







一、综合训练要求
案例中需要处理的文件为nba.csv,该文件记录了NBA历年总冠军的详细情况,文件的字段从左到右依次为比赛年份、具体日期、冠军、比分、亚军和当年MVP(联盟MVP是Most Valuable Player缩写,即最有价值球员),每个字段以半角逗号“,”进行分割,如图1所示。

图1 NBA原始文件数据
本训练要求对此数据集做如下处理:
(1)数据清洗;
(2)统计各球队获得冠军数量;并将东西部球队的统计结果分别存储。
二、实现过程
(一)数据处理说明
NBA的历史较为久远,从1947年至2019年的这段时间里,一些球队已经不存在了(例如:芝加哥牡鹿队),还有部分球队的队名发生了变化(例如:明尼阿波利斯湖人队,现在的名称是洛杉矶湖人队);所以,对于已经不存在的球队,继续保存其名称,不做修改;但是已经更改名称的球队,需要映射为现在球队的名称;
另外,因为要对球队进行东西分区的统计,所以要对球队添加东西分区的标识。
(二)解题思路
添加球队新老名称的映射,读取每行数据时,遇到老的名称,将其替换为新名称;添加东西分区球队的映射,读取数据时,分析冠军球队所在分区,然后添加标识(东部球队以“E”标识,西部球队以“W”标识,未分区的球队以“F”标识)
需要注意的是,美国NBA联盟是从1970年开始进行东西分区的,因此需要对年份进行判断。
(三)核心代码
import pandas as pd
import re
pd.set_option("display.unicode.east_asian_width",True)
pd.set_option('display.width',1000)
pd.set_option('display.max_columns',None)
data = pd.read_excel("NBA.xlsx")
team_new_old = []
team_old = []
dict_team = {}
with open('新旧队名映射.txt','r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
line = re.sub("\n","",line)
team_new_old.append(line)
for s in team_new_old:
result = s.split("->")
team_old.append(result[0])
dict_team.update({result[0]:result[1]})
for i in range(0,len(data['冠军'])):
if data['冠军'][i] in team_old:
data.loc[i,'冠军'] = dict_team[data['冠军'][i]]
if data['亚军'][i] in team_old:
data.loc[i,'亚军'] = dict_team[data['亚军'][i]]
# 以下代码对队伍进行分区
team_east = []
team_west = []
with open('东部球队队名.txt','r', encoding='utf-8') as f:
lines_east = f.readlines()
for line in lines_east:
line = re.sub("\n","",line)
team_east.append(line.strip())
with open("西部球队队名.txt",'r',encoding='utf-8') as f:
lines_west = f.readlines()
for line in lines_west:
line = re.sub("\n","",line)
team_west.append(line.strip())
count = 0
for i in range(0,len(data['冠军'])):
if data['比赛年份'][i]>=1970 and data['冠军'][i] in team_east:
data.loc[i,'分区'] = 'E'
elif data['比赛年份'][i]>=1970 and data['冠军'][i] in team_west:
data.loc[i,'分区'] = 'W'
else:
data.loc[i, '分区'] = 'F'
result_ending = []
for i in range(0,len(data['分区'])):
res = ""
res = "{},{},{},{},{},{},{}".format(data['比赛年份'][i], data['具体日期'][i], data['冠军'][i], data['比分'][i], data['亚军'][i],data['MVP'][i],data['分区'][i])
result_ending.append(res)
multi_line_string = '\n'.join(result_ending)
with open('output.txt', 'w', encoding='utf-8') as file:
file.write(multi_line_string)注:代码以及源文件请到资源中查找(免费下载地址 https://download.csdn.net/download/ppqq980532/90113775?spm=1001.2014.3001.5501)
最终处理结果output.txt部分内容如下图所示:

(四)统计各个球队获得冠军的数量
要统计各球队获得冠军的数量,基本思路是在map阶段解析出冠军球队的名称作为键,以一个值为1的IntWritable对象作为值,然后传递给reduce,在reduce部分做相加操作即可。
另外统计结果需要根据东西区来分文件存储,通过已给出并清洗后的数据集可知,应该分为东区、西区和未分区三个文件存储,因此需要自定义Partitoner,并根据分区标识来判断每行数据需要进入哪个分区。
指定reduce的个数,通过job.setNumReduceTasks(3)来设置reduce的数量为3个。核心代码解析如下:
1、map部分主要用于解析冠军球队名称,以及解析出分区标识,并根据分区标识来设置键值,而值部分则直接取值为1,核心代码如下图所示。

