






背景
PostgreSQL和MySQL一样,是一种关系型数据库,多用于存储业务数据,且数据以记录(Record)为单位,采用行式存储,比较适合OLTP的场景;而ClickHouse则是一种强大的列式数据库,同列的数据通常被存储在一起,比较适合OLAP的场景。
在很多项目中,我们会同时用到PostgreSQL和ClickHouse,一个侧重业务,一个侧重数据分析。而难以避免的是我们可能需要将PostgreSQL中存储的一些业务数据同步到ClickHouse中,以便可以使用ClickHouse进行分析或为ClickHouse提供支持分析的一些数据。
比如我们可能需要分析应用日志,而日志可能在某些字段上有所缺失,此时就可能需要通过业务数据来进行日志补全操作。
或者我们的业务会产生大量的数据,如大量的用户订单或交易数据,此时我们准备对这些历史数据进行离线分析,试图从中找出一些模式或规律。这时虽然可以使用PostgreSQL来低效率强行完成这个工作,但毕竟“没有金刚钻”就不应该“揽瓷器活”,万一把业务数据库跑崩了…此时通常会将专业的事情交给专业的工具来做,不可避免地,又需要数据迁移/同步了。
当然,以上只是简单举例,实际项目中的架构也并非这么简单,可能会有专业的大数据一条龙,解决采集、清洗、补全、存储等等各阶段的问题。本文重在讨论需要从PostgreSQL业务数据库同步数据到ClickHouse分析数据库的场景。
PostgreSQL到ClickHouse之间的数据同步有很多方案,网上的介绍也比较多,比如使用ClickHouse的数据库引擎功能,可以连接到PostgreSQL,甚至基于此执行insert into ... select from ... 进行数据同步,具体参见 PostgreSQL | ClickHouse Docs;此外,还可以将PostgreSQL的数据导出到文件,然后通过文件导入到ClickHouse(应该没人这么用吧…),总之方法比较多,各有优势。
本文侧重描述分页查询+批量插入同步和基于流的数据同步两种方案,文中以CK表示ClickHouse,以PG表示PostgreSQL
传统的分页查询和批量插入
为何用这种方式?
可能不少读者会想,既然上文提到CK都提供了数据库引擎,可以让我们在CK中将PG当作“自家兄弟”一样SELECT和INSERT实现数据交换,那何苦又去分页查询然后再批量插入呢?况且分页查询在数据量大的时候还面临深分页问题,这不明摆着降低效率?
究其原因还是因为业务需要!虽然CK的数据库引擎看起来很诱人,但也存在一些问题:
- 使用CK的数据库引擎需要在CK中创建DATABASE连接到PG,此过程还需要PG的账户密码,存在维护问题
- 较难动态指定不同PG作为源和不同CK作为目的,即对于动态数据源的支持较差
- 使用这种不经过代码逻辑的数据交换过程,无法在数据传输过程中对数据进行一些变换,如无法执行字段值映射、翻译等中间转换过程
当然可能远不止上述问题,以上三点是笔者实际遇到的主要问题
因此,第一版数据同步便慢慢成型…
逻辑分析
分页查询+批量插入SQL可能是十分容易想到的解决方案,逻辑也十分简单:
- 触发同步
- 根据业务选择源PG库
- 分页查询需要同步的数据,指定每页查5000条数据
- 遍历查询到的数据,按指定逻辑进行转换
- 将转换后的数据批量插入到目标CK库
- 重复3~5,直到数据同步完毕
缺点分析
- 有潜在的深分页问题
- 每页查询出来的数据都需要到JVM内存中过一遍,可能会给新生代GC上强度
- 查询出来的数据一般是反序列化成Java对象后存在内存中,反序列化本身也会浪费不少性能
- 使用Mybatis等ORM框架进行批量插入的性能可能不如原生JDBC的批量操作,但换成原生JDBC批量操作也是治标不治本
- 如果排序字段选择有问题,分页查询可能会出现同一条数据出现在不同页或页边界数据丢失的问题
分页查询后批量插入本身的逻辑较为简单,此处略过具体代码实现示例
流式数据同步
如果把PG到CK的数据同步类比为将水从一个水桶转移到另一个水桶,那么分页查询+批量插入的方式就像是一个人拿了一个瓢,这个瓢的容量固定,每次都从一个水桶舀一瓢水,然后将瓢里的水倒入另一个水桶。很明显,这种方式需要反复舀水、倒水、舀水…而且水瓢的容积(分页大小)的选择也是技术活,若瓢太大,虽然一次可以转移更多水,转移次数也变少了,但是对拿水瓢的人要求就高了,必须要能拿得起;而瓢太小了,虽然可能小孩儿都能承担起这个任务,但往返次数变多了,时间自然也就久了。
而流式数据同步,就像是给这两个水桶之间加了一根管子,让水从一个桶直接流向另一个桶。水源源不断地从一个桶流向另一个桶,省去了我们舀水、倒水、再舀水…的操作。用水管运输水的过程中,水管中通常都是满的,而用瓢时,在将瓢移动到另一个桶并把水倒进去这个过程中瓢一直是被占用的,因此这段时间是有所浪费的。
流式数据同步想法从何而来?
