throw关键字表示引发异常,后面跟随的值(字符串或对象)指出异常的特征。throw将终止函数的执行,导致程序沿函数调用序列后退,知道找到包含try块的函数。
try/catch块:
使用异常处理程序捕获异常,catch关键字表示捕获异常,随后位于括号内的是类型声明,指出异常处理程序要响应的异常类型;花括号的代码块指出要采取的措施。
try块标识其中特定的异常可能被激活的代码块,表明需要注意这些代码引发的异常。
int main()
{
.......
try {
z=hmean(x,y);
}
catch(const char *s)
{
cout<<s<<endl;
continue;
}
}
double hmean(double a,double b){
if(a==-b)
throw "bad hmean() argument :a=-b not allowed";
return 2.0*a*b/(a+b);
}
异常处理过程:当传入值为-1和1时,if语句导致hmean()引发异常,终止hmean()的执行,throw抛出异常为字符串(类型char *),并向后搜索发现heman()函数从main中的try块中调用,因此程序查找与异常类型匹配的catch块;程序中catch块的参数为char*,与引发异常匹配,将throw抛出的值赋值给变量s,然后执行处理程序中的代码。
将对象作为参数类型
添加异常类bad_hmean和bad_gmean, megs()用于报告问题,以及另一个函数gmean();
class bad_hmean{
private:
double v1;
double v2;
public:
bad_hmean(int a=0,int b=0):v1(a),v2(b){}
void mesg();
}
inline void bad_hmean::mesg()
{
......
}
异常捕获,根据异常类型,采取相应措施
try{
...
}
catch(bad_hmean &hg)//捕获由hmean()引发的异常
{......
}
catch(bad_gneam &bg)//捕获由gmean()引发的异常
{
.......
}
//
if(a==-b)
throw bad_hmean(a,b);
栈解退
函数的调用和返回机制:
c++一般通过将信息放在栈中来处理函数调用。
程序将调用函数的指令的地址放入栈中,当被调用的函数执行完毕后,将使用该地址来确定从哪里开始继续执行。
函数调用将函数参数放入栈中,这些函数参数被视为自动变量,如果被调用的函数创建了新的自动变量,这些变量也会被添加进栈中。
被调用的函数调用另一个函数,则后者的信息将被添加到栈中。
当函数结束时,程序流程将跳到该函数被调用时存储的地址处,同时栈顶元素被释放。
因此 函数通常都返回到调用它的函数。
栈解退过程:
若函数出现异常终止,程序释放栈的内存,在释放栈第一个地址后不停止,继续释放栈,直到找到一个位于try块中的返回地址,然后将控制权将转到块尾的异常处理程序。
对于栈中的自动类对象,类的析构函数将被调用。
异常向上抛出
例如 函数中的try块只能处理一个异常,main()中的try块可以处理多种异常,在函数中捕获到异常后,可以在使用throw,重新引发异常,这将向上把异常发送给mian()函数
重新引发的异常将由下一个捕获这种异常的try-catch块组合进行处理。
捕获任何异常
catch(...){//使用...来捕获任何异常
}
exception类
包含一个虚函数what(),返回一个字符串,该字符串特征随实现而异。
头文件stdexcept定义了几种异常类
logic_error类 描述典型逻辑错误
- domain_error 域错误
- invalid_argument 无效参数
- length_error 没有足够的空间来执行操作
- out_of_bounds 指示引索错误
runtime_error 描述运行时发生但难以预料和防范的错误
- range_error 计算结果可能不在允许的范围内,但没有发生上溢或下溢错误时使用
- overflow_error 上溢 计算结果超出某种类型能够表示的最大数量级时,发生上溢错误
- underflow_error 下溢,浮点类型存在可表示的最小非零值,计算结果比这个还小导致下溢
new 引发的内存分配问题
让new引发bad_alloc异常,有文件new包含bad_alloc类声明,从exception类公有派生得到。
#include <new>
struct BIg{
double stuff[200000];
}
int main()
{
BIg *big;
try{
big=new BIG[10000];
}
catch(bad_alloc &ba){
cout<<ba.what();
exit(EXIT_FALLURE);
}
.....
}
其他
c++四大强制转化
c-风格的强制转换如下
TypeName b = (TypeName)a;
下面是c++提供的在不同场合使用的强制转换函数
static_cast
enable :static_cast 用于进行比较“自然”和低风险的转换,如整型和浮点型、字符型之间的互相转换。另外,如果对象所属的类重载了强制类型转换运算符 T(如 T 是 int、int* 或其他类型名),则 static_cast 也能用来进行对象到 T 类型的转换。
**disable: **static_cast 不能用于在不同类型的指针之间互相转换,也不能用于整型和指针之间的互相转换,当然也不能用于不同类型的引用之间的转换。因为这些属于风险比较高的转换。
code:
#include <iostream>
using namespace std;
class A
{
public:
operator int() { return 1; }
operator char*() { return NULL; }
};
int main()
{
A a;
int n;
char* p = "New Dragon Inn";
n = static_cast <int> (3.14); // n 的值变为 3
n = static_cast <int> (a); //调用 a.operator int,n 的值变为 1
p = static_cast <char*> (a); //调用 a.operator char*,p 的值变为 NULL
n = static_cast <int> (p); //编译错误,static_cast不能将指针转换成整型
p = static_cast <char*> (n); //编译错误,static_cast 不能将整型转换成指针
return 0;
}
reinterpret_cast
reinterpret_cast 用于进行各种不同类型的指针之间、不同类型的引用之间以及指针和能容纳指针的整数类型之间的转换。转换时,执行的是逐个比特复制的操作。
特点:
转换提供了很强的灵活性,但转换的安全性只能由coder的细心来保证了。
code:
#include <iostream>
using namespace std;
