







 本文探讨了Facebook研究院发布的逆向烹饪项目,利用深度学习技术从食物图片生成食谱,包括食材和烹饪步骤。研究采用了Transformer结构并进行了多模态改进,通过对比不同模型结构,发现Concatenated结构表现最佳。实验使用Recipe1M数据集,详细介绍了数据预处理和模型参数设置。
本文探讨了Facebook研究院发布的逆向烹饪项目,利用深度学习技术从食物图片生成食谱,包括食材和烹饪步骤。研究采用了Transformer结构并进行了多模态改进,通过对比不同模型结构,发现Concatenated结构表现最佳。实验使用Recipe1M数据集,详细介绍了数据预处理和模型参数设置。
Paper:https://arxiv.org/abs/1812.06164
Code:https://github.com/facebookresearch/inversecooking
1.论文整理框架:
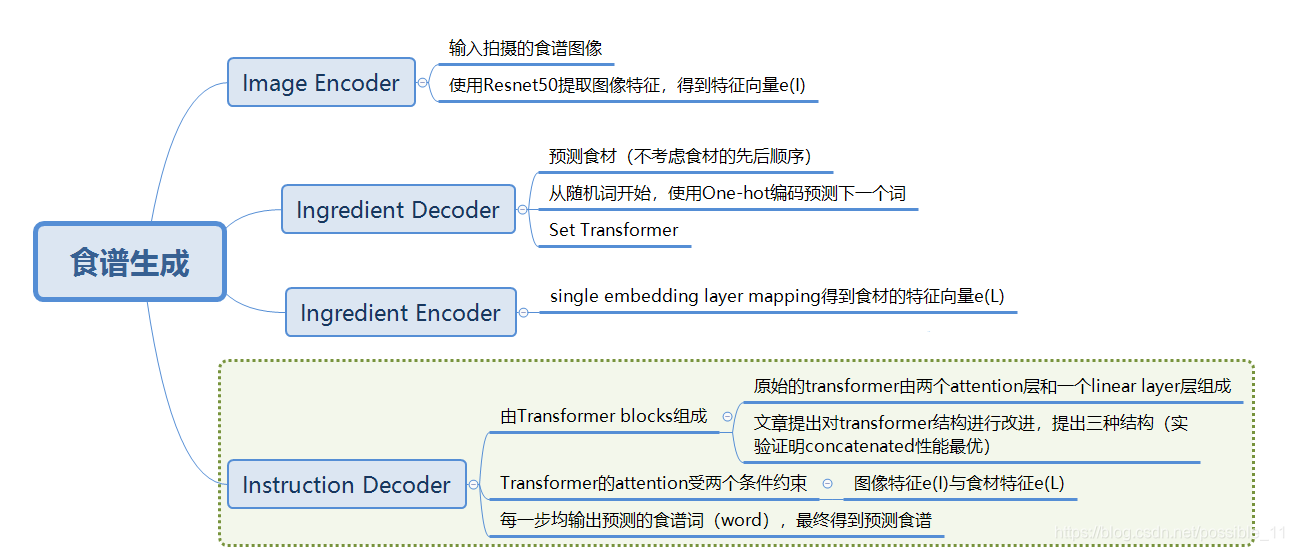
算法框架如下图所示:
2. 部分模块:
1)Ingredient Decoder
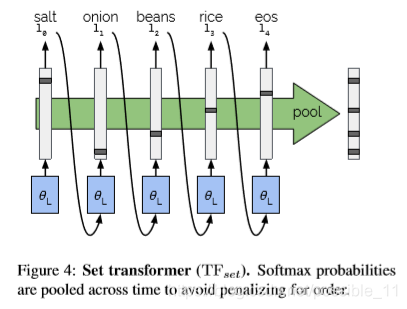
无序食材的预测较为简单,本文对不同时间的输出进行max pooling操作从而消除食材的顺序;
eos loss:Binary cross-entropy loss,eos在pooling后会失去位置信息,因此计算max pooling后的食材与实际食材之间的
误差不太合理;提出eos loss计算所有time中predicated eos probability与ground truth之间的误差
2)Instruction Decoder
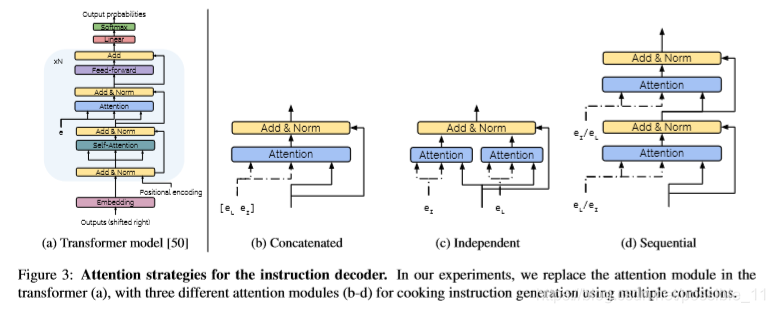
(a)原始的Transformer结构:两层attention与一层linear layer组成,第一个attention是对先前的输出进行自我监督,第
二个attention是refine自我监督的输出,最后加入softmax与linear用来分配预测的食谱单词;适用于单模态任务。
(b)Concatenated:本文着重于多模态来生成食谱(图像+食材),因此对transformer进行了改进;e(I)与e(L)直接拼接
送入attention中。
(c)Independent:e(I)与e(L)分别送入attention中(互不影响),最终将attention合并;
(d)Sequential:按顺序进行;考虑两种情况,image first(e(I))->Ingredient(e(L));Ingredient first(e(L))->image(e(I))
最终实验结果证明:Concatenated结构性能最优。
3.实现细节:
1)dataset
本文采用Recipe1M数据集,对数据集进行于预处理,仅采用包含食谱图片,食材与instruction不小于2的食谱(约31万)
食谱格式如下图所示:
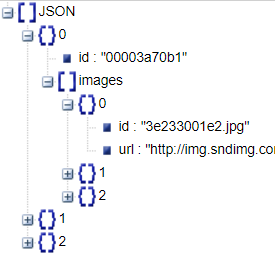
Recipe1M包含two layer,存储均为字典类型。其数据结构如下:
① layer1.json
食谱信息:食材、食谱url、数据集类型(训练/验证/测试)、标题、id、步骤
② layer2.json
图片信息:id、图片(id、url)
两个layer层相关联的Json数据结构如下图:

![]()
2)参数设置

思考:
比较食谱生成与食谱retrieval,recognition


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









