







大数据技术之Flink
- 问题
- 6. Flink中的时间和窗口
- 7. 处理函数
- 8. 多流转换
- 9. 状态编程
【尚硅谷】2022版Flink1.13实战教程(涵盖所有flink-Java知识点)
问题
所有的processFunction都是抽象类
1. Flink中迟到数据如何解决?
- 可以设置watermark的延迟时间,(未计算)
- 可以让窗口多待一会,允许延迟,allowed Lateness(已经开始计算,但是有延迟。 迟到数据来了,会触发窗口计算,更新之前的计算结果)
- 可以将迟到的数据放在侧输出流里,将迟到的数据进行计算,更新对应的窗口的计算结果
2. 测试水位线中,为什么第一条数据的水位线时最小值
先处理数据,200毫秒生成水位线,再进数据的时候,上回生成的数据才被处理(也就是打印)
水位线的生成时周期性的,默认200ms,当第一条数据来的时候,水位线还没有被处理,就输出了水位线。
6. Flink中的时间和窗口
在流数据处理应用中,一个很重要、也很常见的操作就是窗口计算。所谓的“窗口”,一般就是划定的一段时间范围,也就是“时间窗”;对在这范围内的数据进行处理,就是所谓的窗口计算。所以窗口和时间往往是分不开的。接下来我们就深入了解一下 Flink 中的时间语义和窗口的应用。
Keyed State方便打乱重分区,有键组的概念
6.1 时间语义
6.1.1 Flink中的时间语义
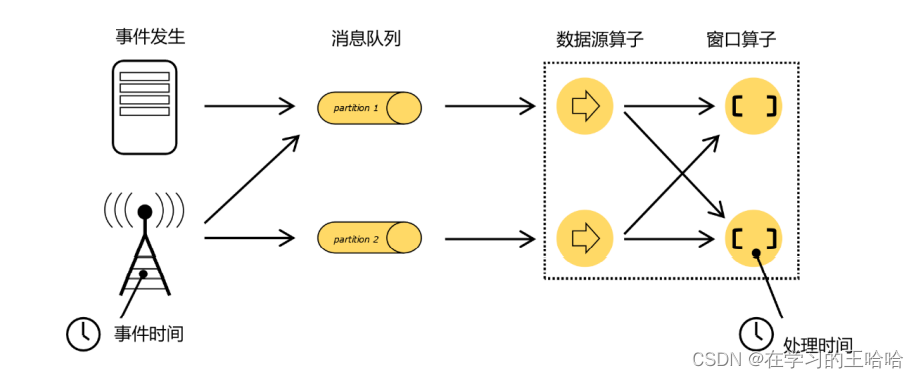
事件时间(Event Time):数据产生的时间
处理时间(Processing Time):数据真正被处理的时间
6.1.2 哪种时间语义更重要?
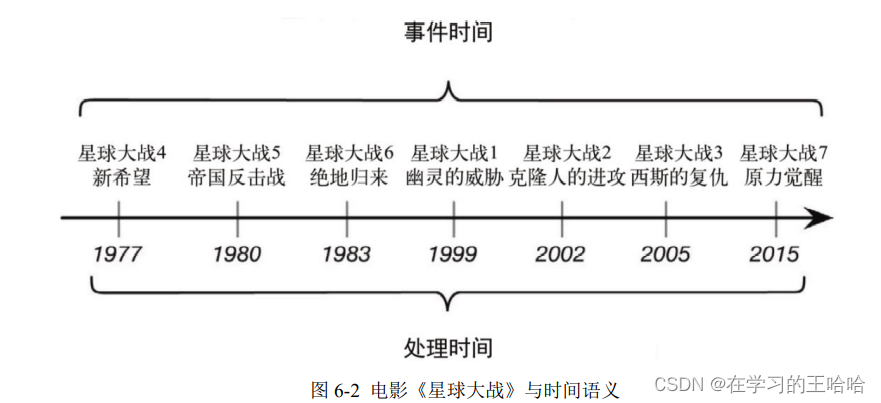
事件时间更重要
6.2 水位线(WaterMark)
6.2.1 事件时间和窗口
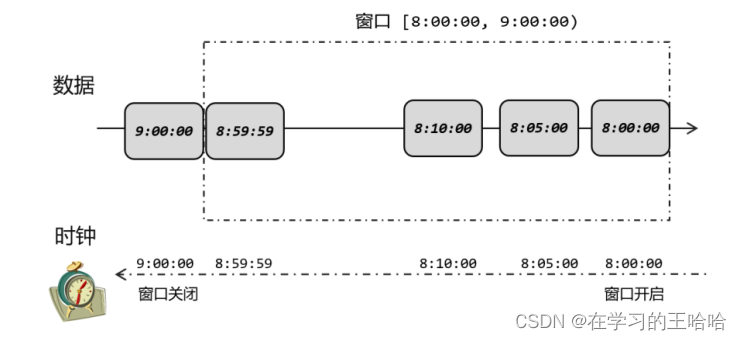
6.2.2 什么是水位线?
用来衡量时间时间(Event time)进展的标记,就被称作”水位线“(Watermark)
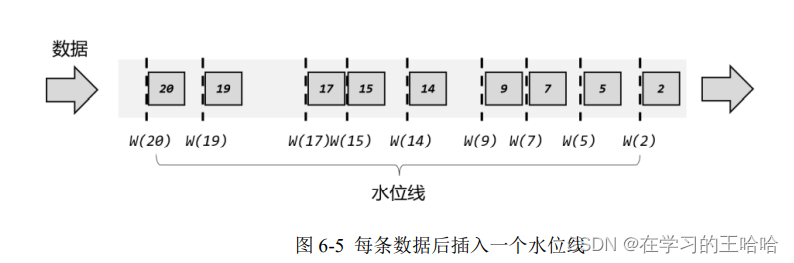
有序流中的水位线
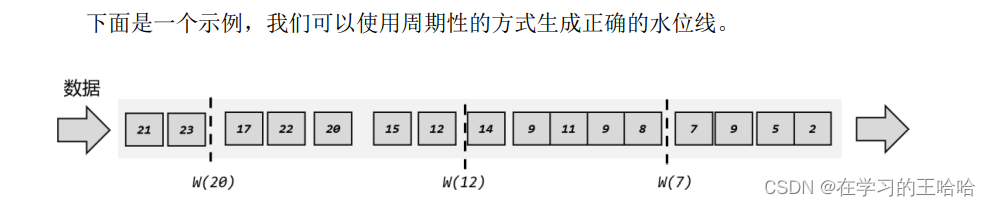
大量数据到来的话,可以周期性的进行时间标记。
周期性更新水位线
实际应用中,如果当前数据量非常大,可能会有很多数据的时间戳是相同的,这时每来一条数据就提取时间戳、插入水位线就做了大量的无用功。而且即使时间戳不同,同时涌来的数据时间差会非常小(比如几毫秒),往往对处理计算也没什么影响。所以为了提高效率,一般会每隔一段时间生成一个水位线,这个水位线的时间戳,就是当前最新数据的时间戳,如图6-6 所示。所以这时的水位线,其实就是有序流中的一个周期性出现的时间标记。
无序流中的水位线
在分布式系统中,数据在节点间传输,会因为网络传输延迟的不确定性,导致顺序发生改变,这就是所谓的“乱序数据”。
我们插入新的水位线时,要先判断一下时间戳是否比之前的大,否则就不再生成新的水位线,如图 6-8 所示。也就是说,只有数据的时间戳比当前时钟大,才能推动时钟前进,这时才插入水位线。

如何处理迟到的数据?
