








Postgresql 10 HASH分区实现
前面简单介绍了postgres10分区相关情况,里面谈到基于postgres10这套分区实现hash分区比较麻烦,但仔细考虑后发现其实也是可以实现的,下面介绍在原有range/list基础上比较粗糙的hash分区的实现 。
注意:本文中思路及后附代码是研究学习用,由于本人水平限制,难免会有遗漏及错误的地方,不保证正确性,并且是个人见解,希望能抛砖引玉,发现问题欢迎留言指正。
整体思路简介:
1. 建主表时要确定好分区个数,每个子表上标号是第几个分区。
2. 语法尽可能的和range、list风格相近,相关的系统表也用之前的,pg_partitionen_table系统表增加一个字段存分区表个数。
3. insert时通过分区键直接找到要插入的子表.
4. select时约束排除沿用原来的接口进行扩展过滤.
语法篇:
先看看range和list,既然都是分区就尽量的和之前的保持一致:
RANGE分区表:
create table tr(a int,b int) partition by range(a);
create table tr_1 partition of tr for values from (1) to (10);
create table tr_2 partition of tr for values from (10) to (100);
LIST分区表:
create table tl(a int,b int) partition by list(a);
CREATETABLE tl_1 PARTITION OF tl FOR VALUES IN (2);
CREATETABLE tl_2 PARTITION OF tl FOR VALUES IN (3);
对于LIST与RANGE分区,建主表二者语法一样,只有类型区别,建子表则差异较大,list是多个点的集合,range是一个区间,分别描述字表分区键值的范围。那么对hash分区来说,语法怎么设置比较合理呢?首先分区类型肯定要保持一致写法,如下把LIST、RANGE换成hash:
create table th(a int,b int) partition by hash(a);
那么对于子分区表呢?hash子表分区键的范围既不是list那样的多个点的集合,也不是一个范围区间,只要hash值等于某个分区的位置即可认为是该值应该在这个分区中,因此子表不需要额外说明,建议语法如下:
create table th_1 partition of th;
create table th_2 partition of th;
create table th_3 partition of th;
但对于hash分区来说,分区个数决定着每行记录归属的子表,因此分区数需要先决定,不允许增加或删除子表(可以实现子表增删,但需要对部分或全部数据移动调整,本文不讨论,有兴趣者可看看oracle hash分区),所以创建主表时需要加上分区数量,完整语法如下:
create table th(a int,b int) partition by hash(a) partitions 4;
create table th_1 partition of th;
create table th_2 partition of th;
create table th_3 partition of th;
create table th_4 partition of th;
创建的第一个表为第一个子表,第二个表是第二个子表,以此类推,第n个建的表为第n个子表。
必须保证满足如下几条:
1. 主表指定的分区数量必须和后面建的子表数量一致,否则报错。
2. 不允许alter table attach/detach 修改hash分区表
3. 不允许单独drop hash分区子表
当create hash分区时,与list或range比主要是要多存一个信息:hash 分区数。如
create table th(a int,b int) partition by hash(a) partitions 4;
把4存入pg_partitionen_table系统表中,增加一个字段专门存hash分区数。在 StorePartitionKey 函数增加了一个整型参数,另外对分区类型判定调整到了parser模块中,前一篇已经介绍过相关疑问,在这修改了原来逻辑,不再在transformPartitionSpec中进行字符串比较后再判断是list/range/hash分区,transformPartitionSpec 函数去掉了分区类型的参数,内部删掉分区类型的检测判断逻辑。
语法、建表相关代码详见后附的差异文件gram.y、tablecmds.c、heap.c等文件。
数据插入篇:
前文详细介绍过,pg10的分区插入不再使用规则或触发器方式,直接在insert时根据value计算出目标子表,大幅提高insert性能,那么insert分区表性能的极致是什么呢?如果insert分区表和insert一个普通表的时间一样,那么这就是我认为的insert 性能极致。比方说,一千个分区的分区表,在第一千个子表插入100W记录的时间和非分区的单表插入100W记录的时间是一样的,那么我便认为insert性能已经到了极致。为什么要谈这个?因为这是我的小目标。
言归正传,前文介绍了,ExecInsert函数中ExecFindPartition函数确定子分区,里面又是 get_partition_for_tuple函数找到,再往下通过partition_bound_bsearch进行查找,最终是根据不同类型,调用不能的比较函数,进行二分查询,要把所有的子表上的分区范围信息比较找一次。对于HASH分区,我们无需对所有子表分区范围信息进行比较来确定是哪个分区,只要有分区数和要插入的分区键的value值就能计算出目标子表。在get_partition_for_tuple函数增加HASH分区求子分区位置逻辑:
if (key->strategy ==PARTITION_STRATEGY_HASH)
{
….
