%matplotlib inline
import random
import numpy as np
import scipy as sp
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
import statsmodels.formula.api as smf
part1
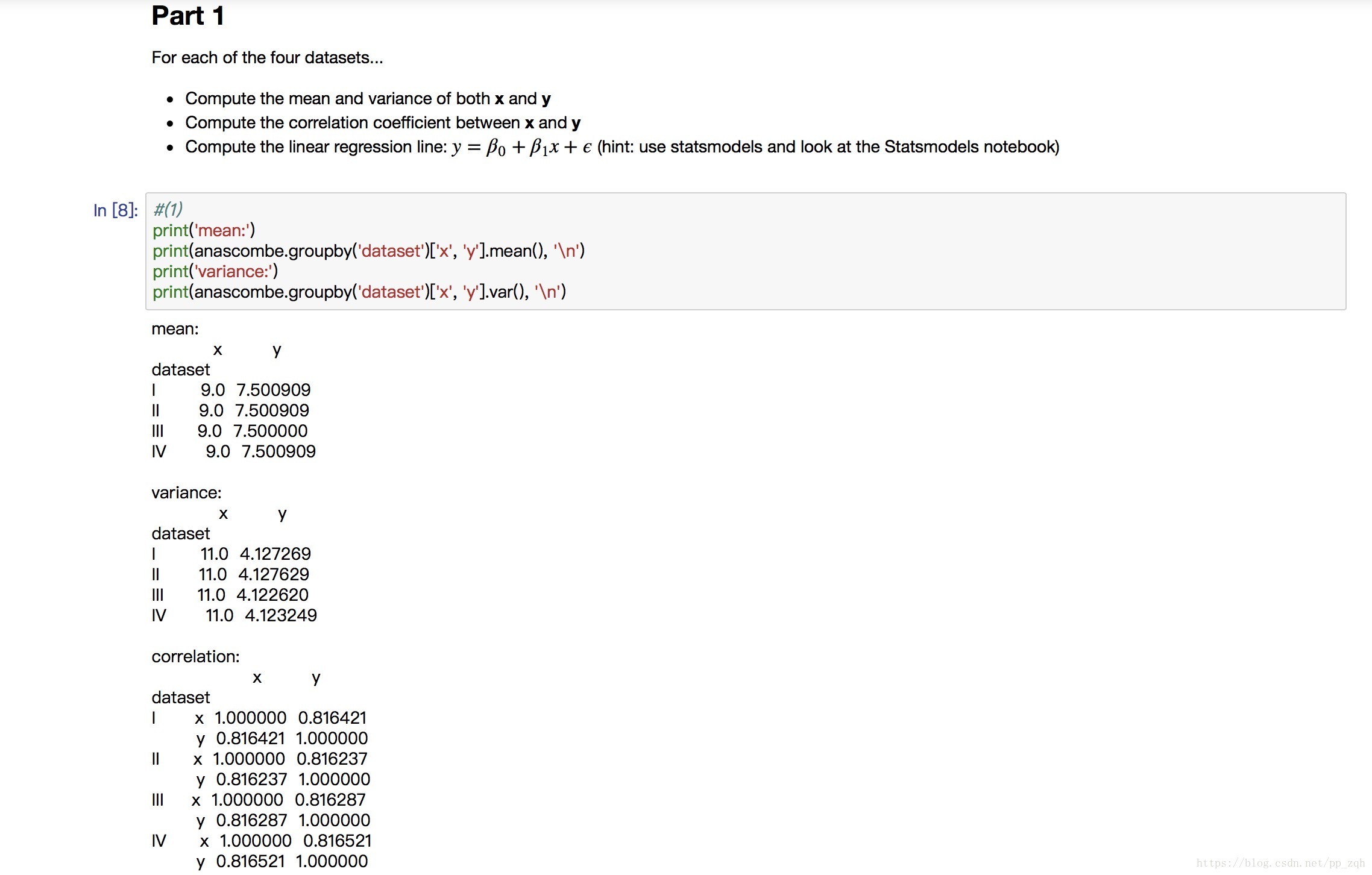
###part 1#(1)
print('mean:')
print(anascombe.groupby('dataset')['x', 'y'].mean(), '\n')
print('variance:')
print(anascombe.groupby('dataset')['x', 'y'].var(), '\n')
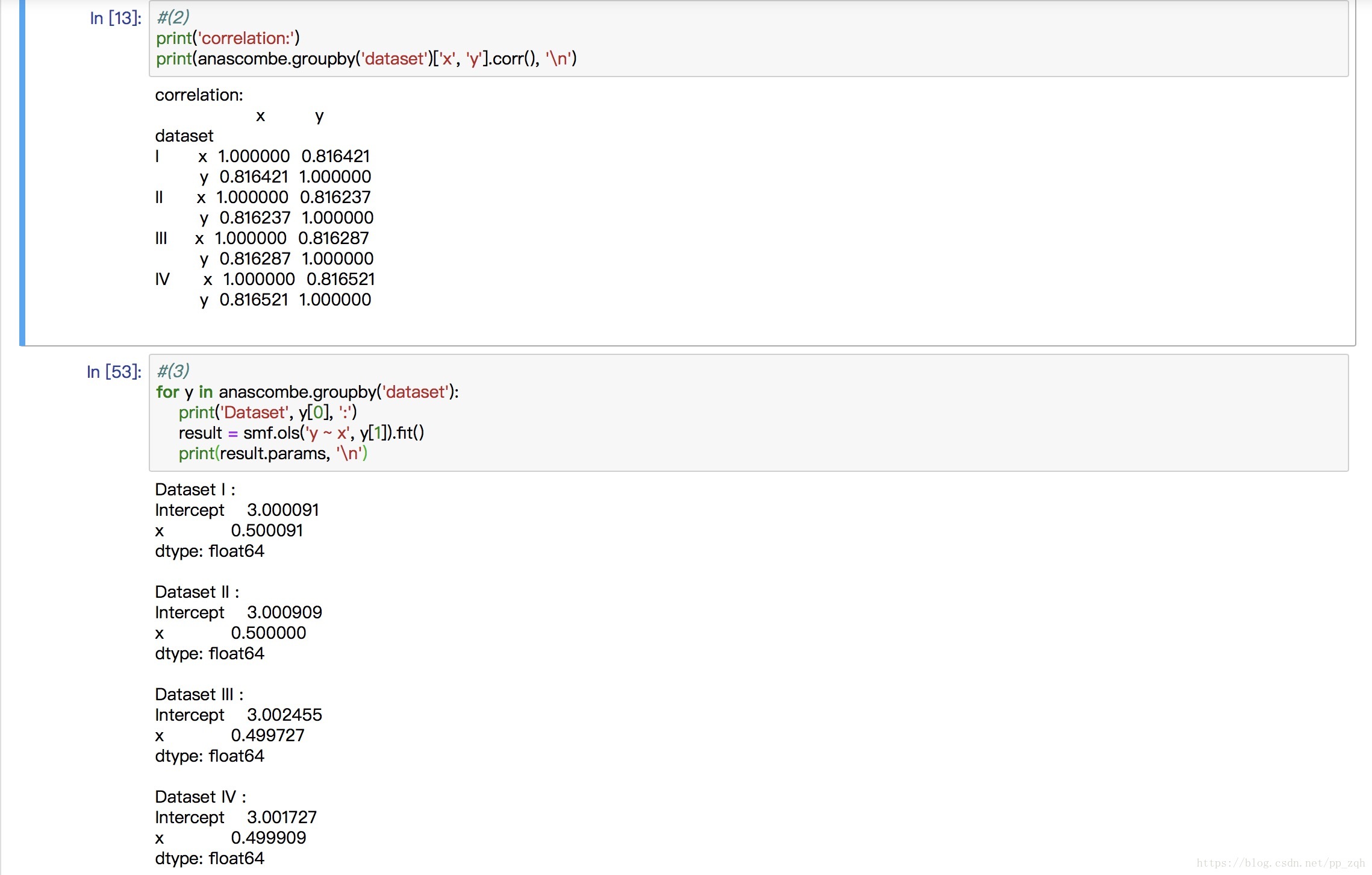
#(2)
print('correlation:')
print(anascombe.groupby('dataset')['x', 'y'].corr(), '\n')
#(3)for y in anascombe.groupby('dataset'):
print('Dataset', y[0], ':')
result = smf.ols('y ~ x', y[1]).fit()
print(result.params, '\n')
代码均在jupyter notebook上运行%matplotlib inlineimport randomimport numpy as npimport scipy as spimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport statsmodels.api as sm...





















 209
209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