class A
{
public:
int i;
int j;
A(int n):i(n),j(n) { }
};
int main()
{
A a(100);
int &r = reinterpret_cast<int&>(a); //强行让 r 引用 a
r = 200; //把 a.i 变成了 200
cout << a.i << "," << a.j << endl; // 输出 200,100
int n = 300;
A *pa = reinterpret_cast<A*> ( & n); //强行让 pa 指向 n
pa->i = 400; // n 变成 400
pa->j = 500; //此条语句不安全,很可能导致程序崩溃
cout << n << endl; // 输出 400
long long la = 0x12345678abcdLL;
pa = reinterpret_cast<A*>(la); //la太长,只取低32位0x5678abcd拷贝给pa
unsigned int u = reinterpret_cast<unsigned int>(pa);//pa逐个比特拷贝到u
cout << hex << u << endl; //输出 5678abcd
typedef void (* PF1) (int);
typedef int (* PF2) (int,char *);
PF1 pf1; PF2 pf2;
pf2 = reinterpret_cast<PF2>(pf1); //两个不同类型的函数指针之间可以互相转换
}
思想:用户可以做任何操作,但要为自己的行为负责。
const_cast
作用:
const_cast 运算符仅用于进行去除 const 属性的转换,它也是四个强制类型转换运算符中唯一能够去除 const 属性的运算符。
将 const 引用转换为同类型的非 const 引用,将 const 指针转换为同类型的非 const 指针
const string s = "Inception";
string& p = const_cast <string&> (s);
string* ps = const_cast <string*> (&s); // &s 的类型是 const string*
dynamic_cast
用 reinterpret_cast 可以将多态基类(包含虚函数的基类)的指针强制转换为派生类的指针,但是这种转换不检查安全性,即不检查转换后的指针是否确实指向一个派生类对象。
dynamic_cast专门用于将多态基类的指针或引用强制转换为派生类的指针或引用,而且能够检查转换的安全性。对于不安全的指针转换,转换结果返回 NULL 指针。
dynamic_cast 是通过**“运行时类型检查”**来保证安全性的。dynamic_cast 不能用于将非多态基类的指针或引用强制转换为派生类的指针或引用——这种转换没法保证安全性,只好用 reinterpret_cast 来完成。
#include <iostream>
#include <string>
using namespace std;
class Base
{ //有虚函数,因此是多态基类
public:
virtual ~Base() {}
};
class Derived : public Base { };
int main()
{
Base b;
Derived d;
Derived* pd;
pd = reinterpret_cast <Derived*> (&b);
if (pd == NULL)
//此处pd不会为 NULL。reinterpret_cast不检查安全性,总是进行转换
cout << "unsafe reinterpret_cast" << endl; //不会执行
pd = dynamic_cast <Derived*> (&b);
if (pd == NULL) //结果会是NULL,因为 &b 不指向派生类对象,此转换不安全
cout << "unsafe dynamic_cast1" << endl; //会执行
pd = dynamic_cast <Derived*> (&d); //安全的转换
if (pd == NULL) //此处 pd 不会为 NULL
cout << "unsafe dynamic_cast2" << endl; //不会执行
return 0;
}
dynamic_cast 在进行引用的强制转换时,如果发现转换不安全,就会拋出一个异常,通过处理异常,就能发现不安全的转换。
Derived & r = dynamic_cast <Derived &> (b);
标准库
C++ 标准库可以分为两部分:
- 标准函数库: 这个库是由通用的、独立的、不属于任何类的函数组成的。函数库继承自 C 语言。
- 面向对象类库: 这个库是类及其相关函数的集合。
标准函数库
I/O标准库
三大类型
IO 类型在三个独立的头文件中定义:iostream 定义读写控制窗口的类型,fstream 定义读写已命名文件的类型,而 sstream 所定义的类型则用于读写存储在内存中的 string 对象。
| header | type |
|---|---|
| iostream | istream 从流中读取; ostream 写到流中去 iostream 对流进行读写;从 istream 和 ostream 派生而来 |
| fstream | ifstream 从文件中读取;由 istream 派生而来 ofstream 写到文件中去;由 ostream 派生而来 fstream 读写文件;由 iostream 派生而来 |
| sstream | istringstream 从 string 对象中读取;由 istream 派生而来 ostringstream 写到 string 对象中去;由 ostream 派生而来 stringstream 对 string 对象进行读写;由 iostream 派生而来 |
如果函数有基类类型的引用形参时,可以给函数传递其派生类型的对象。这就意味着:对 istream& 进行操作的函数,也可使用 ifstream 或者istringstream 对象来调用。
IO 标准库管理一系列条件状态(condition state)成员,用来标记给定的 IO 对象是否处于可用状态,或者碰到了哪种特定的错误。
| 条件状态成员 | 说明 |
|---|---|
| strm::iostate | 机器相关的整型名,由各个 iostream 类定义,用于定义条件状态 |
| strm::badbit | strm::iostate 类型的值,用于指出被破坏的流。标志着系统级的故障,如无法恢复的读写错误。 |
| strm::failbit | strm::iostate 类型的值,用于指出失败的 IO 操作。可恢复的错误,如在希望获得数值型数据时输入了字符。 |
| strm::eofbit | strm::iostate 类型的值,用于指出流已经到达文件结束符。是在遇到文件结束符时设置的,此时同时还设置了 failbit。 |