2、在自定义的Partitioner中,需要根据键的取值,来判断每行数据进入哪一个分区,核心代码如下图所示。
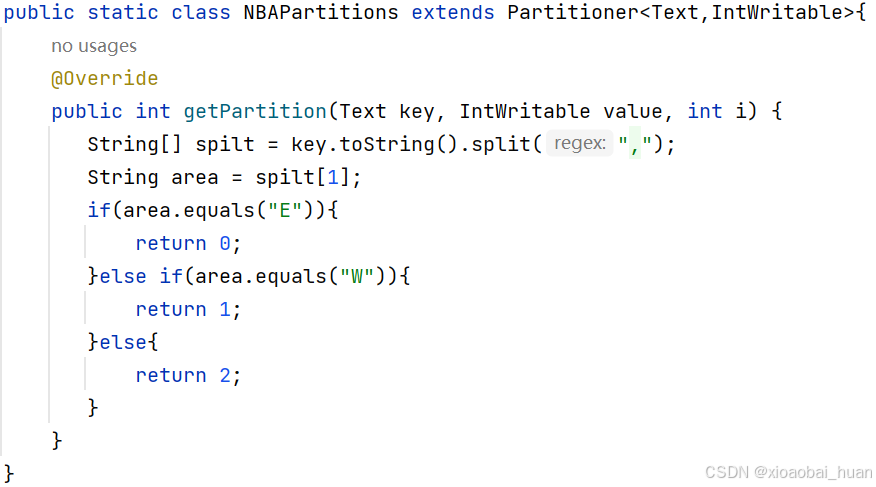
3、reduce部分进行合并,统计每只球队获得冠军的数量,核心代码如下图所示。
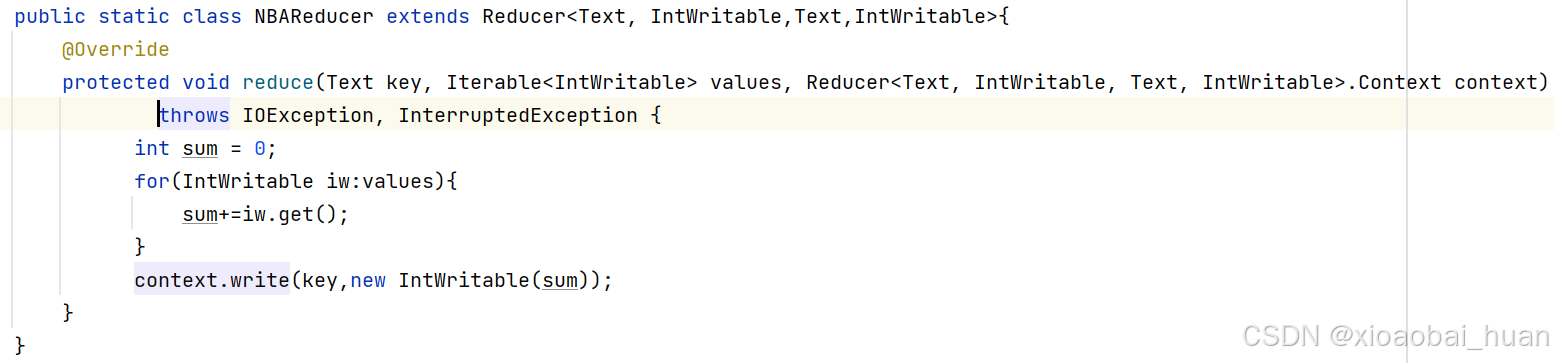
main方法中,除了基本的job提交所需的参数外,另外还需要指定自定义分区类,并且还设置了reduce的数量为3,核心代码如下图所示:
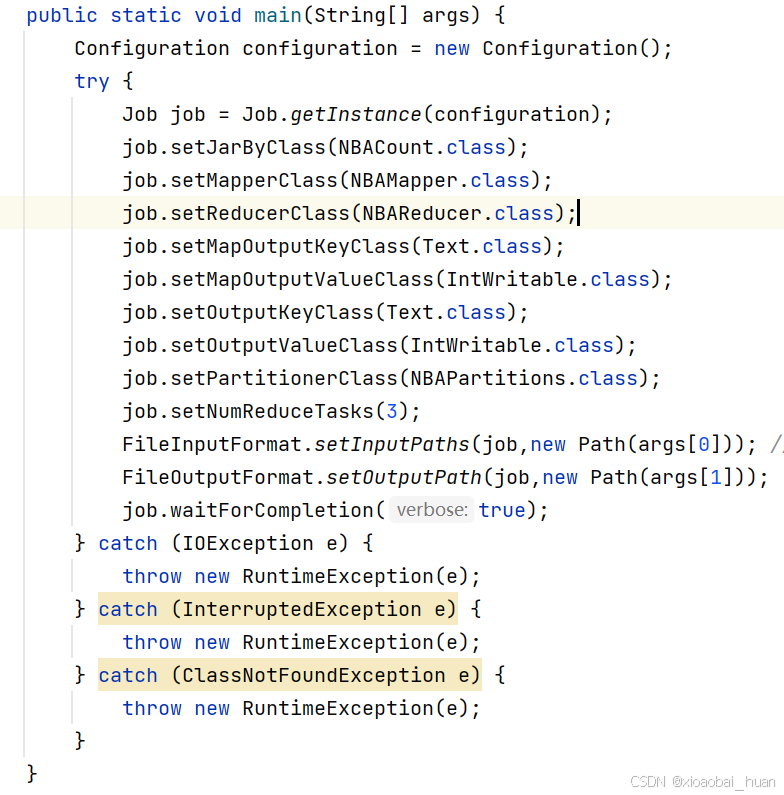
附完整代码:
package com.nba.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class NBACount {
public static class NBAMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
Text newKey = new Text();
IntWritable newValue = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String[] spilt = value.toString().split(",");
String winner = spilt[2];
String part = spilt[6];
newKey.set(winner+","+part);
context.write(newKey,newValue);
}
}
public static class NBAPartitions extends Partitioner<Text,IntWritable>{
@Override
public int getPartition(Text key, IntWritable value, int i) {
String[] spilt = key.toString().split(",");
String area = spilt[1];
if(area.equals("E")){
return 0;
}else if(area.equals("W")){
return 1;
}else{
return 2;
}
}
}