在查阅众多关于PG和CK同步数据的资料之后,发现主要的方式还是利用CK的数据库引擎功能来进行数据交换,但正如前文所说,这种方式并不能满足一些特定的业务需求。在我快要妥协使用分页+批量插入这种方式时,我突然想到:数据同步不就是一个导入另一个导入吗?为何不先去研究研究PG和CK分别支持哪些数据导入、导出的方式?
有了这个想法后,开始查阅PG和CK的官方文档,发现CK支持从JSON、CSV、TSV等文件导入数据,具体参见Importing from various data formats to ClickHouse | ClickHouse Docs
而PG则通过COPY命令也恰好支持了导出到CSV、TSV等格式,具体参见PostgreSQL: Documentation: 14: COPY
理论可行,那么就可以通过将PG数据导出到CSV/TSV文件,然后将导出的文件导入到CK来实现PG和CK的数据同步,但这样很明显有个致命问题——需要中间文件。既然一头是输出,一头是输入,那能否像Java InputStream中的transferTo(OutputStream)一样直接将输入流的内容写到输出流呢?相当于将PG的输出直接连接到CK的输入?
因为是基于Java开发,连接PG或CK通常是要走JDBC驱动的,顺着这条路就开始搜索和PG的COPY命令相关的类,别说还真有一个名为CopyManager的类担当起了这个重任。有兴趣的读者可以参考官方文档了解更多 PostgreSQL® Extensions to the JDBC API | pgJDBC
在官方文档的示例中表明,CopyManager中有个名为copyOut(sql)的方法,可以将指定sql的查询结果输出。在IDEA中查看这个JDBC驱动包,定位一下CopyManager会发现还有一些相关的东西:
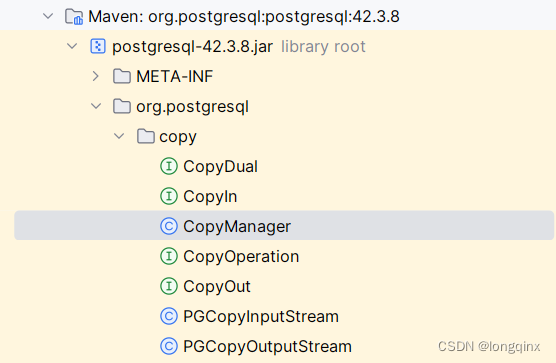
当你充满好奇地查看此包下的PGCopyOutputStream和PGCopyInputStream时,惊喜便来了。这里我们重点看与本文相关的PGCopyInputStream,这个类的注释是:
InputStream for reading from a PostgreSQL COPY TO STDOUT operation.