| s.eof() | 如果设置了流 s 的 eofbit 值,则该函数返回 true |
| s.fail() | 如果设置了流 s 的 failbit 值,则该函数返回 true |
| s.bad() | 如果设置了流 s 的 badbit 值,则该函数返回 true |
| s.good() | 如果流 s 处于有效状态,则该函数返回 true |
| s.clear() | 将流 s 中的所有状态值都重设为有效状态 |
| s.clear(flag) | 将流 s 中的某个指定条件状态设置为有效。flag 的类型是strm::iostate |
| s.setstate(flag) | 给流 s 添加指定条件。flag 的类型是 strm::iostate |
| s.rdstate() | 返回流 s 的当前条件,返回值类型为 strm::iostate |
文件输入输出
fstream 类型除了继承下来的行为外,还定义了两个自己的新操作—— open和 close,以及形参为要打开的文件名的构造函数。
需要读写文件时,则必须定义自己的对象,并将它们绑定在需要的文件上。为 ifstream 或者 ofstream 对象提供文件名作为初始化式,就相当于打开了特定的文件。
ifstream infile(ifile.c_str());
ofstream outfile(ofile.c_str());
检测是否打开成功:
if (!infile) {
cerr << "error: unable to open input file: "<< ifile << endl;
return -1;
}
fstream 对象一旦打开,就保持与指定的文件相关联。如果要把 fstream 对象与另一个不同的文件关联,则必须先关闭(close)现在的文件,然后打开(open)另一个文件。
c++中的文件名:
由于历史原因,IO 标准库使用 C 风格字符串,而不是 C++ strings 类型的字符串作为文件名。在创建 fstream 对象时,如果调用open 或使用文件名作初始化式,需要传递的实参应为 C 风格字符串,而不是标准库 strings 对象。程序常常从标准输入获得文件名。通常,比较好的方法是将文件名读入 string 对象,而不是 C 风格字符数组。假设要使用的文件名保存在 string 对象中,则可调用 c_str 成员获取 C 风格字符串。
clear恢复流
如果遇到文件结束符或其他错误,将设置流的内部状态,以便之后不允许再对该流做读写操作。关闭流并不能改变流对象的内部状态。如果最后的读写操作失败了,对象的状态将保持为错误模式,直到执行 clear 操作重新恢复流的状态为止。调用 clear 后,就像重新创建了该对象一样。如果需要重用文件流读写多个文件,必须在读另一个文件之前调用 clear 清除该流的状态。
文件模式
在打开文件时,无论是调用 open 还是以文件名作为流初始化的一部分,都需指定文件模式(file mode)。
ate 模式只在打开时有效:文件打开后将定位在文件尾。
以 binary 模式打开的流则将文件以字节序列的形式处理,而不解释流中的字符。
| 文件模式 | 说明 |
|---|---|
| in | 打开文件做读操作 |
| out | 打开文件做写操作 |
| app | 追加模式,在每次写之前找到文件尾 |
| ate | 打开文件后立刻将文件定位在文件尾 |
| trunc | 打开文件时清空已存在的文件流 |
| binary | 以二进制模式进行IO操作 |
ios::app与ios::ate区别:
app会在每次写操作之前都把写指针置于文件末尾
而ate模式则只在打开时才将写指针置于文件末尾。在文件操作过程中,可以通过seekp等操作移动指针位置。
字符串流
将流与存储在程序内存中的string 对象捆绑起来。
| stringstream strm; | 创建自由的 stringstream 对象 |
| stringstream strm; | 创建存储 s 的副本的 stringstream 对象,其中 s 是string 类型的对象 |
| strm.str() | 返回 strm 中存储的 string 类型对象 |
| strm.str(s) | 将 string 类型的 s 复制给 strm,返回 void |
数学库
函数库为cmath.h、cstdlib.h、cstring.h、cfloat.h
常用列举:
- int abs(int i) 返回整型参数i的绝对值
- double exp(double x) 返回指数函数ex的值
- double log(double x) 返回logex的值
- double sqrt(double x) 返回+√x的值
- double pow(double x,double y)返回xy的值
- void srand(unsigned seed) 初始化随机数发生器
- int rand() 产生一个随机数并返回这个数
时间与日期
时间函数
头文件 <ctime>
数据结构:time_t , clock_t , struct tm ;
( time_t和clock_t都是一个整形数,time_t记录的是秒数,而在Windows下,clock_t存储的是毫秒数 )
struct tm {
int tm_sec; // 秒,正常范围从 0 到 59,但允许至 61
int tm_min; // 分,范围从 0 到 59
int tm_hour; // 小时,范围从 0 到 23
int tm_mday; // 一月中的第几天,范围从 1 到 31
int tm_mon; // 月,范围从 0 到 11
int tm_year; // 自 1900 年起的年数
int tm_wday; // 一周中的第几天,范围从 0 到 6,从星期日算起
int tm_yday; // 一年中的第几天,范围从 0 到 365,从 1 月 1 日算起
int tm_isdst; // 夏令时
};
获取时间
clock_t clock ( void ); //获取程序运行的clock数。在Windows下,每秒有1000个clock,也就是clock的精度是1毫秒。
time_t time ( time_t * timer );//可以得到从1970年1月1日到现在的秒数。
time_t类型的比较
double difftime ( time_t time2, time_t time1 );//返回(time2-time1)。不要看他返回的是double,精度最多也就是秒了。
struct tm和time_t之间的转化
1:
struct tm * gmtime ( const time_t * timer );
作用:将timer指向的time_t类型变量转化为struct tm结构的国际统一时。国际统一时就是世界统一认可的一个时间。
注意:返回的指针指向的是gmtime函数内的静态数据,也就是说,下次调用函数会将原来的结果覆盖,所以建议将结果拷贝到自己定义的tm变量内。
2:
struct tm * localtime ( const time_t * timer );
作用:将timer指向的time_t类型变量转化为struct tm结构的本地时间。也就是Windows右下角的时间。
3:
time_t mktime ( struct tm * timeptr );
作用:将struct tm结构转化为time_t类型。
将struct tm和time_t转化为字符串形式
char * asctime ( const struct tm * timeptr );
作用:将struct tm结构转化为字符串,格式是“Www Mmm dd hh:mm:ss yyyy”。
char * ctime ( const time_t * timer );
作用:将time_t类型数据,转化为字符串,格式是“Www Mmm dd hh:mm:ss yyyy”。
size_t strftime ( char * ptr, size_t maxsize, const char * format, const struct tm * timeptr );
作用:将struct tm结构的数据转化为定制的形式字符串。
面向对象类库STL
STL迭代器
iterator
迭代器 是一个广义指针;
它可以是指针,也可以是一个可对其执行类似指针操作如解除引用和递增操作的对象
迭代器类型是一个名为iterator的typedef,作用域整个类
按定义分为四类:
- 正向迭代器 定义: 容器类名::iterator 迭代器名;
- 常量正向迭代器 定义 :容器类名::const_iterator 迭代器名;
- 反向迭代器 定义: 容器类名::reverse_iterator 迭代器名;
- 常量反向迭代器 定义: 容器类名::const_reverse_iterator 迭代器名;
迭代器都可以进行++操作。反向迭代器和正向迭代器的区别在于:
- 对正向迭代器进行
++操作时,迭代器会指向容器中的后一个元素; - 而对反向迭代器进行
++操作时,迭代器会指向容器中的前一个元素。
初始化与声明
vector<int>v; //声明一个int型的数组(也叫向量)
vertor<int>v(5); //声明一个大小为5的int型数组
vector<int>v(10,1); //声明一个大小为10并且值都是1的int型数组
vector<vector<int> >v; //声明一个int型的二维数组
例:为vector的double类型规范定义一个迭代器
vector<double>::iterator pd;
vector<double> scores;
//可使用迭代器执行的操作
pd=scores.begin();
*pd=22.3;
++pd;
//还可以使用c++自动类型推断来使用迭代器
auto pds=scores.begin();
使用迭代器遍历一个vector容器内所有元素
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> v; //v是存放int类型变量的可变长数组,开始时没有元素
for (int n = 0; n<5; ++n)
v.push_back(n); //push_back成员函数在vector容器尾部添加一个元素
vector<int>::iterator i; //定义正向迭代器
for (i = v.begin(); i != v.end(); ++i) { //用迭代器遍历容器
cout << *i << " "; //*i 就是迭代器i指向的元素
*i *= 2; //每个元素变为原来的2倍
}
cout << endl;
//用反向迭代器遍历容器
for (vector<int>::reverse_iterator j = v.rbegin(); j != v.rend(); ++j)
cout << *j << " ";
return 0;
}
迭代器功能
正向迭代器。假设 p 是一个正向迭代器,则 p 支持以下操作:++p,p++,*p。此外,两个正向迭代器可以互相赋值,还可以用==和!=运算符进行比较。
双向迭代器。双向迭代器具有正向迭代器的全部功能。除此之外,若 p 是一个双向迭代器,则--p和p--都是有定义的。--p使得 p 朝和++p相反的方向移动。
随机访问迭代器。随机访问迭代器具有双向迭代器的全部功能。若 p 是一个随机访问迭代器,i 是一个整型变量或常量,则 p 还支持以下操作:
- p+=i:使得 p 往后移动 i 个元素。
- p-=i: 使得 p 往前移动 i 个元素。
- p+i: 返回 p 后面第 i 个元素的迭代器。
- p-i: 返回 p 前面第 i 个元素的迭代器。
- p[i]: 返回 p 后面第 i 个元素的引用。
此外,两个随机访问迭代器 p1、p2 还可以用 <、>、<=、>= 运算符进行比较。p1<p2的含义是:p1 经过若干次(至少一次)++操作后,就会等于 p2。其他比较方式的含义与此类似。
对于两个随机访问迭代器 p1、p2,表达式p2-p1也是有定义的,其返回值是 p2 所指向元素和 p1 所指向元素的序号之差(也可以说是 p2 和 p1 之间的元素个数减一)。
不同容器的迭代器功能:
| 容器 | 功能 |
|---|---|
| vector | 随机访问 |
| deque | 随机访问 |
| list | 双向 |
| set/multiset | 双向 |
| map | 双向 |
| stack | 不支持迭代器 |
| queue | 不支持迭代器 |
| priorty_queue | 不支持迭代器 |
迭代器的辅助函数:
STL 中有用于操作迭代器的三个函数模板,它们是:
- advance(p, n):使迭代器 p 向前或向后移动 n 个元素。
- distance( p,q ):计算两个迭代器之间的距离,即迭代器 p 经过多少次 + + 操作后和迭代器 q 相等。如果调用时 p 已经指向 q 的后面,则这个函数会陷入死循环。
- iter_swap(p, q):用于交换两个迭代器 p、q 指向的值。
要使用上述模板,需要包含头文件 #include <algorithm>
STL分配器
分配器就是STL中底层的内存管理结构。
allocator空间分配的内部机制
由于在分配过多小型区块会造成内存问题,SGI设计了双层级配置器
-
SGI STL第一级配置器
其中allocate()直接使用malloc()
deallocate()直接使用free()
当申请的内存大小大于128byte时,就启动第一级分配器通过malloc直接向系统的堆空间分配
-
SGI STL第二级配置器
采用内存池配置
内存池由16个不同大小(8的倍数,8~128byte)的空闲列表组成
每次都给内存池中申请一大块的内存空间,并且用多条自由链表对这块内存进行维护。
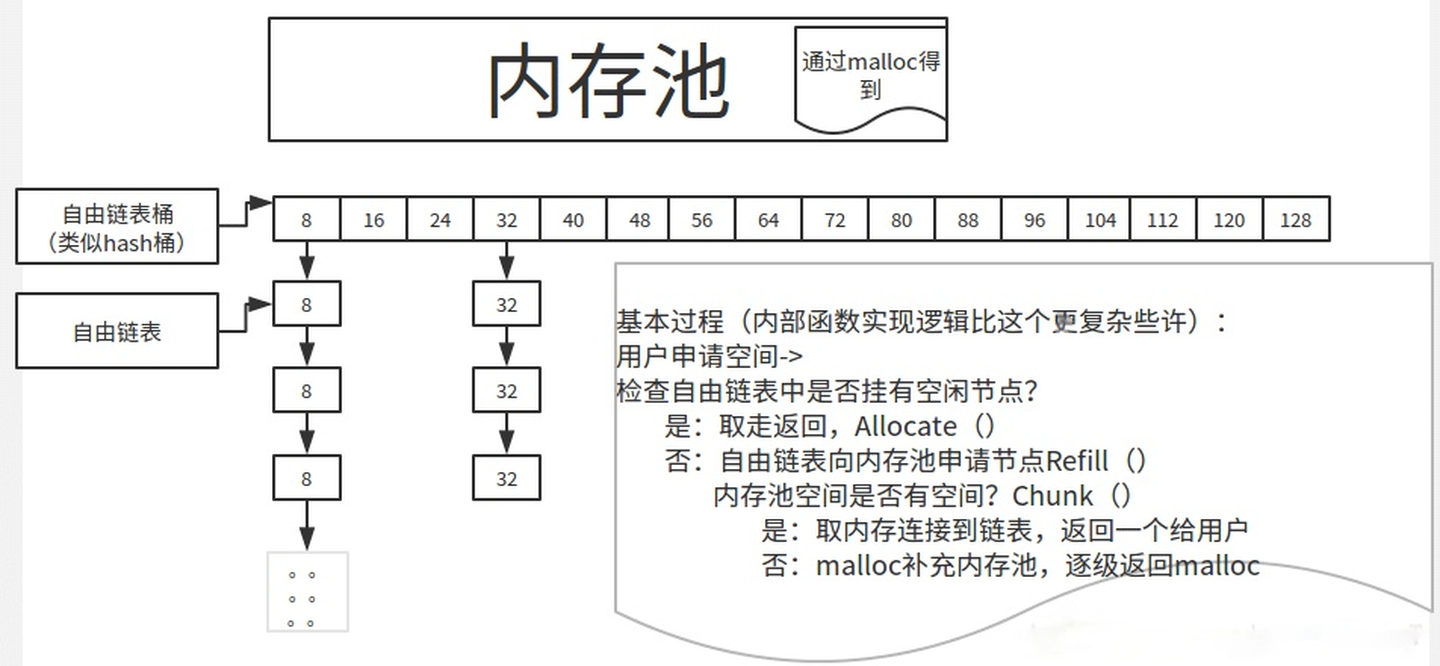
自由链表