水位线的特性
- 水位线是插入到数据流中的一个标记,可以认为是一个特殊的数据
- 水位线主要的内容是一个时间戳,用来表示当前事件时间的进展
- 水位线是基于数据的时间戳生成的
- 水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进
- 水位线可以通过设置延迟,来保证正确处理乱序数据
- 一个水位线Watermark(t),表示在当前流中事件时间已经达到了时间戳t,这代表t之前的所有数据都到齐了,之后流中不会出现时间戳t‘<=t的数据
6.2.3 如何生成水位线?
总结历史数据的乱序程度,
水位线生成策略(Watermark Strategies)
在 Flink 的 DataStream API 中 , 有 一 个 单 独 用 于 生 成 水 位 线 的 方法:.assignTimestampsAndWatermarks(),它主要用来为流中的数据分配时间戳,并生成水位线来指示事件时间:
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(
WatermarkStrategy<T> watermarkStrategy)
具体使用时,直接用 DataStream 调用该方法即可,与普通的 transform 方法完全一样。
DataStream<Event> stream = env.addSource(new ClickSource());
DataStream<Event> withTimestampsAndWatermarks =
stream.assignTimestampsAndWatermarks(<watermark strategy>);
.assignTimestampsAndWatermarks()方法需要传入一个 WatermarkStrategy 作为参数,这就是 所 谓 的 “ 水 位 线 生 成 策 略 ” 。 WatermarkStrategy 中 包 含 了 一 个 “ 时 间 戳 分 配器”TimestampAssigner 和一个“水位线生成器”WatermarkGenerator。
public interface WatermarkStrategy<T>
extends TimestampAssignerSupplier<T>,
WatermarkGeneratorSupplier<T>{
@Override
TimestampAssigner<T>
createTimestampAssigner(TimestampAssignerSupplier.Context context);
@Override
WatermarkGenerator<T>
createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}
-
TimestampAssigner:主要负责从流中数据元素的某个字段中提取时间戳,并分配给元素。时间戳的分配是生成水位线的基础。
-
WatermarkGenerator:主要负责按照既定的方式,基于时间戳生成水位线。在WatermarkGenerator 接口中,主要又有两个方法:onEvent()和 onPeriodicEmit()。
-
onEvent:每个事件(数据)到来都会调用的方法,它的参数有当前事件、时间戳,以及允许发出水位线的一个 WatermarkOutput,可以基于事件做各种操作
-
onPeriodicEmit:周期性调用的方法,可以由 WatermarkOutput 发出水位线。周期时间为处理时间,可以调用环境配的.setAutoWatermarkInterval()方法来设置,默认为200ms。
env.getConfig().setAutoWatermarkInterval(60 * 1000L);
Flink 内置水位线生成器
package com.atguigu.chapter06;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
public class WatermarkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);
DataStream<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("BOb", "./cart", 2000L),
new Event("BOb", "./prod?id=100", 3000L),
new Event("BOb", "./prod?id=18", 3900L),
new Event("BOb", "./prod?id=140", 4000L),
new Event("Alice", "./prod?id=140", 5000L),
new Event("Alice", "./prod?id=240", 20000L),
new Event("Alice", "./prod?id=040", 5000L))
// 有序流的watermark生成
// .assignTimestampsAndWatermarks( WatermarkStrategy.<Event>forMonotonousTimestamps()
// .withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
// @Override
// public long extractTimestamp(Event event, long l) {
// return event.timestamp;
// }
// })
// )
// 乱序流的watermark生成
.assignTimestampsAndWatermarks( WatermarkStrategy.<Event>forBoundedOutOfOrderness( Duration.ofSeconds(2) )
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
}
}
6.2.4 水位线的传递
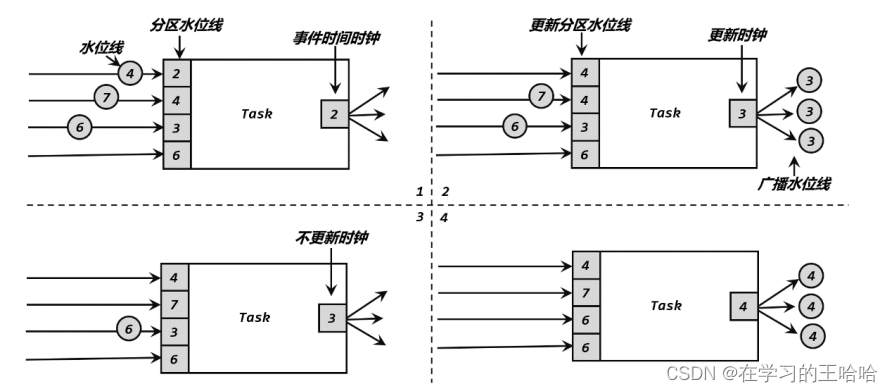
在流处理中,上游任务处理完水位线、时钟改变之后,要把当前的水位线再次发出,广播给所有的下游子任务。
而当一个任务接收到多个上游并行任务传递来的水位线,应该以最小的哪个作为当前任务的事件时钟。
6.3 窗口(Window)
6.3.1 窗口的概念
在Flink中,窗口就是用来处理无界流的核心。
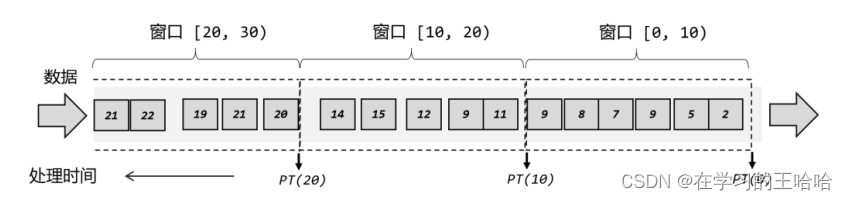
按照本身的时间戳判断数据属于哪个窗口?