returnget_index_by_hash(value, col_type,nparts);
}
如果是hash分区,增加函数get_index_by_hash来求目标子表位置,传入三个参数:分区值的键值,分区键的类型,总的分区个数。
在get_index_by_hash中则根据类型分别调用该类型的hash函数计算hash值,最终的位置计算式如下:
Result = (hash(value) % nparts + nparts) % nparts;
hash(value): 调用相关hash函数通过传入的value计算出的hash值
nparts:总的分区个数
insert 插入逻辑增加的关键代码不多,简单才能高效,具体细节请看partition.c文件。最终插入性能比较理想,对于一千个hash子表的hash分区表,在第一千个子表插入100W行数据和单表插同样的数据100W行,时间几乎没什么区别。
实测结果如下图:
首先建1000个hash分区表,时间约1.5秒:
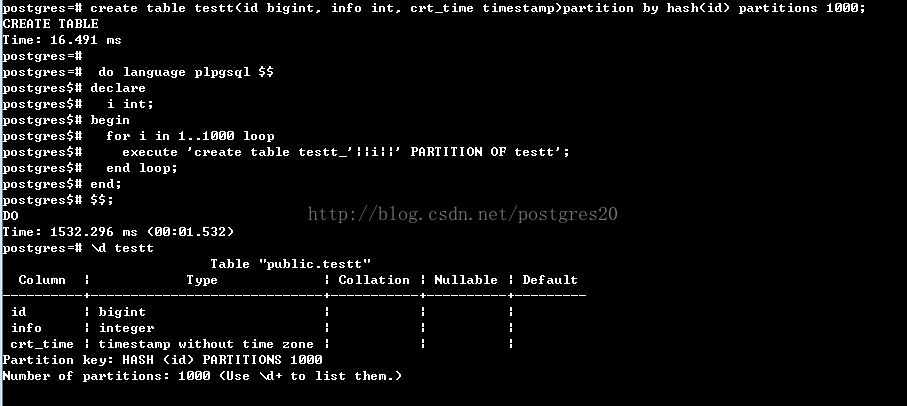
对比range分区,1000个子表约要40秒,如下图:
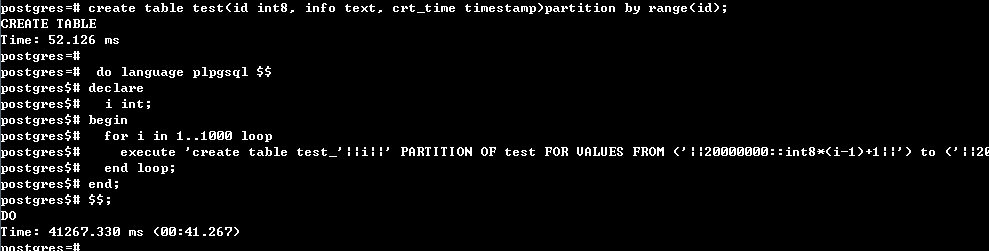
随机插入100W行记录:时间约6.5秒,并看每个分区的记录数是否均匀,100W分区到1000个区,那么理论上每个区1000条左右,见下图:
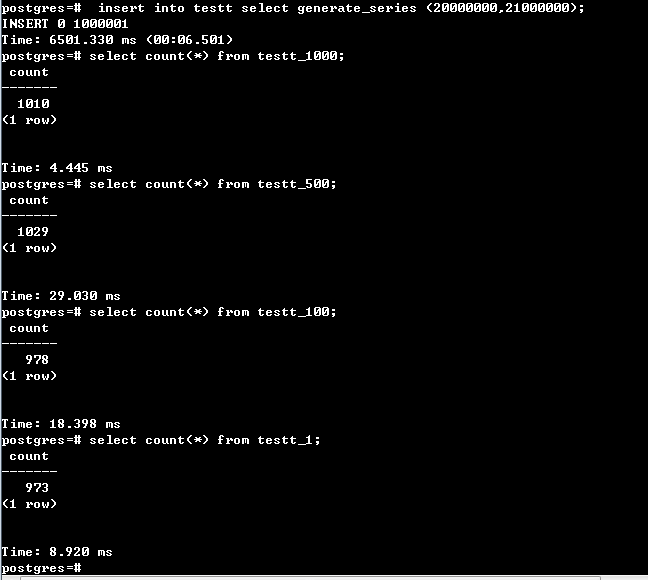
然后进行最关心的插入性能测试,固定插第1000个子表和插非分区表100W行记录对比时间,testt为分区表,tt为普通表。红线为分区表的,蓝线为普通表,两个都插了三次,时间有高有低,并不稳定,但总体上可以两者认为是差不多的,最后统计了下第1000个分区的记录数是正确的,说明的确是插进去了。