每次配置一大块内存,就直接从自由链表的表头拨出。如果释放小额区块,就由配置器回收到自由链表表头。为了方便管理,第二级配置器会主动将任何小额区块的内存需求量上调至 8 的倍数,并维护 16 个自由链表,各自管理大小分别为 8,16,24,32,40,48,56,64,72,80,88,96,104,112,120,128 bytes 的小额区块。
内存池
内存池是在真正使用内存之前,预先申请分配一定数量、大小相等(一般情况下)的内存块留作备用。当有新的内存需求时,就从内存池中分出一部分内存块,若内存块不够再继续申请新的内存。这样做的一个显著优点是,使得内存分配效率得到提升。
配置策略
第一级配置器以 malloc(),free(),realloc() 等 C 函数执行实际的内存配置、释放、重配置操作。
第二级配置器视情况采用不同的策略:当配置区块超过 128 bytes 时,视之为“足够大”,便调用第一级配置器;当配置区块小于 128 bytes 时,视之为“过小”,为了降低额外负担,便采用内存池配置方式。
过程图解:
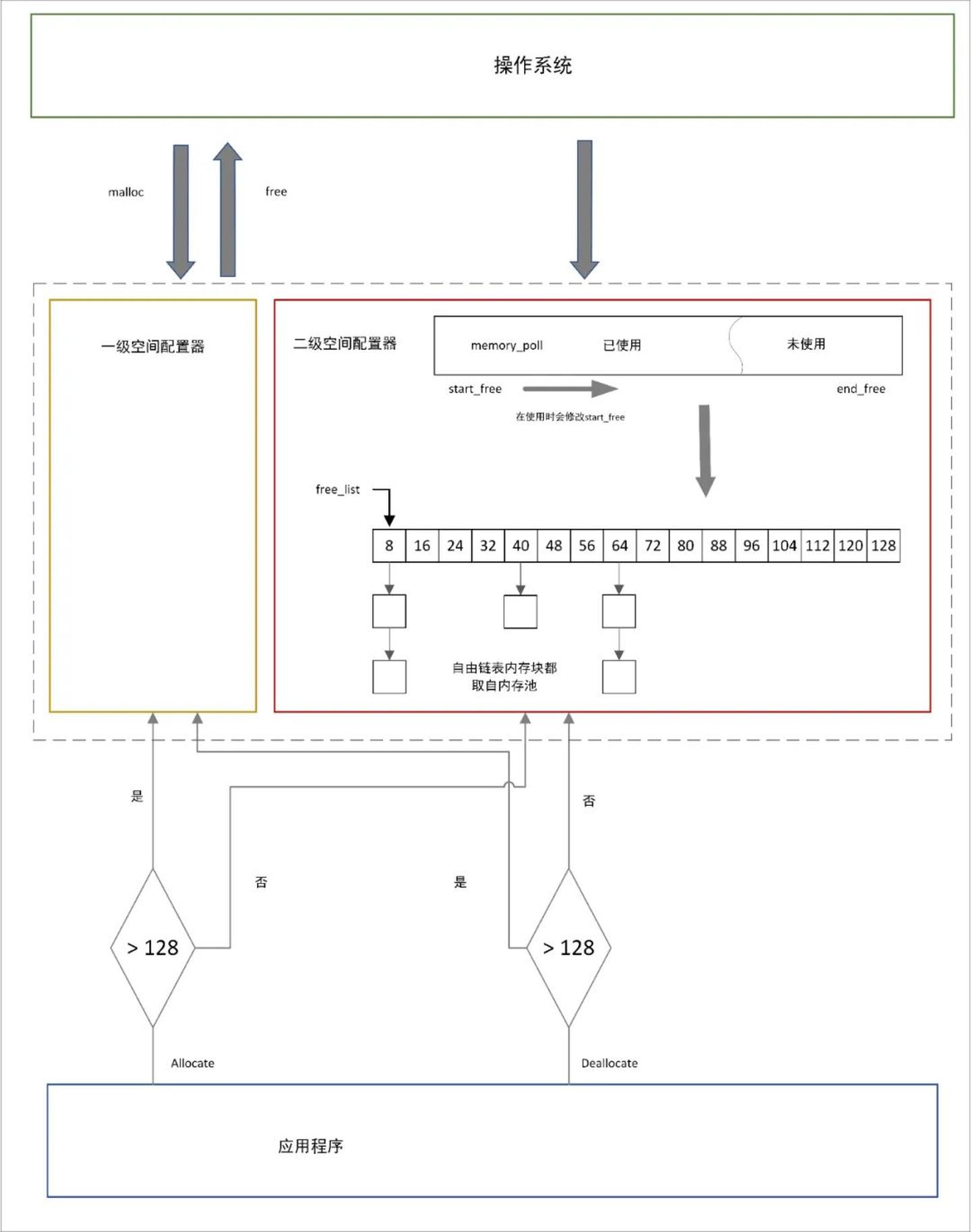
总结:
STL中的内存分配器实际上是基于空闲列表(free list)的分配策略,最主要的特点是通过组织16个空闲列表,对小对象的分配做了优化。
1)小对象的快速分配和释放。当一次性预先分配好一块固定大小的内存池后,对小于128字节的小块内存分配和释放的操作只是一些基本的指针操作,相比于直接调用malloc/free,开销小。
2)避免内存碎片的产生。零乱的内存碎片不仅会浪费内存空间,而且会给OS的内存管理造成压力。
3)尽可能最大化内存的利用率。当内存池尚有的空闲区域不足以分配所需的大小时,分配算法会将其链入到对应的空闲列表中,然后会尝试从空闲列表中寻找是否有合适大小的区域,
但是,这种内存分配器局限于STL容器中使用,并不适合一个通用的内存分配。因为它要求在释放一个内存块时,必须提供这个内存块的大小,以便确定回收到哪个free list中,而STL容器是知道它所需分配的对象大小的,
STL函数
for_each() random_shuffle() sort()
for_each() 接受三个参数,前两个是定义在容器中区间的迭代器,最后一个是指向函数的指针。
可用于任何容器
可以使用for_each()来代替for循环
//显式使用迭代器变量进行循环
vector<Review>::iterator pr;
for(pr=books.begin();pr!=books.end();pr++)
ShowReview(*pr);
//使用for_each 可以避免显式的使用迭代器变量
//替换for循环为
for_each(books.begin(),books.end(),ShowReview);
random_shuffle() 函数接受两个指定区间的迭代器参数,并随机排序该区间内的元素。
要求容易类允许随机访问,vector可以满足
sort() 要求容器支持随机访问
头文件#include<algorithm>
默认从小到大排序
一:接受两个区间定义的迭代器作为参数,并使用为存储在容器中的类型元素定义的 < 运算符,对区间中元素进行比较。
例:对内容进行升序排序,排序时使用内置的<进行比较
vector <int> number;
sort(number.begin(),number.end()); //默认从小到大排序
sort(number.begin(),number.end(),greater<int>());//内置类型从大到小排序
如果容器元素是用户定义的对象,那么在使用sort()时必须定义能够处理该类型对象的operator<()函数;
二:接受三个参数,前两个参数指定迭代器的区间,最后一个参数指向要使用的函数的指针(函数对象)。
STL容器类
用于存放数据的类模板
使用容器时,即将容器类模板实例化为容器类时,会指明容器中存放的元素是什么类型的
容器中可以存放基本类型的变量,也可以存放对象。对象或基本类型的变量被插入容器中时,实际插入的是对象或变量的一个复制品。
所有容器都有两个成员函数:
-
int size():返回容器对象中元素的个数。
-
bool empty():判断容器对象是否为空。
顺序容器和关联容器还有以下成员函数:
- begin():返回指向容器中第一个元素的迭代器。
- end():返回指向容器中最后一个元素后面的位置的迭代器。
- rbegin():返回指向容器中最后一个元素的反向迭代器。
- rend():返回指向容器中第一个元素前面的位置的反向迭代器。
- erase(…):从容器中删除一个或几个元素。接受两个迭代器参数,定义删除的区间
- clear():从容器中删除所有元素。
顺序容器
可变动态数组Vector、双端队列deque、双向链表list
元素在容器中的位置同元素的值无关,即容器不是排序的。将元素插入容器时,指定在什么位置(尾部、头部或中间某处)插入,元素就会位于什么位置。
顺序容器有以下常用成员函数:
- front(): 返回容器中第一个元素的引用。
- back(): 返回容器中最后一个元素的引用。
- push_back(): 在容器末尾增加新元素。
- pop_back(): 删除容器末尾的元素。
- c.empty() : 判断c容器是否为空
- insert(…): 插入一个或多个元素。接受三个迭代器参数 第一个参数指定插入位置,第二和第三个参数定义插入区间
- begin() : 返回第一个元素的迭代器
- end() : 返回最末元素的迭代器(实指向最末元素的下一个位置)
Vector
1.构造函数
vector(); //创建一个空vector
vector(int nSize); //创建一个vector,元素个数为nSize
vector(int nSize,const t& t); //创建一个vector,元素个数为nSize,且值均为t
vector(const vector&); //复制构造函数
vector(begin,end); //复制[begin,end)区间内另一个数组的元素到vector中
对应数组,使用动态内存分配,使用初始化参数来指出需要多少矢量
可以使用通用数组表示法来访问各个元素
方法:
size() 返回容器内元素数目,swap() 交换两个容器内容
erase()方法删除矢量中给定区间的元素,接受两个迭代器参数,这些参数定义了要删除的区间
第一个迭代器指向区间的起始处,第二个迭代器位于区间终止处的后一个位置。[ 区间 )
例如:scores.earse(scores.begin(),socres.begin()+2);//删除第一二个元素
reverse(a.begin(),a.end()) 反转
对字符串进行反转可以快速判断一个字符串是否是回文的.
string a;
vector<string>s;
for(int i=1;i<=n;i++){
cin>>a;
string b=a;
reverse(b.begin(),b.end()); //对字符串进行翻转
if(a==b) s.push_back(a); //如果回文放进vector
}
deque
头文件:#include<deuqe>;
deque的动态数组首尾都开放,因此能够在首尾进行快速地插入和删除操作.