在 Flink 中,窗口其实并不是一个“框”,流进来的数据被框住了就只能进这一个窗口。相比之下,我们应该把窗口理解成一个“桶”,如图所示。在 Flink 中,窗口可以把流切割成有限大小的多个“存储桶”(bucket);每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
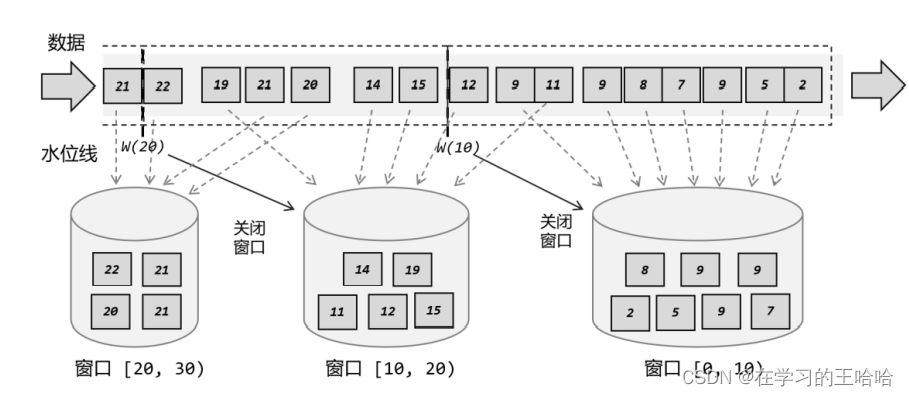
窗口同时有多个。窗口不是动态准备好的,而是动态创建的。
6.3.2 窗口的分类
1. 按照驱动类型分类
按照时间段去截取数据,这种窗口就叫作“时间窗口”(Time Window)。
按照固定的个数,来截取一段数据集,这种窗口叫作“计数窗口”(Count Window)
2. 按照窗口分配数据的规则分类
(1)滚动窗口(Tumbling Windows)
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。如果我们把多个窗口的创建,看作一个窗口的运动,那就好像它在不停地向前“翻滚”一样。这是最简单的窗口形式,我们之前所举的例子都是滚动窗口。也正是因为滚动窗口是“无缝衔接”,所以每个数据都会被分配到一个窗口,而且只会属于一个窗口。
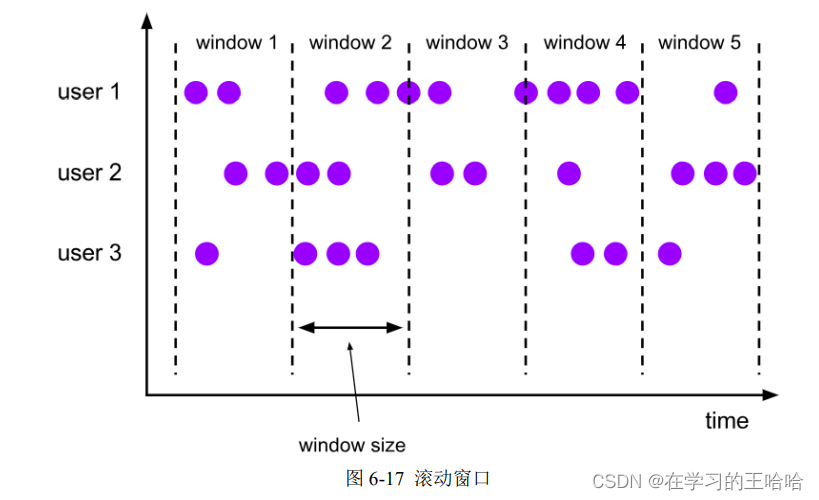
(2)滑动窗口(Sliding Windows)
与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。如果看作一个窗口的运动,那么就像是向前小步“滑动”一样。
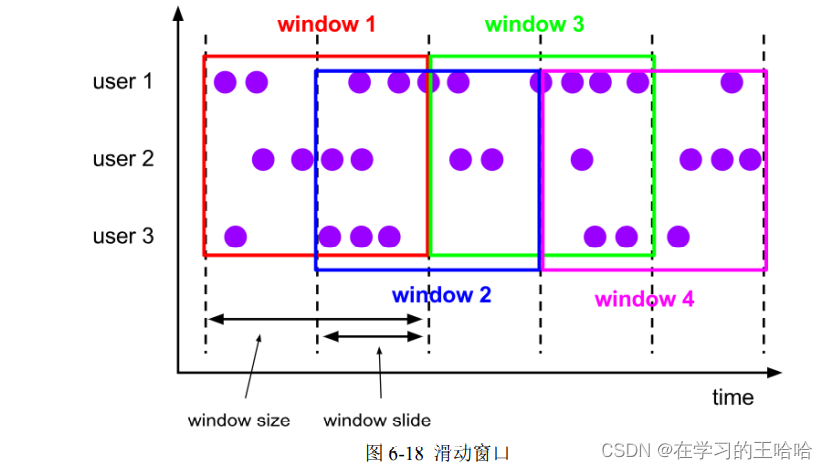
所以,滑动窗口其实是固定大小窗口的更广义的一种形式;换句话说,滚动窗口也可以看作是一种特殊的滑动窗口——窗口大小等于滑动步长(size = slide)。
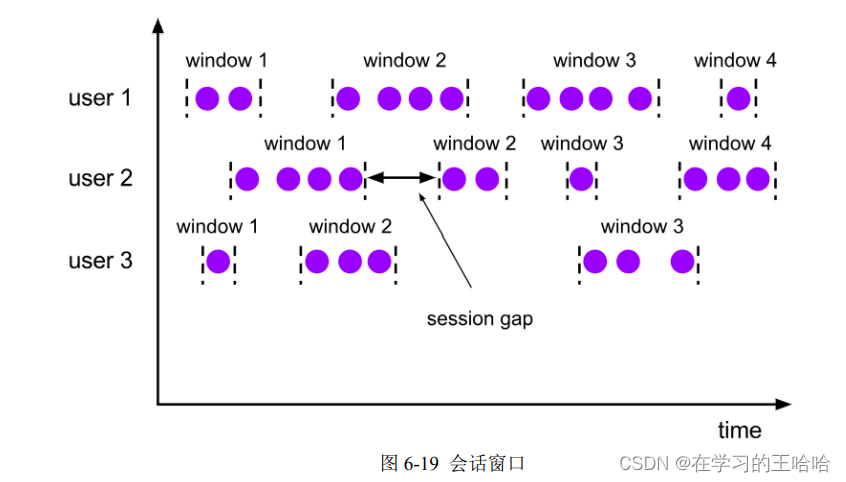
(3)会话窗口(Session Windows)
会话窗口顾名思义,是基于“会话”(session)来来对数据进行分组的。
最重要的参数就是这段时间的长度(size),它表示会话的超时时间,也就是两个会话窗口之间的最小距离。如果相邻两个数据到来的时间间隔(Gap)小于指定的大小(size),那说明还在保持会话,它们就属于同一个窗口;如果 gap 大于 size,那么新来的数据就应该属于新的会话窗口,而前一个窗口就应该关闭了。
(4)全局窗口(Global Windows)
这种窗口全局有效,会把相同 key 的所有数据都分配到同一个窗口中;
无界流的数据永无止尽,所以这种窗口也没有结束的时候,默认是不会做触发计算的。如果希望它能对数据进行计算处理,还需要自定义“触发器”(Trigger)。

6.3.3 窗口 API 概览
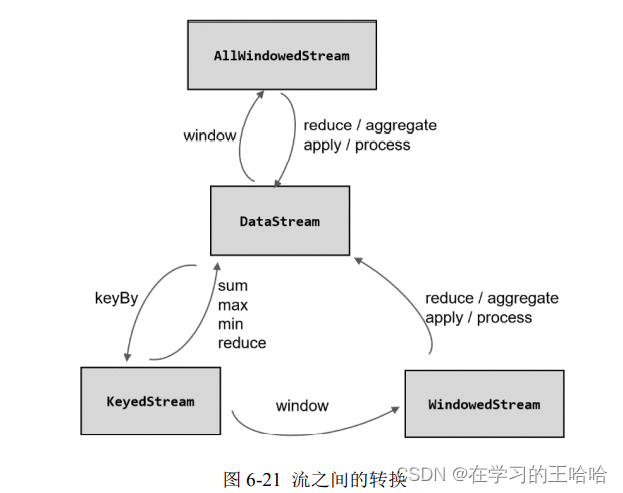
1. 按键分区(Keyed)和非按键分区(Non-Keyed)
(1)按键分区窗口(Keyed Windows)
经过按键分区 keyBy 操作后,数据流会按照 key 被分为多条逻辑流(logical streams),这就是 KeyedStream。基于 KeyedStream 进行窗口操作时, 窗口计算会在多个并行子任务上同时执行。相同 key 的数据会被发送到同一个并行子任务,而窗口操作会基每个 key 进行单独的处理。所以可以认为,每个 key 上都定义了一组窗口,各自独立地进行统计计算。
在代码实现上,我们需要先对 DataStream 调用.keyBy()进行按键分区,然后再调用.window()定义窗口。
stream.keyBy(...)
.window(...)
(2)非按键分区(Non-Keyed Windows)
如果没有进行 keyBy,那么原始的 DataStream 就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了 1。所以在实际应用中一般不推荐使用这种方式。
在代码中,直接基于 DataStream 调用.windowAll()定义窗口。
stream.windowAll(...)
这里需要注意的是,对于非按键分区的窗口操作,手动调大窗口算子的并行度也是无效的,windowAll 本身就是一个非并行的操作。
2. 代码中窗口 API 的调用
有了前置的基础,接下来我们就可以真正在代码中实现一个窗口操作了。简单来说,窗口操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)。
stream.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(<window function>)
其中.window()方法需要传入一个窗口分配器,它指明了窗口的类型;而后面的.aggregate()方法传入一个窗口函数作为参数,它用来定义窗口具体的处理逻辑。窗口分配器有各种形式,而窗口函数的调用方法也不只.aggregate()一种,我们接下来就详细展开讲解。
另外,在实际应用中,一般都需要并行执行任务,非按键分区很少用到,所以我们之后都以按键分区窗口为例;如果想要实现非按键分区窗口,只要前面不做 keyBy,后面调用.window()时直接换成.windowAll()就可以了。
6.3.4 窗口分配器(Window Assigners)
定义窗口分配器(Window Assigners)是构建窗口算子的第一步,它的作用就是定义数据应该被“分配”到哪个窗口。窗口分配器其实就是在指定窗口的类型。
窗口分配器最通用的定义方式,就是调用.window()方法。这个方法需要传入一个WindowAssigner 作为参数,返回 WindowedStream。如果是非按键分区窗口,那么直接调用.windowAll()方法,同样传入一个WindowAssigner,返回的是 AllWindowedStream。
stream.keyBy(data -> data.user)
// .countWindow(10,2) // 滑动技术窗口
// .window(EventTimeSessionWindows.withGap(Time.seconds(2))) // 事件时间会话窗口
// .window(SlidingEventTimeWindows.of(Time.hours(1),Time.minutes(5))) // 滑动事件事件窗口
.window(TumblingEventTimeWindows.of(Time.hours(1))) // 滚动事件事件窗口
6.3.5 窗口函数(Window Functions)
定义了窗口分配器,我们只是知道了数据属于哪个窗口,可以将数据收集起来了;至于收集起来到底要做什么,其实还完全没有头绪。所以在窗口分配器之后,必须再接上一个定义窗口如何进行计算的操作,这就是所谓的“窗口函数”(window functions)。
窗口函数定义了要对窗口中收集的数据做的计算操作,根据处理的方式可以分为两类:增量聚合函数和全窗口函数。
1. 增量聚合函数(incremental aggregation functions)
窗口将数据收集起来,最基本的处理操作当然就是进行聚合。我们可以每来一个数据就在之前结果上聚合一次,这就是“增量聚合”
典型的增量聚合函数有两个:ReduceFunction 和 AggregateFunction。
(1)归约函数(ReduceFunction)
package com.atguigu.chapter06;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
public class WindowTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);
// DataStream<Event> stream = env.fromElements(
// new Event("Mary", "./home", 1000L),
// new Event("BOb", "./cart", 2000L),
// new Event("BOb", "./prod?id=100", 3000L),
// new Event("BOb", "./prod?id=18", 3900L),
// new Event("BOb", "./prod?id=140", 4000L),
// new Event("Alice", "./prod?id=140", 5000L),
// new Event("Alice", "./prod?id=240", 20000L),
// new Event("Alice", "./prod?id=040", 5000L))