意思是PGCopyInputStream是用于读取PG的COPY TO STDOUT命令的输出的输入流
这里注意理清输入输出的关系,从PG的视角来说,执行COPY TO STDOUT是往标准输出输出数据,但对于我们Java程序来说,是要读到这个输出的数据。所以从自身程序的角度来说应该叫输入,所以对应PGCopyInputStream
能拿到这个PGCopyInputStream说明了在程序中得到PG的COPY命令的输出结果是没什么问题了。稍微想一下CK那边既然支持CSV/TSV导入,那大概率也是读文件进行的,都是读文件了,那直接给个文件流应该也支持吧?同样的方法,从JDBC驱动开始入手,看看CK都能通过JDBC支持哪些导入操作
对于CK来说,要找到这个功能没有像PG那么简单,CK的JDBC驱动按照官网的说法本质上是基于CK的Client API构建的,而Client API理论上可以执行所有CK客户端的操作,自然也就包括通过CSV/TSV导入数据。移步Client API的文档,有这么一个示例:
try (ClickHouseClient client = ClickHouseClient.newInstance(ClickHouseProtocol.HTTP);
ClickHouseResponse response = client.read(servers).write()
.format(ClickHouseFormat.RowBinaryWithNamesAndTypes)
.query("insert into my_table select c2, c3 from input('c1 UInt8, c2 String, c3 Int32')")
//这里表示可以从输入流获取输入插入CK
.data(myInputStream) // load data into a table and wait untilit's completed
.executeAndWait()) {
ClickHouseResponseSummary summary = response.getSummary();
summary.getWrittenRows();
}
具体文档参考:Java Language Client Options for ClickHouse | ClickHouse Docs
由于文档没有详尽列出所有功能,因此再看官方代码示例,发现有这么一个操作:
//意思就是如何unwrap JDBC连接来使用Client API
static String unwrapToUseClientApi(String url) throws SQLException {
String sql = "select 1 n union all select 2 n";
try (Connection conn = getConnection(url); Statement stmt = conn.createStatement()) {
// unwrap 得到 ClickHouseRequest
ClickHouseRequest<?> request = stmt.unwrap(ClickHouseRequest.class);
// server setting is not allowed in read-only mode
if (!conn.isReadOnly()) {
// not required for ClickHouse 22.7+, only works for HTTP protocol
request.set("send_progress_in_http_headers", 1);
}
//用ClickHouseRequest调用Client API执行操作
try (ClickHouseResponse response = request.query(sql).executeAndWait()) {
int count = 0;
// may throw UncheckedIOException (due to restriction of Iterable interface)
for (ClickHouseRecord r : response.records()) {
count++;
}
return String.format("Result Rows: %d (read bytes: %d)", count, response.getSummary().getReadBytes());
} catch (ClickHouseException e) {
throw SqlExceptionUtils.handle(e);
}
}
}
上述代码告诉我们,可以通过CK的JDBC Connection创建Statement,然后通过unwrap()方法来得到ClickHouseRequest,使用这个类的实例就能调用Client API
再来看看这个ClickHouseRequest,其内部包含了一个ClickHouseClient完成具体的CK操作,即上上个代码示例提到的Client API,这也印证了官方所说——CK的JDBC驱动是基于CK Client API构建的
既然如此,上上个示例中通过文件导入写入CK的操作自然也是可用了,好巧不巧,这个API在指定输入数据时,恰好需要一个InputStream,这不正合我们PGCopyInputStream的意吗?
PG到CK流式同步实现
结合PG的PGCopyInputStream,我们来看看流式数据同步的基本写法:
//迁移数据的SQL。格式为 COPY (select xxx ...) TO STDOUT
String pgSelectSQL = "COPY (select * from pg_table_name) TO STDOUT";
Connection ckConnection = getCKConnection();
Connection pgConnection = getPGConnection();
//通过SQL构建PG COPY数据输入流
PGCopyInputStream inputStream = new PGCopyInputStream(pgConnection.unwrap(BaseConnection.class), pgSelectSQL);
Statement statement = ckConnection.createStatement();
ClickHouseRequest<?> request = statement.unwrap(ClickHouseRequest.class);
ClickHouseResponse response = request.write()
//指定PG的COPY结果为CK输入