public static class NBAReducer extends Reducer<Text, IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable iw:values){
sum+=iw.get();
}
context.write(key,new IntWritable(sum));
}
}
public static void main(String[] args) {
Configuration configuration = new Configuration();
try {
Job job = Job.getInstance(configuration);
job.setJarByClass(NBACount.class);
job.setMapperClass(NBAMapper.class);
job.setReducerClass(NBAReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setPartitionerClass(NBAPartitions.class);
job.setNumReduceTasks(3);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
} catch (IOException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}
具体项目源码请到资源中查找
三、结果展示
本综合训练的结果展示在有三台主机的hadoop集群上进行并行计算,将输出的output.txt结果文档上传到HDFS文件系统中,在linux系统输入命令:
hadoop jar jar包 驱动类 参数1(hdfs中文件处理的路径) 参数2(结果输出的目录)
最终的计算结果有三个文件(除_SUCCESS文件),文件列表如下图所示:
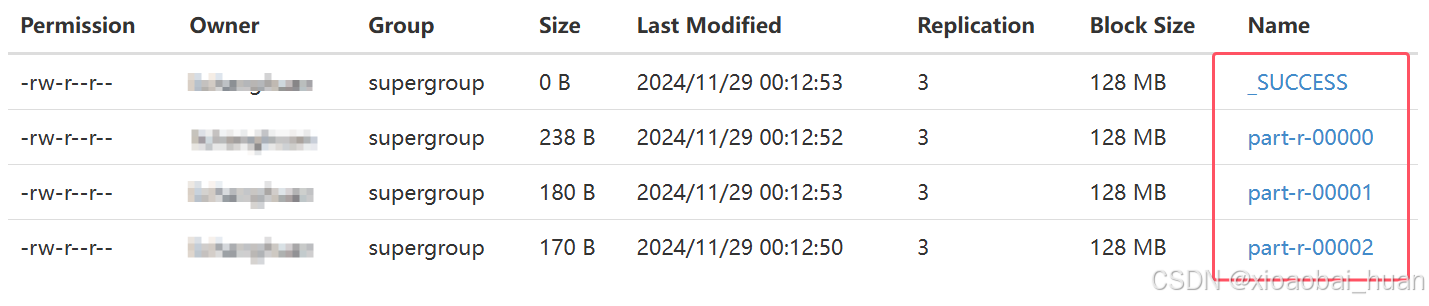
三个文件的内容如下所示:
(1)part-r-00000内容如图所示

(2)part-r-00001内容如图所示

(3)part-r-00002内容如图4所示




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