SingleOutputStreamOperator<Event> stream= env.addSource(new ClickSource())
// 乱序流的watermark生成
.assignTimestampsAndWatermarks( WatermarkStrategy.<Event>forBoundedOutOfOrderness( Duration.ZERO )
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream.map(new MapFunction<Event, Tuple2< String, Long>>() {
@Override
public Tuple2< String, Long> map(Event event) throws Exception {
return Tuple2.of(event.user,1L);
}
})
.keyBy(data -> data.f0)
// .countWindow(10,2) // 滑动技术窗口
// .window(EventTimeSessionWindows.withGap(Time.seconds(2))) // 事件时间会话窗口
// .window(SlidingEventTimeWindows.of(Time.hours(1),Time.minutes(5))) // 滑动事件事件窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10))) // 滚动事件事件窗口
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return Tuple2.of(value1.f0,value1.f1 + value2.f1);
}
})
.print();
env.execute();
}
}
缺陷:规约后,只能得到同样数据类型的结果。
(2)聚合函数(AggregateFunction)
ReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。这就迫使我们必须在聚合前,先将数据转换(map)成预期结果类型;而在有些情况下,还需要对状态进行进一步处理才能得到输出结果,这时它们的类型可能不同,使用 ReduceFunction 就会非常麻烦。
AggregateFunction 可以看作是 ReduceFunction 的通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。输入类型 IN 就是输入流中元素的数据类型;累加器类型 ACC 则是我们进行聚合的中间状态类型;而输出类型当然就是最终计算结果的类型了。
接口中有四个方法:
- createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
- add():将输入的元素添加到累加器中。这就是基于聚合状态,对新来的数据进行进一步聚合的过程。方法传入两个参数:当前新到的数据 value,和当前的累加器accumulator;返回一个新的累加器值,也就是对聚合状态进行更新。每条数据到来之后都会调用这个方法。
- getResult():从累加器中提取聚合的输出结果。也就是说,我们可以定义多个状态,然后再基于这些聚合的状态计算出一个结果进行输出。比如之前我们提到的计算平均值,就可以把 sum 和 count 作为状态放入累加器,而在调用这个方法时相除得到最终结果。这个方法只在窗口要输出结果时调用。
- merge():合并两个累加器,并将合并后的状态作为一个累加器返回。这个方法只在需要合并窗口的场景下才会被调用;最常见的合并窗口(Merging Window)的场景就是会话窗口(Session Windows)。
package com.atguigu.chapter06;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.sql.Timestamp;
import java.time.Duration;
public class WindowAggregateTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
// 乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream.keyBy(data -> data.user)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new AggregateFunction<Event, Tuple2<Long,Integer>, String>() {
@Override
public Tuple2<Long,Integer> createAccumulator() {
return Tuple2.of(0L,0);
}
@Override
public Tuple2<Long, Integer> add(Event event, Tuple2<Long, Integer> longIntegerTuple2) {
return Tuple2.of(longIntegerTuple2.f0+event.timestamp,longIntegerTuple2.f1 + 1);
}
@Override
public String getResult(Tuple2<Long, Integer> longIntegerTuple2) {
Timestamp timestamp = new Timestamp(longIntegerTuple2.f0 / longIntegerTuple2.f1);
return timestamp.toString();
}
@Override
public Tuple2<Long, Integer> merge(Tuple2<Long, Integer> longIntegerTuple2, Tuple2<Long, Integer> acc1) {
return Tuple2.of(longIntegerTuple2.f0+acc1.f0, longIntegerTuple2.f1+acc1.f1);
}
})
.print();
env.execute();
}
}
2. 全窗口函数(full window functions)
与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
在 Flink 中,全窗口函数也有两种:WindowFunction 和 ProcessWindowFunction。
(1)窗口函数(WindowFunction)
WindowFunction 字面上就是“窗口函数”,它其实是老版本的通用窗口函数接口。我们可以基于 WindowedStream 调用.apply()方法,传入一个 WindowFunction 的实现类。
stream
.keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction());
(2)处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction 是 Window API 中最底层的通用窗口函数接口。之所以说它“最底层”,是因为除了可以拿到窗口中的所有数据之外,ProcessWindowFunction 还可以获取到一个“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(event time watermark)。这就使得 ProcessWindowFunction 更加灵活、功能更加丰富。
package com.atguigu.chapter06;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.HashSet;
public class WindowProcessTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
// 乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream.print("data");
// 使用ProcessWindowFunction计算UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new UvCountByWindow())
.print();
env.execute();
}
// 实现自定义的ProcessWIndowFunction ,输出一条统计信息