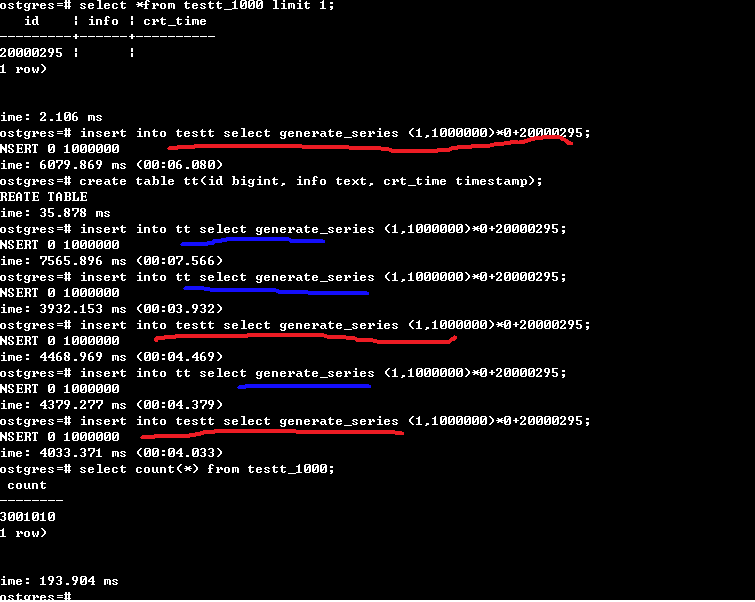
由于固定插入某个表的时间变化大,于是我又测了下在1000个范围内随机插入100W行记录,发现在1000个子表中随机插入时间其实和插一个子表应该也是差不多,并没慢多少
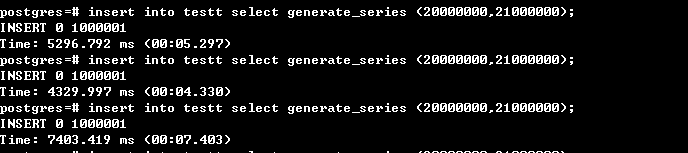
最终结论:时间不稳定和我的测试平台为普通机器、数据库本身、及测试方法有关系,如果都取最优值话,可以粗略的认为1000个子表的hash分区插入100W行时间与插入一个普通表基本持平,达到我的小目标。
数据查询篇:
前文介绍过,postgres10分区剪枝是把分区范围信息经过转换处理成和约束相同的结构,
relation_excluded_by_constraints函数中的predicate_refuted_by排除函数就可以当成约束直接处理,将不需要扫描的表过滤掉。同样,hash分区排除逻辑也类似,但是不能造一个约束让predicate_refuted_by去过滤,因为postgres 默认逻辑不能处理hash分区的情况,我们需要抽值出来组成新的结构,执行后再做比较判断,因此在这简单实现了一套函数。
relation_excluded_by_constraints中原来排除逻辑走完后,对hash分区,再做一次检查:
bool
relation_excluded_by_constraints(PlannerInfo *root,
RelOptInfo *rel, RangeTblEntry *rte)
{
List *safe_restrictions;
List *constraint_pred;
...
if (predicate_refuted_by(safe_constraints, rel->baserestrictinfo))
return true;
if (NIL != root->append_rel_list)
{
...