deque是一种优化了的对序列两端元素进行添加和删除操作的基本序列容器。通常由一些独立的区块组成,第一区块朝某方向扩展,最后一个区块朝另一方向扩展。它允许较为快速地随机访问但它不像vector一样把所有对象保存在一个连续的内存块,而是多个连续的内存块。并且在一个映射结构中保存对这些块以及顺序的跟踪。
特点:
1、支持随机访问,即支持[]以及at(),但是性能没有vector好。
2、可以在内部进行插入和删除操作,但性能不及list。
构造函数:
deque<Elem> c; //创建一个空的deque
deque<Elem> c1(c2) ; //复制一个deque。
deque<Elem> c(n); //创建一个deque,含有n个数据,数据均已缺省构造产生。
deque<Elem> c(n, elem) ; //创建一个含有n个elem拷贝的deque。
deque<Elem> c(beg,end) ; //创建一个以[beg;end)区间的deque。
~deque<Elem>() ; //销毁所有数据,释放内存。
operator= 赋值运算符重载
list
头文件:#include<list>;
list是一种序列式容器, list就是数据结构中的双向链表,list中的数据元素是通过链表指针串连成逻辑意义上的线性表。
使用:如果你需要大量的插入和删除,而不关心随即存取,则应使用list。
构造函数 :
list<int> c0; //空链表
list<int> c1(3); //建一个含三个默认值是0的元素的链表
list<int> c2(5,2); //建一个含五个元素的链表,值都是2
list<int> c4(c2); //建一个c2的copy链表
list<int> c5(c1.begin(),c1.end()); //c5含c1一个区域的元素[_First, _Last)。
关联容器
set、multiset、map、multimap
关联容器内的元素是排序的。插入元素时,容器会按一定的排序规则将元素放到适当的位置上,因此插入元素时不能指定位置。
关联容器就是通过键(key)来读取和修改元素
set
单纯键的集合
set集合容器实现了红黑树(Red-Black Tree)的平衡二叉检索树的数据结构,在插入元素时,它会自动调整二叉树的排列,把该元素放到适当的位置,以确保每个树根节点的键值大于左子树所有节点的键值,而小于右子树所有节点的键值;另外,还确保根节点左子树的高度与右子树的高度相等,这样,二叉树的高度最小,从而检索速度最快。要注意的是,它不会重复插入相同键值的元素,而采取忽略处理。
头文件 #include <set>
创建set集合对象: set <int> s;
set 默认从小到大排序;
操作:
s.begin() // 返回指向第一个元素的迭代器
s.clear() // 清除所有元素
s.count() // 返回某个值元素的个数
s.empty() // 如果集合为空,返回true(真)
s.end() // 返回指向最后一个元素之后的迭代器,不是最后一个元素
s.equal_range() // 返回集合中与给定值相等的上下限的两个迭代器
s.erase() // 删除集合中的元素
s.find() // 返回一个指向被查找到元素的迭代器
s.get_allocator() // 返回集合的分配器
s.insert() // 在集合中插入元素
s.lower_bound() // 返回指向大于(或等于)某值的第一个元素的迭代器
s.key_comp() // 返回一个用于元素间值比较的函数
s.max_size() // 返回集合能容纳的元素的最大限值
s.rbegin() // 返回指向集合中最后一个元素的反向迭代器
s.rend() // 返回指向集合中第一个元素的反向迭代器
s.size() // 集合中元素的数目
s.swap() // 交换两个集合变量
s.upper_bound() // 返回大于某个值元素的迭代器
s.value_comp() // 返回一个用于比较元素间的值的函数
例:元素插入
set<int>s;
s.insert(1);
multiset
多重集合
头文件 <set>
多重集合与集合的区别在于集合中不能存在相同元素,而多重集合中可以存在。
map
关联数组,保存键值对
map的底层是由红黑树实现的,红黑树的每一个节点都代表着map的一个元素。该数据结构具有自动排序的功能,因此map内部的元素都是有序的,元素在容器中的顺序是通过比较键值确定的。默认使用 less<K> 对象比较。
元素检索的时间复杂度是O(logN);
Map<string, int> mapStudent;//构造一个map对象
map<string, string> authors = { {"Joyce", "James"},//初始化对象
{"Austen", "Jane"},
{"Dickens", "Charles"} };
常用属性:
size 返回有效元素个数
max_size 返回容器支持的最大元素个数
empty 判断容器是否为空,为空是返回true,否则返回false
clear 清空map容器
排序:
//1、按照key值默认字典序排序(升序)
map<string,int>m;
m["sdft"]=20;
m["sdfsdfs"]=26;
m["dfgfdg"]=30;
for(map<string,int>::iterator it=m.begin();it!=m.end();it++)
cout<<it->first<<" "<<it->second<<endl;
//2、按照key值降序输出
map<string,int,greater<string> >m;
m["sdft"]=20;
m["sdfsdfs"]=26;
m["dfgfdg"]=30;
for(map<string,int>::iterator it=m.begin();it!=m.end();it++)
cout<<it->first<<" "<<it->second<<endl;
//3、自定义排序方式(按照字符串长度升序)
struct cmp{
bool operator ()(string a,string b){
return a.length()<b.length();
}
};
int main(){
map<string,int,cmp>m;
m["sdft"]=20;
m["sdfsdfs"]=26;
m["dfgfdg"]=30;
for(map<string,int>::iterator it=m.begin();it!=m.end();it++)
cout<<it->first<<" "<<it->second<<endl;
return 0;
}
插入数据
1、用insert函数插入pair数据
map<string, int> mapStudent;//创建map
mapStudent.insert(pair<string, int>("student_one", 22));
mapStudent.insert(pair<string, int>("student_two", 25));
或者使用make_pair
map<string, int> mapStudent;
mapStudent.insert(make_pair("student_one", 22));
mapStudent.insert(make_pair("student_two", 25));
2、用insert函数插入value_type数据
map<string, int> mapStudent;//创建map
mapStudent.insert(map<string, int>::value_type("student_one", 22));
mapStudent.insert(map<string, int>::value_type("student_two", 25));
3、用数组方式插入数据
map<string, int> mapStudent;//创建map
mapStudent["student_one"] = 22;
mapStudent["student_two"] = 25;
4、用emplace函数插入数据
map<string, int> mapStudent;
mapStudent.emplace("student_one", 22);
mapStudent.emplace("student_two", 25);
删除:
map容器中删除一个元素要使用erase函数,只要有以下几种用法。
//使用关键字删除
int res = mapStudent.erase("student_one"); //删除成功返回1,失败返回0;只有使用关键字删除时才有返回值
cout << "res=" << res << endl;
//使用迭代器删除
map<string, int>::iterator iter;
iter = mapStudent.find("student_two");
mapStudent.erase(iter);
//使用迭代器删除一个范围的元素
auto it = mapStudent.begin();
mapStudent.erase(it, mapStudent.find("student_two"));
map的三个应用
去重:假设我们有一个key值出现了很多次,而且我们只需要一个的时候,此时我们就可以使用map来去重.
排序:原本默认按照key值的字典序进行排序.,如果我们需要的方式进行排序,此时我们就可以自定义类来进行排序.
计数:只要我们输入一个key值就进行m[key]++操作,这样一来我们就可以统计key出现了多少次.
multimap
与map容器类似,区别只在于multimap容器可以保存键值相同的元素。
unordered_set/unordersd_map:
unordered_set
包含在头文件 <unordered_set>
基于哈希表实现
unordered_set <T>
可以用保存的元素作为它们自己的键
T 类型的对象在容器中的位置由它们的哈希值决定
这种容器不能存放重复的元素(容器是个集合,所以重复插入相同的值是没有效果的)
元素类型必须可以比较是否相等
提供的方法:
unordered_set::insert 插入