public static class UvCountByWindow extends ProcessWindowFunction<Event, String, Boolean, TimeWindow>{
@Override
public void process(Boolean aBoolean,
ProcessWindowFunction<Event, String, Boolean, TimeWindow>.Context context,
Iterable<Event> elements,
Collector<String> collector) throws Exception {
// 用一个HashSet保存User
HashSet<String> userset = new HashSet<>();
// 从elements中遍历数据,放在set中去重
for (Event element : elements) {
userset.add(element.user);
}
Integer uv = userset.size();
// 结合窗口信息
Long start = context.window().getStart();
Long end = context.window().getEnd();
collector.collect("窗口: " + new Timestamp(start) + " ~ " + new Timestamp(end)
+ " UV值为: " + uv);
}
}
}
3. 增量聚合和全窗口函数的结合使用
package com.atguigu.chapter06;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.HashSet;
public class UvCountExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
// 乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream.print("data");
// 使用AggregateFunction 和 ProcessWindowFunction结合计算UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new UvAgg(), new UvCountResult())
.print();
env.execute();
}
// 自定义实现AggregateFunction,增量聚合计算NV值
public static class UvAgg implements AggregateFunction<Event, HashSet<String>, Long>{
@Override
public HashSet<String> createAccumulator() {
return new HashSet<>();
}
@Override
public HashSet<String> add(Event event, HashSet<String> strings) {
strings.add(event.user);
// 不返回状态相当于没累加
return strings;
}
@Override
public Long getResult(HashSet<String> strings) {
return (long)strings.size();
}
@Override
public HashSet<String> merge(HashSet<String> strings, HashSet<String> acc1) {
return null;
}
}
// 实现自定义的ProcessWIndowFunction ,包装窗口信息
public static class UvCountResult extends ProcessWindowFunction<Long, String, Boolean, TimeWindow> {
@Override
public void process(Boolean aBoolean, ProcessWindowFunction<Long, String, Boolean, TimeWindow>.Context context, Iterable<Long> elements, Collector<String> collector) throws Exception {
Long uv = elements.iterator().next();
Long start = context.window().getStart();
Long end = context.window().getEnd();
collector.collect("窗口: " + new Timestamp(start) + " ~ " + new Timestamp(end)
+ " UV值为: " + uv);
}
}
}
4. 窗口函数综合应用实例
把每个url页面的访问量按照窗口划分
定义pojo对象
package com.atguigu.chapter06;
import java.sql.Timestamp;
public class UrlViewCount {
public String url;
public Long count;
public Long windowStart;
public Long windowEnd;
// 必须要有空参的构造方法
public UrlViewCount() {
}
public UrlViewCount(String url, Long count, Long windowStart, Long windowEnd) {
this.url = url;
this.count = count;
this.windowStart = windowStart;
this.windowEnd = windowEnd;
}
@Override
public String toString() {
return "UrlViewCount{" +
"url='" + url + '\'' +
", count=" + count +
", windowStart=" + new Timestamp(windowStart) +
", windowEnd=" + new Timestamp(windowEnd) +
'}';
}
}
写逻辑函数
package com.atguigu.chapter06;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
public class UrlCountViewExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
// 乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream.print("data");
// 统计每个url的访问量
stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult())
.print();
env.execute();
}
// 增量聚合,来一条数据就加1
public static class UrlViewCountAgg implements AggregateFunction<Event, Long, Long>{
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event event, Long aLong) {
return aLong + 1;
}
@Override
public Long getResult(Long aLong) {
return aLong;
}
@Override
public Long merge(Long aLong, Long acc1) {
return null;
}
}
// 包装窗口信息, 输出UrlViewCount
public static class UrlViewCountResult extends ProcessWindowFunction<Long, UrlViewCount, String, TimeWindow>{
@Override
public void process(String url, ProcessWindowFunction<Long, UrlViewCount, String, TimeWindow>.Context context, Iterable<Long> iterable, Collector<UrlViewCount> collector) throws Exception {
Long start = context.window().getStart();