//hash分区则进行判断
if (simple_equality_predicate_refuted((Node*)safe_constraints, Node*)rel->baserestrictinfo))
return true;
}
return false;
}simple_equality_predicate_refuted逻辑简介:
还是以语句为例,在上面截图中的1000个分区的分区表testtt,执行如下语句:
select * from testt where id =20000000;
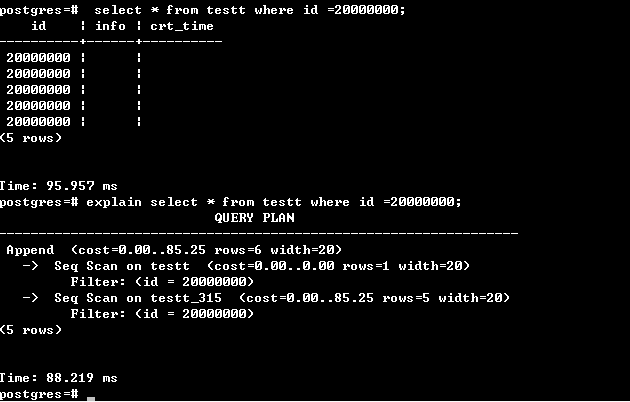
这里能否剪枝的关键显然是where 条件 id =20000000 控制, 在此必须需要和insert时保持一致的算法才能找到正确的子表,也就是说一样要满足:
Result = (hash(value) % nparts + nparts) % nparts;
这里面nparts是知道的,value是传进来的,也是知道的,hash函数需要根据类型去找出来,也是知道的,那么理论上计算出result是没问题的。但在这里有一个问题要解决,我们在构造约束或者说计划时,value是变量,不是常量,比方说对于第1个子表,约束是:
(hash(value) % nparts + nparts) % nparts =1
这里nparts换成1000就是
(hash(value) % 1000 + 1000) % 1000 ==1
这里的value只是个列,表testt的id列,而我们的值 id=2000000的这个20000000在另外的表达式中,所以我们要找到它,并且放入hash函数中,变成如下的式子:
(hash(20000000) % 1000 + 1000) % 1000 ==1
这样的式子拿到后,再计算它的值,true要需要扫描,false不需要。显然,对于id = 20000000的1000个子表的hash分区只有一个表是要扫描的,其它全应该过滤。
这就是simple_equality_predicate_refuted干的主要工作,拿到相关结构替换构造一个新的表达式,再调用执行器计算这个结果,详细代码请看plancat.c文件,需要提一下的是,由于时间原因,目前只支持hash分区表中单个条件的过滤,以后有空再研究多个条件过滤。
在上面,构造 hash(value)函数是在postgres的get_qual_from_partbound中,增加了hash分区的处理函数get_qual_for_hash,细节逻辑不详细介绍了,就是构造了一个 (hash(value) % nparts + nparts) % nparts 的表达式,有兴趣的可以看看相关代码,逻辑比较简单。
另外,在实现过程中,hash过滤我也考虑过像insert一样,直接定位子表,不再遍历子表的list, 提高性能,但分析后发现在现有约束排除机制上实现太过麻烦,可能要重新实现一套独立的分区剪枝函数,难度估计超过个人能力了,业余时间没这么多,只好放弃等postgres 官方来推进。
这里的大多数代码都在partition.c中。
备份恢复篇
增加了一种新的分区表,备份恢复肯定要处理下。这里最大的问题在于建表时,并不需要指定子表是第几个,而是由建立的先后顺序由内部逻辑定是第几个子表。这样做方便建表,但是对于备份就有些麻烦了,我们dump出表结构时,并不一定是按我们create的先后顺序,如果原来第1个子表是第2个顺序建,那么数据就进不去了,会被约束给限制住,所以我们在dump时需要按原来的Create顺序排序建表,详细的可以看看dump相关几个修改文件。
其它:
其它还有一些比较简单的,像禁止alter attach/ detach hash表,禁止drop hash子表,\d、\d+ hash表修改,srtingtonode、nodetostring支持hash,RelationBuildPartitionDesc 中的hash表排序,等等,大家有兴趣者可以看看,欢迎大家提出更优的改进建议。
本文中涉及的全部hash分区代码下载
下载链接:http://pan.baidu.com/s/1bp7UMtD 密码:l1vc
代码版本:基于官方git 2016/12/12 02:09:57 Tom Lane 最后一次提交为基线开发,patch差异文件可以直接基于这个点的版本应用patch( 官方开发线代码直接 git clone git://git.postgresql.org/git/postgresql.git 即可下载到本地)。
下载后直接把patch打到上面的基线上即可这些代码合并进去,合并进去后建议先跑下回归有没有问题,我这边是没有问题的。
更多postgresql 内核学习开发相关文章请点击进入我的博客查看

















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