.data(inputStream)
//默认PG导出TSV格式,因此指定CK输入也为TSV
.format(ClickHouseFormat.TSV)
//指定数据写到CK的哪张表
.table("ck_table_name")
.executeAndWait();
整个数据同步过程就是如此简单,这里也不再一行行解读了。流式同步这种做法解决了一开始提到的分页查询+批量插入的所有不足:
- 不分页,所以不存在深分页问题
- 使用流,每次丢到内存中的数据取决于流缓冲区的大小,不会为每条记录生成新对象,也就不会担心过多新生代对象
- 每条记录不会构建成Java对象,不存在反序列化问题
- 不是多次批量处理,流处理可以稳定连续地进行
- 不分页,也就不会有分页导致数据重复或丢失问题
上述代码还有很多可扩展的地方,这里列出一二给各位读者找找灵感:
- 这里的PG查询SQL难道要单独写?是不是不太好维护?对于这个问题,我们可以使用Mybatis的SQL生成功能,只需要和平时使用Mybatis一样在Mapper中写SQL即可,动态SQL、参数拼接完全可以利用Mybatis的能力,我们只需要使用工具得到最终SQL就行了
- 从上述代码中可知,PG和CK的连接都可以在运行时指定,甚至可以从连接池中获取,这也就是说这种同步方式是天然支持多数据源、动态数据源的
PGCopyInputStream的数据默认是TSV格式,即每条记录一行,字段用制表符(Tab)分隔。如果需要对这些数据进行二次处理,则可以解析这个流处理之后再给到CK
思想迁移
流式传输的思想应用不仅局限于此,在需要数据写入或写出的地方都可以想想是否能够用流来传输,而不是每次查出一些数据处理。流具有内存占用低、稳定、速度快等等优势,将其应用到大量数据导出到Excel等场景也是比较合适的
COPY命令是PostgreSQL所特有的,那么其他数据库怎么办?其实JDBC还有一种叫做游标查询的查询方式,Mybatis、Mybatis-Plus等框架也有相应的流式查询封装,它们的思想都是一致的,也相当于是一种流式查询,即不一次性把所有目标记录读出来,而是逐行处理,这样就会减轻内存负担。
性能简单比较
笔者针对分页+批量插入和流式同步两种方式做了简单的对比测试,数据量从100开始到100w,每种数据量下测试3次,其中CK和PG部署在同一个服务器上,在不同的docker容器中运行。虚拟机中服务器配置如下:
| 项目 | 配置详情 |
|---|---|
| 内存 | 2G |
| 处理器(i5 12代) | 1个 × 4核 |
| 硬盘 | 40G |
本次测试仅测试单表的数据同步,即PG和CK中有同样结构的表,程序代码完成从PG表到CK表的数据同步。表中共有10个字段,每个字段都是VARCHAR类型,且长度为32,字段中存储的值都是32位的UUID,每次测试时CK和PG中都没有存量数据
测试结果如下:
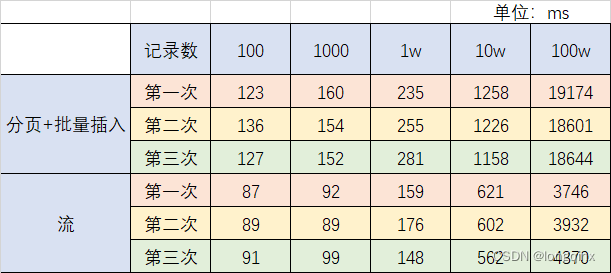
虽然本次测试比较粗糙,指标也比较少,只侧重任务完成消耗的时间,但也能从一定程度上反映出流式数据传输所的优势。从表中可以看出在数据量少的情况下,流式同步比分页+批量插入快约1.5倍,而随着数据量的增加,这种差距也在逐渐拉大,100w数据时差距达到了5倍
这还是使用原生JDBC的批量插入的情况,即没使用任何ORM框架,也就没有额外的反射成本,如果算上反射带来的性能消耗,那这个差距只会更大
同时,在实际的使用中,业务可能并非单表同步这么简单,可能会将联表查询后的数据写入CK,考虑到这种种情况,流带来的性能提升会越来越明显
有兴趣的读者可以在此测试的基础上将监测一下同步过程中Java堆内存的变化情况、关注一下新生代GC次数等等指标,或许能从中发现一些新的东西
测试使用代码参考附录
总结
- 利用PG的
COPY命令可以快速导出大量数据 - PG的JDBC驱动中,
PGCopyInputStream类可以用于读取COPY命令输出到标准输出的数据 - CK的JDBC驱动是基于CK的Client API实现的,可通过
Statement的unwrap()方法获取ClickHouseRequest - 可以使用CK的Client API实现将CSV/TSV等格式数据导入CK的功能
- CK的Client API可以接受一个CSV/TSV等格式数据的输入流,并将这些数据写到CK指定表中
- 结合上述特性,可以将
PGCopyInputStream传递给ClickHouseRequest的write()操作进行PG到CK的数据传输
附录-性能测试代码
package com.lonqinx.util;
import com.clickhouse.client.ClickHouseFormat;
import com.clickhouse.client.ClickHouseRequest;
import com.clickhouse.client.ClickHouseResponse;
import org.postgresql.copy.PGCopyInputStream;
import org.postgresql.core.BaseConnection;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
public class SyncTest {
public static void main(String[] args) throws Exception {
Class.forName("org.postgresql.Driver");
Class.forName("com.clickhouse.jdbc.ClickHouseDriver");
Connection pgConnection = DriverManager.getConnection("jdbc:postgresql://192.168.121.128:5432/postgres", "postgres", "123456");
Connection ckConnection = DriverManager.getConnection("jdbc:clickhouse://192.168.121.128:8123", "default", null);
//实际测试时需要注释掉其中一个
// testPageAndBatchInsert(pgConnection,ckConnection);
testStreamTransport(pgConnection, ckConnection);
}
public static void testPageAndBatchInsert(Connection pgConnection, Connection ckConnection) throws Exception {