Long end = context.window().getEnd();
Long count = iterable.iterator().next();
collector.collect(new UrlViewCount(url, count, start, end));
}
}
}
6.3.7 其他 API
1. 触发器(Trigger)
触发器主要是用来控制窗口什么时候触发计算。所谓的“触发计算”,本质上就是执行窗口函数,所以可以认为是计算得到结果并输出的过程。
基于 WindowedStream 调用.trigger()方法,就可以传入一个自定义的窗口触发器(Trigger)。
stream.keyBy(...)
.window(...)
.trigger(new MyTrigger())
Trigger 是一个抽象类,自定义时必须实现下面四个抽象方法:
- onElement():窗口中每到来一个元素,都会调用这个方法。
- onEventTime():当注册的事件时间定时器触发时,将调用这个方法。
- onProcessingTime ():当注册的处理时间定时器触发时,将调用这个方法。
- clear():当窗口关闭销毁时,调用这个方法。一般用来清除自定义的状态
2. 移除器(Evictor)
移除器主要用来定义移除某些数据的逻辑。基于 WindowedStream 调用.evictor()方法,就可以传入一个自定义的移除器(Evictor)。Evictor 是一个接口,不同的窗口类型都有各自预实现的移除器。
stream.keyBy(...)
.window(...)
.evictor(new MyEvictor())
Evictor 接口定义了两个方法:
- evictBefore():定义执行窗口函数之前的移除数据操作
- evictAfter():定义执行窗口函数之后的以处数据操作
默认情况下,预实现的移除器都是在执行窗口函数(window fucntions)之前移除数据的。
3. 允许延迟(Allowed Lateness)
我们可以设定允许延迟一段时间,在这段时间内,窗口不会销毁,继续到来的数据依然可以进入窗口中并触发计算。直到水位线推进到了 窗口结束时间 + 延迟时间,才真正将窗口的内容清空,正式关闭窗口。
基于 WindowedStream 调用.allowedLateness()方法,传入一个 Time 类型的延迟时间,就可以表示允许这段时间内的延迟数据。
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.allowedLateness(Time.minutes(1))
4. 将迟到的数据放入侧输出流
基于 WindowedStream 调用.sideOutputLateData() 方法,就可以实现这个功能。方法需要传入一个“输出标签”(OutputTag),用来标记分支的迟到数据流。因为保存的就是流中的原始数据,所以 OutputTag 的类型与流中数据类型相同。
DataStream<Event> stream = env.addSource(...);
OutputTag<Event> outputTag = new OutputTag<Event>("late") {};
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
将迟到数据放入侧输出流之后,还应该可以将它提取出来。基于窗口处理完成之后的DataStream,调用.getSideOutput()方法,传入对应的输出标签,就可以获取到迟到数据所在的流了。
SingleOutputStreamOperator<AggResult> winAggStream = stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
.aggregate(new MyAggregateFunction())
DataStream<Event> lateStream = winAggStream.getSideOutput(outputTag);
这里注意,getSideOutput()是 SingleOutputStreamOperator 的方法,获取到的侧输出流数据类型应该和 OutputTag 指定的类型一致,与窗口聚合之后流中的数据类型可以不同。
5. 处理迟到数据实操
package com.atguigu.chapter06;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
public class LateDataTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);
// SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
// // 乱序流的watermark生成
SingleOutputStreamOperator<Event> stream = env.socketTextStream("hadoop102",7777)
.map(new MapFunction<String, Event>() {
@Override
public Event map(String s) throws Exception {
String[] fields = s.split(",");
return new Event(fields[0].trim(),fields[1].trim(),Long.valueOf(fields[2].trim()) );
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream.print("data");
// 定义一个输出标签
// 会涉及到泛型擦除
OutputTag<Event> late = new OutputTag<Event>("late"){};
// 统计每个url的访问量
SingleOutputStreamOperator<UrlViewCount> result = stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.allowedLateness(Time.minutes(1))
.sideOutputLateData(late)
.aggregate(new UrlCountViewExample.UrlViewCountAgg(), new UrlCountViewExample.UrlViewCountResult());
result.print("result");
result.getSideOutput(late).print("late");
env.execute();
}
}
[wanghaha@hadoop102 kafka]$ nc -lk 7777
Mary, ./home, 1000
Mary, ./home, 1000
Mary, ./home, 1000
Mary, ./home, 1000
Mary, ./home, 1000
7. 处理函数
在更底层,我们可以不定义任何具体的算子(比如 map,filter,或者 window),而只是提炼出一个统一的“处理”(process)操作——它是所有转换算子的一个概括性的表达,可以自定义处理逻辑,所以这一层接口就被叫作“处理函数”(process function)。
7.1 基本处理函数(ProcessFunciton)
7.1.1 处理函数的功能和使用
能够拿到别的api,拿不到的东西。
富函数能做的事情,处理函数都能做。还能够提供定时服务。还能直接将数据输出到测输出流
我们之前学习的转换算子,一般只是针对某种具体操作来定义的,能够拿到的信息比较有限。比如 map 算子,我们实现的 MapFunction 中,只能获取到当前的数据,定义它转换之后的形式;而像窗口聚合这样的复杂操作,AggregateFunction 中除数据外,还可以获取到当前的状态(以累加器 Accumulator 形式出现)。另外我们还介绍过富函数类,比如RichMapFunction,它提供了获取运行时上下文的方法 getRuntimeContext(),可以拿到状态,还有并行度、任务名
称之类的运行时信息。
但是无论那种算子,如果我们想要访问事件的时间戳,或者当前的水位线信息,都是完全做不到的。在定义生成规则之后,水位线会源源不断地产生,像数据一样在任务间流动,可我们却不能像数据一样去处理它;跟时间相关的操作,目前我们只会用窗口来处理。而在很多应用需求中,要求我们对时间有更精细的控制,需要能够获取水位线,甚至要“把控时间”、定义什么时候做什么事,这就不是基本的时间窗口能够实现的了。