unordered_set::find 查找
unordered_set::erase 删除
find的返回值是一个迭代器(iterator),如果找到了会返回指向目标元素的迭代器,没找到会返回end()。
#include <iostream>
#include <unordered_set>
using namespace std;
int main()
{
unordered_set<int> my_set;
my_set.insert(3);
my_set.insert(5);
my_set.insert(3);
cout<<"my_set size is "<<my_set.size()<<endl;
my_set.erase(3);
//如果索引==end_ind,则找不到
if (my_set.find(3) == my_set.end())
cout<<"3 not found."<<endl;
return 0;
}
时间复杂度O(1) 最坏时间复杂度O(N)
unordered_map
该容器的底层是由哈希(又名散列)函数组织实现的。元素的顺序并不是由键值决定的,而是由键值的哈希值确定的,哈希值是由哈希函数生成的一个整数。利用哈希函数,将关键字的哈希值都放在一个桶(bucket)里面,具有相同哈希值的放到同一个桶。unordered_map内部元素的存储是无序的,也不允许有重复键值的元素,相当于java中的HashMap。
重载了[]运算符,我们可以把key放在中括号里,像操作数组一样操作unordered_map
unordered_map<string,int>mymap;
mymap["c++"]=100;
mymap["c++"]++;
mymap.insert(make_pare("java",98));
容器适配器
容器适配器,其就是将不适用的序列式容器(包括 vector、deque 和 list)变得适用。
通过封装某个序列式容器,并重新组合该容器中包含的成员函数,使其满足某些特定场景的需要。
容器适配器本质上还是容器,只不过此容器模板类的实现,利用了大量其它基础容器模板类中已经写好的成员函数。当然,如果必要的话,容器适配器中也可以自创新的成员函数。
stack 栈适配器
基础容器需包含以下成员函数:
- empty()
- size()
- back()
- push_back()
- pop_back()
满足条件的基础容器有 vector、deque、list。
默认使用的基础容器 deque 可以通过指定第二个模板参数来使用其他容器
特点:先进后出 LIFO
#include <stack>
using namespace std;
std::stack<int> values;
这样就成功创建了一个可存储 int 类型元素,底层采用 deque 基础容器的 stack 适配器。
支持的成员函数:
| 成员函数 | 功能 |
|---|---|
| empty() | 当 stack 栈中没有元素时,该成员函数返回 true;反之,返回 false。 |
| size() | 返回 stack 栈中存储元素的个数。 |
| top() | 返回一个栈顶元素的引用,类型为 T&。如果栈为空,程序会报错。 |
| push(const T& val) | 先复制 val,再将 val 副本压入栈顶。这是通过调用底层容器的 push_back() 函数完成的。 |
| push(T&& obj) | 以移动元素的方式将其压入栈顶。这是通过调用底层容器的有右值引用参数的 push_back() 函数完成的。 |
| pop() | 弹出栈顶元素。 |
| emplace(arg…) | arg… 可以是一个参数,也可以是多个参数,但它们都只用于构造一个对象,并在栈顶直接生成该对象,作为新的栈顶元素。 |
| swap(stack & other_stack) | 将两个 stack 适配器中的元素进行互换,需要注意的是,进行互换的 2 个 stack 适配器中存储的元素类型以及底层采用的基础容器类型,都必须相同。 |
使用:
#include <iostream>
#include <stack>
#include <list>
using namespace std;
int main()
{
//构建 stack 容器适配器
list<int> values{ 1, 2, 3 };
stack<int, list<int>> my_stack(values);
//查看 my_stack 存储元素的个数
cout << "size of my_stack: " << my_stack.size() << endl;
//将 my_stack 中存储的元素依次弹栈,直到其为空
while (!my_stack.empty())
{
cout << my_stack.top() << endl;
//将栈顶元素弹栈
my_stack.pop();
}
return 0;
}
queue 队列适配器
基础容器需包含以下成员函数:
- empty()
- size()
- front()
- back()
- push_back()
- pop_front()
满足条件的基础容器有 deque、list。
默认使用deque
使用:
只能访问 queue 容器适配器的第一个和最后一个元素。只能在容器的末尾添加新元素,只能从头部移除元素。
LIFO 先进先出
std::queue<std::string> words;
std::queue<std::string, std::list<std::string>>words;
操作:
| 成员函数 | 功能 |
|---|---|
| empty() | 当 queue 中没有元素时,该成员函数返回 true;反之,返回 false。 |
| size() | 返回 queue 中元素的个数 |
| fron() | 返回 queue 中第一个元素的引用。如果 queue 是常量,就返回一个常引用;如果 queue 为空,返回值是未定义的 |
| back() | 返回 queue 中最后一个元素的引用。 |
| push(const T& val) | 在 queue 的尾部添加一个元素的副本。这是通过调用底层容器的成员函数 push_back()来完成的。 |
| push(T&& obj) | 以移动的方式在 queue 的尾部添加元素。这是通过调用底层容器的具有右值引用参数的成员函数push_back() 来完成的。 |
| pop() | 删除 queue 中的第一个元素 |
| swap(queue &other_q) | 将当前 queue 中的元素和参数 queue中的元素交换。它们需要包含相同类型的元素。也可以调用全局函数模板 swap() 来完成同样的操作 |
| emplace() | 用传给 emplace() 的参数调用 T的构造函数,在 queue 的尾部生成对象。 |
和 stack 一样,queue 也没有迭代器。访问元素的唯一方式是遍历容器内容,并移除访问过的每一个元素。
priority_queue 优先权队列适配器
基础容器需包含以下成员函数:
- empty()
- size()
- front()
- push_back()
- pop_back()
满足条件的基础容器有vector、deque。
默认使用vector
priority_queue 容器适配器定义了一个元素有序排列的队列。默认队列头部的元素优先级最高。
参数:
priority_queue 模板有 3 个参数,其中两个有默认的参数;第一个参数是存储对象的类型,第二个参数是存储元素的底层容器,第三个参数是函数对象,它定义了一个用来决定元素顺序的断言。因此模板类型是:
template <typename T, typename Container=std::vector<T>, typename Compare=std::less<T>> class priority_queue
priority_queue 实例默认有一个 vector 容器。
函数对象类型 less < T> 是一个默认的排序断言,定义在头文件 function 中,决定了容器中最大的元素会排在队列前面。fonction 中定义了 greater< T>,用来作为模板的最后一个参数对元素排序,最小元素会排在队列前面。
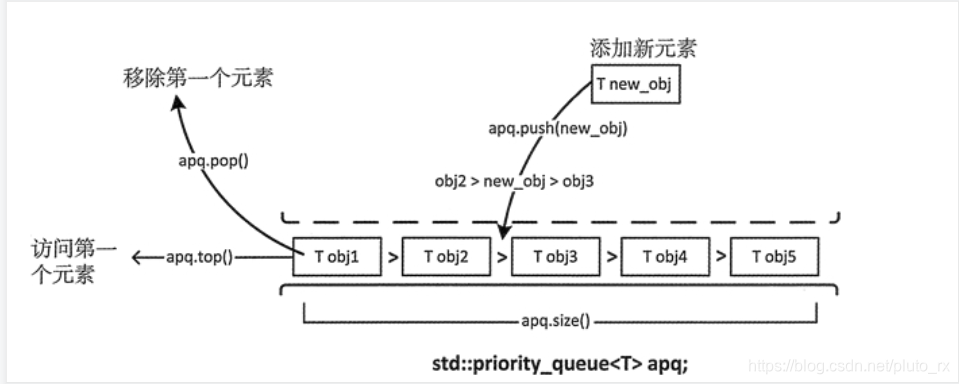
创建:
std::priority_queue<std::string> words;
std::string wrds[] { "one", "two", "three", "four"};
std::priority_queue<std::string> words { std::begin(wrds),std:: end(wrds)};
优先级队列可以使用任何容器来保存元素,只要容器有成员函数 front()、push_back()、pop_back()、size()、empty()。
操作
| 成员函数 | 功能 |
|---|---|
| push(const T& obj) | 将obj的副本放到容器的适当位置,这通常会包含一个排序操作。 |
| push(T&& obj) | 将obj放到容器的适当位置,这通常会包含一个排序操作。 |
| emplace(T constructor a rgs…) | 通过调用传入参数的构造函数,在序列的适当位置构造一个T对象。为了维持优先顺序,通常需要一个排序操作。 |
| top() | 返回优先级队列中第一个元素的引用。 |
| pop() | 移除第一个元素。 |
| size() | 返回队列中元素的个数。 empty():如果队列为空的话,返回true。 |
| swap(priority_queue& other) | 和参数的元素进行交换,所包含对象的类型必须相同。 |
priority_queue 也实现了赋值运算,可以将右操作数的元素赋给左操作数;同时也定义了拷贝和移动版的赋值运算符
priority_queue 容器并没有定义比较运算符。因为需要保持元素的顺序,所以添加元素通常会很慢
priority_queue 没有迭代器。如果想要访问全部的元素,比如说,列出或复制它们,会将队列清空
线程支持库
C++包含了对 线程、互斥、条件变量和futures的内在支持