int page = 0;
int size = 5000;
List<TestEntity> dataList;
long start = System.currentTimeMillis();
do {
dataList = getPage(pgConnection, page, size);
batchInsertToCK(ckConnection, dataList);
page += 1;
} while (dataList.size() == size);
long cost = System.currentTimeMillis() - start;
System.out.println("page query + batch insert -> cost " + cost + "ms");
}
public static void testStreamTransport(Connection pgConnection, Connection ckConnection) throws Exception {
String sql = "COPY (SELECT * FROM test_pg_table LIMIT 7000000) TO STDOUT";
PGCopyInputStream inputStream = new PGCopyInputStream(pgConnection.unwrap(BaseConnection.class), sql);
Statement statement = ckConnection.createStatement();
ClickHouseRequest<?> request = statement.unwrap(ClickHouseRequest.class);
long start = System.currentTimeMillis();
ClickHouseResponse response = request.write()
//指定PG的COPY结果为CK输入
.data(inputStream)
//默认PG导出TSV格式,因此指定CK输入也为TSV
.format(ClickHouseFormat.TSV)
//指定数据写到CK的哪张表
.table("test_ck_table")
.executeAndWait();
response.close();
statement.close();
long cost = System.currentTimeMillis() - start;
System.out.println("stream -> cost " + cost + "ms");
}
public static List<TestEntity> getPage(Connection pgConnection, int page, int size) throws Exception {
PreparedStatement statement = pgConnection.prepareStatement("SELECT * FROM test_pg_table OFFSET ? LIMIT ?");
statement.setInt(1, page * size);
statement.setInt(2, size);
ResultSet resultSet = statement.executeQuery();
List<TestEntity> result = new ArrayList<>();
while (resultSet.next()) {
TestEntity entity = new TestEntity();
entity.setId(resultSet.getString(1));
entity.setCol1(resultSet.getString(2));
entity.setCol2(resultSet.getString(3));
entity.setCol3(resultSet.getString(4));
entity.setCol4(resultSet.getString(5));
entity.setCol5(resultSet.getString(6));
entity.setCol6(resultSet.getString(7));
entity.setCol7(resultSet.getString(8));
entity.setCol8(resultSet.getString(9));
entity.setCol9(resultSet.getString(10));
result.add(entity);
}
statement.close();
return result;
}
public static void batchInsertToCK(Connection ckConnection, List<TestEntity> dataList) throws Exception {
PreparedStatement statement = ckConnection.prepareStatement("INSERT INTO test_ck_table(id, col1, col2, col3, col4, col5, col6, col7, col8, col9)VALUES(?,?,?,?,?,?,?,?,?,?)");
for (TestEntity entity : dataList) {
statement.setString(1, entity.getId());
statement.setString(2, entity.getCol1());
statement.setString(3, entity.getCol2());
statement.setString(4, entity.getCol3());
statement.setString(5, entity.getCol4());
statement.setString(6, entity.getCol5());
statement.setString(7, entity.getCol6());
statement.setString(8, entity.getCol7());
statement.setString(9, entity.getCol8());
statement.setString(10, entity.getCol9());
statement.addBatch();
}
statement.executeBatch();
statement.close();
}
}















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