处理函数提供了一个“定时服务”(TimerService),我们可以通过它访问流中的事件(event)、时间戳(timestamp)、水位线(watermark),甚至可以注册“定时事件”。而且处理函数继承了 AbstractRichFunction 抽象类,
所以拥有富函数类的所有特性,同样可以访问状态(state)和其他运行时信息。此外,处理函数还可以直接将数据输出到侧输出流(side output)中。所以,处理函数是最为灵活的处理方法,可以实现各种自定义的业务逻辑;同时也是整个 DataStream API 的底层基础。
处理函数的使用与基本的转换操作类似,只需要直接基于 DataStream 调用.process()方法就可以了。方法需要传入一个 ProcessFunction 作为参数,用来定义处理逻辑。
stream.process(new MyProcessFunction())
7.1.2 ProcessFunction 解析
在源码中我们可以看到,抽象类 ProcessFunction 继承了 AbstractRichFunction,有两个泛型类型参数:I 表示 Input,也就是输入的数据类型;O 表示 Output,也就是处理完成之后输出的数据类型。
内部单独定义了两个方法:一个是必须要实现的抽象方法.processElement();另一个是非抽象方法.onTimer()。
7.1.3 处理函数的分类
我们知道,DataStream 在调用一些转换方法之后,有可能生成新的流类型;例如调用.keyBy()之后得到 KeyedStream,进而再调用.window()之后得到 WindowedStream。对于不同类型的流,其实都可以直接用.process()方法进行自定义处理,这时传入的参数就都叫作处理函数。当然,它们尽管本质相同,都是可以访问状态和时间信息的底层 API,可彼此之间也会
有所差异。
Flink 提供了 8 个不同的处理函数:
(1)ProcessFunction
最基本的处理函数,基于 DataStream 直接调用.process()时作为参数传入。
(2)KeyedProcessFunction
对流按键分区后的处理函数,基于 KeyedStream 调用.process()时作为参数传入。要想使用定时器,比如基于 KeyedStream。
(3)ProcessWindowFunction
开窗之后的处理函数,也是全窗口函数的代表。基于 WindowedStream 调用.process()时作为参数传入。
(4)ProcessAllWindowFunction
同样是开窗之后的处理函数,基于 AllWindowedStream 调用.process()时作为参数传入。
(5)CoProcessFunction
合并(connect)两条流之后的处理函数,基于 ConnectedStreams 调用.process()时作为参数传入。关于流的连接合并操作,我们会在后续章节详细介绍。
(6)ProcessJoinFunction
间隔连接(interval join)两条流之后的处理函数,基于 IntervalJoined 调用.process()时作为参数传入。
(7)BroadcastProcessFunction
广播连接流处理函数,基于 BroadcastConnectedStream 调用.process()时作为参数传入。这里的“广播连接流”BroadcastConnectedStream,是一个未 keyBy 的普通 DataStream 与一个广播流(BroadcastStream)做连接(conncet)之后的产物。
(8)KeyedBroadcastProcessFunction
按键分区的广播连接流处理函数,同样是基于 BroadcastConnectedStream 调用.process()时作为参数传入。与 BroadcastProcessFunction 不同的是,这时的广播连接流,是一个 KeyedStream与广播流(BroadcastStream)做连接之后的产物。
package com.atguigu.chapter;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class ProcessFunctionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
stream.print();
stream.process(new ProcessFunction<Event, String>() {
@Override
public void processElement(Event event, ProcessFunction<Event, String>.Context context, Collector<String> collector) throws Exception {
if(event.user.equals("Mary")){
collector.collect(event.user + " clicks " + event.url);
}else if(event.user.equals("Bob")){
collector.collect(event.user);
collector.collect(event.user);
}
System.out.println("timestamp: " + context.timestamp());
System.out.println("watermark: " + context.timerService().currentWatermark());
System.out.println(getRuntimeContext().getIndexOfThisSubtask());
}
@Override
public void onTimer(long timestamp, ProcessFunction<Event, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
super.onTimer(timestamp, ctx, out);
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
}
}).print();
env.execute();
}
}
7.2 按键分区处理函数(KeyedProcessFunction)
只有在 KeyedStream 中才支持使用 TimerService 设置定时器的操作。所以一般情况下,我们都是先做了 keyBy 分区之后,再去定义处理操作;代码中更加常见的处理函数是 KeyedProcessFunction,最基本的 ProcessFunction 反而出镜率没那么高。
7.2.1 定时器(Timer)和定时服务(TimerService)
定时器(timers)是处理函数中进行时间相关操作的主要机制。在.onTimer()方法中可以实现定时处理的逻辑,而它能触发的前提,就是之前曾经注册过定时器、并且现在已经到了触发时间。注册定时器的功能,是通过上下文中提供的“定时服务”(TimerService)来实现的。
7.2.2 KeyedProcessFunction 的使用
KeyedProcessFunction 可以说是处理函数中的“嫡系部队”,可以认为是 ProcessFunction 的一个扩展。我们只要基于 keyBy 之后的 KeyedStream,直接调用.process()方法,这时需要传入的参数就是 KeyedProcessFunction 的实现类。
stream.keyBy( t -> t.f0 )
.process(new MyKeyedProcessFunction())
处理时间定时器
package com.atguigu.chapter;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
public class ProcessingTimeTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource());
stream.keyBy(data -> data.user)
.process(new KeyedProcessFunction<String, Event, String>() {
@Override
public void processElement(Event event, KeyedProcessFunction<String, Event, String>.Context context, Collector<String> collector) throws Exception {
long currTs = context.timerService().currentProcessingTime();