线程使得程序能够跨多个处理器核心执行。
定义在thread头文件中:
thread (C++11) 管理一个单一线程
管理当前线程
定义在名称空间 namespace this_thread中:
| 函数 | 功能 | |
|---|---|---|
| yield (C++11) | 建议实现重新规划线程的执行时机 (suggests that the implementation reschedule execution of threads) | |
| get_id (C++11) | 返回当前线程的id | |
| sleep_for (C++11) | 停止当前线程的执行,直到指定的时间段之后 | |
| sleep_until (C++11) | 停止当前进程的执行,直到指定的时间点 |
缓存尺寸访问
定义在 new 头文件中:
| 函数 | 说明 |
|---|---|
| hardware_destructive_interference_size (C++17) | 最小偏移以避免false共享(min offset to avoid false sharing) |
| hardware_constructive_interference_size (C++17) | 最大偏移以提升true共享(max offset to promote true sharing) |
互斥
互斥 Mutual exclusion
互斥算法防止多个线程同时访问共享资源。这防止了数据竞争,提供了对线程间同步的支持。
定义在 mutex 头文件中:
| 函数 | 说明 |
|---|---|
| mutex (C++11) | 提供基本的互斥功能 |
| time_mutex (C++11) | 提供互斥功能,此互斥功能实现了定时器性质的锁 |
| recursive_mutex (C++11) | 提供互斥功能,此互斥功能可以被同一个线程多次递归地锁住 |
| recursive_timed_mutex (C++11) | 提供互斥功能,此互斥功能可以被同一个线程多次递归地锁住,并且实现了带定时器的锁定 |
| shared_mutex (C++17) | 提供共享的互斥功能 |
| shared_timed_mutex (C++14) | 提供共享的互斥功能 |
锁
普通mutex锁管理
定义在 mutex 头文件中:
| 函数 | 说明 |
|---|---|
| lock_guard (C++11) | 实现了一个严格的基于scope的互斥量ownership的封装者(wrapper) |
| unique_lock (C++11) | 实现了movable的互斥量ownership的封装者(wrapper) |
| shared_lock (C++14) | 实现了movable的共享的互斥量的ownership的封装者(wrapper) |
| defer_lock_t (C++11) | 一种标记类型,用以指定锁定策略 |
| try_to_lock_t (C++11) | 同上 |
| adopt_lock_t (C++11) | 同上 |
| defer_lock (C++11) | 标记常量,用以指定锁定策略 |
| try_to_lock (C++11) | 同上 |
| adopt_lock (C++11) | 同上 |
普通锁定算法
| 函数 | 说明 |
|---|---|
| try_lock (C++11) | 通过反复地调用try_lock,试图获得互斥量的所有权 |
| lock (C++11) | 锁定指定的互斥量,如果有的是unavailable,就进入Block状态 |
Call once
| 函数 | 说明 |
|---|---|
| once_flag (C++11) | 是一个帮助者对象(helper object),用以保证call_once调用该方法仅仅一次 |
| call_once (C++11) | 即使在多个线程中同时调用一个方法,该方法也仅仅被执行一次 |
条件变量
条件变量 (Condition variable)是一个同步原语,它使得多线程可以互相通信。它使得一些线程等待或者超时,另一个线程的通知以使得它们继续。
一个条件变量总是伴随着一个互斥量。
定义在 condition_variable 头文件中:
| 函数 | 说明 |
|---|---|
| condition_variable (C++11) | 提供一个条件变量,配合使用的是std::unique_lock |
| condition_vairable_any (C++11) | 提供一个条件变量,可以配合任意的lock类型 |
| notify_all_at_thread_exit (C++11) | 当线程结束的时候,规划一个对notify_all的调用 |
| cv_status (C++11) | 列出等在条件变量Shanghai的可能的结果 (lists the possible results of timed waits on condition variables) |
Futures
标准库提供一些功能以观察被返回的值以及抓取被异步任务(即:在其他线程启动的函数)所抛出的异常。这些值以一种共享的状态来被传送。在这种共享状态下,异步任务可以写返回值或存储一个异常,而这个值或异常可以被持有std::future或std::shared_future实例的其他线程来检查、等待和操作。
定义在 future 头文件中:
| 函数 | 说明 |
|---|---|
| promise (C++11) | 为异步的获取而存储一个值 |
| packaged_task (C++11) | 打包一个函数,以便为异步的获取而存储该函数的返回值 |
| future (C++11) | 等待一个被设为异步的值 |
| shared_future (C++11) | 等待一个被设为异步的值(该值可能被其他futures所引用) |
| async (C++11) | 异步地运行一个函数(在一个新的线程中),并返回一个含有结果的std::future |
| launch (C++11) | 为std::async指定launch的策略 |
| future_status (C++11) | 指定作用在std::future和std::shared_future上的结果 |
Future errors
| 函数 | 说明 |
|---|---|
| future_error (C++11) | 报告一个关于futures或promises的错误 |
| future_category (C++11) | 指定该future error的种类 |
| future_errc (C++11) | 指定该future error的代码 |
编程技术
断言
assert
看作是异常处理的一种高级形式
相当于一个if语句
if(假设成立)
{
程序正常运行;
}
else
{
报错&&终止程序!(避免由程序运行引起更大的错误)
}
#include "assert.h"
void assert( int expression );
assert 的作用是先计算表达式 expression ,如果其值为假(即为0),那么它先向 stderr 打印一条出错信息,然后通过调用 abort 来终止程序运行。
缺点是,频繁的调用会极大的影响程序的性能,增加额外的开销。
在调试结束后,可以通过在包含 #include 的语句之前插入 #define NDEBUG 来禁用 assert 调用,示例代码如下:
#include
#define NDEBUG
#include
使用:
1)在函数开始处检验传入参数的合法性
int resetBufferSize(int nNewSize)
{
//功能:改变缓冲区大小,
//参数:nNewSize 缓冲区新长度
//返回值:缓冲区当前长度
//说明:保持原信息内容不变 nNewSize<=0表示清除缓冲区
assert(nNewSize >= 0);
assert(nNewSize <= MAX_BUFFER_SIZE);
...
}
2)每个assert只检验一个条件,因为同时检验多个条件时,如果断言失败,无法直观的判断是哪个条件失败
不好:
assert(nOffset>=0 && nOffset+nSize<=m_nInfomationSize);
好:
assert(nOffset >= 0);
assert(nOffset+nSize <= m_nInfomationSize);
3)不能使用改变环境的语句,因为assert只在DEBUG个生效,如果这么做,会使用程序在真正运行时遇到问题
错误: assert(i++ < 100)
这是因为如果出错,比如在执行之前i=100,那么这条语句就不会执行,那么i++这条命令就没有执行。
正确:
assert(i < 100)
i++;
4)assert和后面的语句应空一行,以形成逻辑和视觉上的一致感
5)有的地方,assert不能代替条件过滤
断言assert 是仅在Debug 版本起作用的宏,它用于检查"不应该"发生的情况。
使用断言的几个原则:
- (1)使用断言捕捉不应该发生的非法情况。不要混淆非法情况与错误情况之间的区别,后者是必然存在的并且是一定要作出处理的。
- (2)使用断言对函数的参数进行确认。
- (3)在编写函数时,要进行反复的考查,并且自问:"我打算做哪些假定?"一旦确定了的假定,就要使用断言对假定进行检查。
- (4)一般教科书都鼓励程序员们进行防错性的程序设计,但要记住这种编程风格会隐瞒错误。当进行防错性编程时,如果"不可能发生"的事情的确发生了,则要使用断言进行报警。
总结:
ASSERT ()是一个调试程序时经常使用的宏,在程序运行时它计算括号内的表达式,如果表达式为FALSE (0), 程序将报告错误,并终止执行。如果表达式不为0,则继续执行后面的语句。这个宏通常原来判断程序中是否出现了明显非法的数据,如果出现了终止程序以免导致严重后果,同时也便于查找错误。
ASSERT 只有在 Debug 版本中才有效,如果编译为 Release 版本则被忽略。















 3062
3062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









