







11.1直接寻址表
为表示动态集合,我们用一个数组称直接寻址表记为T[0...m-1],其中的每个位置称为槽,对应于关键字的全域U。若集合中没有关键字为k的元素则T[k] = nil
class OBJECT():
def __init__(self, key):
self.key = key
self.data = None
def DIRECT_ADDRESS_SEARCH(T, k):
return T[k]
def DIRECT_ADDRESS_INSERT(T, x):
T[x.key] = x
def DIRECT_ADDRESS_DELETE(T, x):
T[x.key] = None
11.2 散列表
对直接寻址而言,若全域U非常巨大则需要很大的存储空间T,但时间存储集合K很小T的大部分都是nil,则显得太不经济。我们希望能有一种方法,即保持直接寻址表的theta(1)时间查找,又不需要巨大的存储空间T。我们可以采用散列函数h,由关键字k计算出槽的位置,再将该元素放在槽h(k)中。h为全域U到散列表T的映射,T要比U小很多。对于关键字k通过函数h映射到h(k),我们称将k散列到散列值h(k)。因为T比U小的多,故存在多个U中的元素映射到T中的元素的情形,我们称之为冲突。我们需要找到方法来避免或处理冲突。
链接法解决冲突:我们将输入尽可能平均的散列到散列表中,散列表中使用双向链表,将h(k)相同的元素插入到双向链表的头部,查找时遍历双向链表,删除时直接从双向链表中删除,输入规模为n,散列表个数为m,每个链表长度的期望值为 a = n/m。
class LISTNODE():
def __init__(self, key):
self.key = key
self.prev = None
self.next = None
class DL_LIST():
def __init__(self):
self.nil = LISTNODE(None)
self.nil.next = self.nil
self.nil.prev = self.nil
class CHAINED_HASH_TABLE():
def __init__(self, n):
self.table = [DL_LIST() for i in range(n)]
def hash_function(self, k):
return k
def DL_LIST_SEARCH(L, k):
x = L.nil.next
while x != L.nil and x.key != k:
x = x.next
return x
def DL_LIST_INSERT(L, x):
x.next = L.nil.next
L.nil.next.prev = x
L.nil.next = x
x.prev = L.nil
def DL_LIST_DELETE(L, x):
x.prev.next = x.next
x.next.prev = x.prev
def CHAINED_HASH_INSERT(T, x):
node = LISTNODE(x)
DL_LIST_INSERT(T.table[T.hash_function(x)], node)
def CHAINED_HASH_SEARCH(T, k):
return DL_LIST_SEARCH(T.table[T.hash_function(k)], k)
def CHAINED_HASH_DELETE(T, x):
DL_LIST_DELETE(T.table[T.hash_function(x.key)], x)



11.3 散列函数
一个好的散列函数要尽量满足简单均匀散列假设:每个关键字都独立的、等可能的散列到m个槽中。对于非自然数的关键字需要转化为关键字。
除法散列,通常选取一个不太接近2的整数幂。
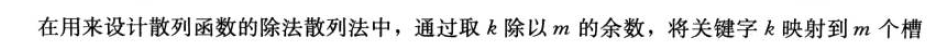

乘法散列:通常对m的选择不是特别关键,一般选取黄金分割0.618。
全域散列法:对于散列函数的可能出现的最坏情况,我们通过在一组精心设计的散列函数中,随机的选取一个,使得算法具有较好的平均性能。设H为一组有限散列函数,它将给定的关键字全域U映射到{0,1...m-1}中,这样的一组函数称为全域的,若从H中随机选择一个散列函数,当关键字k!=l时,两者发生冲突的概率不大于1/m。


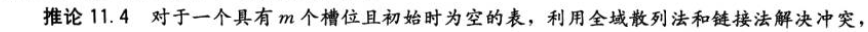

设计一个全域散列函数:



11.4 开放寻址法
由于链表法解决冲突需要额外的空间来存储指针。当可以预计n小于m时,我们通过多次探查直到找到一个空的位置来存储元素。则需要散列函数对每一个关键字k,当探查的次数为1到m-1时,可以映射到散列表的所有槽。

以一次探查为例的实现:
class OBJECT():
def __init__(self, key):
self.key = key
self.data = None
class OPENADDRESS_HASH_TABLE():
def __init__(self, n):
self.table = [None for i in range(n)]
self.size = n
def __getitem__(self, key):
return self.table[key]
def __setitem__(self, key, value):
self.table[key] = value
def hash_help(self, k):
return k
def hash_function(self, k, i):
return self.hash_help(k) + i
def show(self):
for i in self.table:
if i != None:
print(i.key)
else:
print(i)
def OPENADDRESS_HASH_INSERT(T, x):
i = 0
while i != T.size:
j = T.hash_function(x.key, i)
if T[j] == None:
T[j] = x
return j
else:
i = i + 1
raise("hash table overflow")
def OPENADDRESS_HASH_SEARCH(T, k):
i = 0
while i != T.size:
j = T.hash_function(k, i)
if T[j] == None:
break
elif T[j].key == k:
return j
else:
i = i + 1
return None
def OPENADDRESS_HASH_DELETE(T, x):
i = OPENADDRESS_HASH_SEARCH(T, x.key)
if i != None:
T[i] = OBJECT(None)



双重散列是更合适的技术,一次探查和二次探查会碰到一次集群跟二次集群的问题。
我们在均匀散列的假设下对开放地址法的性能进行分析,有如下结论:



11.5 完全散列
当关键字集为静态的,完全散列提供一种在最坏情况下用O(1)次存访完成。可以采用两级散列方法来设计完全散列,在每级上使用全域散列。通过适当时选择二级函数,使得在二级散列中不会出现冲突,而通过选择适当的一级散列使其均匀散列,将预期使用的总体空间限制为O(n)。
以下原理证明存在这样的函数



















 466
466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