collector.collect(context.getCurrentKey() + "数据到达时间: " + new Timestamp(currTs));
// 注册一个10秒后的定时器
context.timerService().registerProcessingTimeTimer(currTs+ 10 * 1000L);
}
@Override
public void onTimer(long timestamp, KeyedProcessFunction<String, Event, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
out.collect(ctx.getCurrentKey() + "定时器触发,触发时间: " + new Timestamp(timestamp));
}
}).print();
env.execute();
}
}
事件事件定时器
package com.atguigu.chapter07;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
public class EventTimeTimer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
// 事件时间定时器
stream.keyBy(data -> data.user)
.process(new KeyedProcessFunction<String, Event, String>() {
@Override
public void processElement(Event event, KeyedProcessFunction<String, Event, String>.Context context, Collector<String> collector) throws Exception {
long currTs = context.timestamp();
collector.collect(context.getCurrentKey() + "数据到达,时间戳: " + new Timestamp(currTs) + " watermark: " + context.timerService().currentWatermark());
// 注册一个10秒后的定时器
context.timerService().registerEventTimeTimer(currTs+ 10 * 1000L);
}
@Override
public void onTimer(long timestamp, KeyedProcessFunction<String, Event, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
out.collect(ctx.getCurrentKey() + "定时器触发,触发时间: " + new Timestamp(timestamp));
}
}).print();
env.execute();
}
}
7.3 窗口处理函数
进行窗口计算,我们可以直接调用现成的简单聚合方法(sum/max/min),也可以通过调用.reduce()或.aggregate()来自定义一般的增量聚合函数(ReduceFunction/AggregateFucntion);
而对于更加复杂、需要窗口信息和额外状态的一些场景,我们还可以直接使用全窗口函数、把数据全部收集保存在窗口内,等到触发窗口计算时再统一处理。窗口处理函数就是一种典型的全窗口函数。
窗 口 处 理 函 数 ProcessWindowFunction 的 使 用 与 其 他 窗 口 函 数 类 似 , 也 是 基 于WindowedStream 直接调用方法就可以,只不过这时调用的是.process()。
stream.keyBy( t -> t.f0 )
.window( TumblingEventTimeWindows.of(Time.seconds(10)) )
.process(new MyProcessWindowFunction())
7.4 应用案例——Top N
网站中一个非常经典的例子,就是实时统计一段时间内的热门 url。例如,需要统计最近10 秒钟内最热门的两个 url 链接,并且每 5 秒钟更新一次。我们知道,这可以用一个滑动窗口来实现,而“热门度”一般可以直接用访问量来表示。于是就需要开滑动窗口收集 url 的访问数据,按照不同的 url 进行统计,而后汇总排序并最终输出前两名。这其实就是著名的“Top N”
问题。
很显然,简单的增量聚合可以得到 url 链接的访问量,但是后续的排序输出 Top N 就很难实现了。所以接下来我们用窗口处理函数进行实现。
难点:通过增量聚合函数可以输出url链接的访问量,但是后续的排序搞不清楚过来的数据是属于哪个窗口的输出。
所有数据都会放在process中
7.4.1 使用 ProcessAllWindowFunction
一种最简单的想法是,我们干脆不区分 url 链接,而是将所有访问数据都收集起来,统一进行统计计算。所以可以不做 keyBy,直接基于 DataStream 开窗,然后使用全窗口函数ProcessAllWindowFunction 来进行处理。
在窗口中可以用一个 HashMap 来保存每个 url 的访问次数,只要遍历窗口中的所有数据,自然就能得到所有 url 的热门度。最后把 HashMap 转成一个列表 ArrayList,然后进行排序、取出前两名输出就可以了。
package com.atguigu.chapter07;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import com.atguigu.chapter06.UrlCountViewExample;
import com.atguigu.chapter06.UrlViewCount;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimerService;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessAllWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
public class TopNProcessAllWindowFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1. 读取数据
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
// 2. 直接开窗,收集所有数据排序
stream.map(data -> data.url)
.windowAll(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5)))
.aggregate(new UrlHashMapCountAgg(), new UrlAllWindowResult())
.print();
env.execute();
}
// 实现自定义的增量聚合函数
public static class UrlHashMapCountAgg implements AggregateFunction<String, HashMap<String,Long>, ArrayList<Tuple2<String,Long>>>{
@Override
public HashMap<String, Long> createAccumulator() {
return new HashMap<>();
}
@Override
public HashMap<String, Long> add(String s, HashMap<String, Long> stringLongHashMap) {
if( stringLongHashMap.containsKey(s)){
Long count = stringLongHashMap.get(s);
stringLongHashMap.put(s, count + 1);
}else {
stringLongHashMap.put(s, 1L);
}
return stringLongHashMap;
}
@Override
public ArrayList<Tuple2<String, Long>> getResult(HashMap<String, Long> stringLongHashMap) {
ArrayList<Tuple2<String, Long>> result = new ArrayList<>();
for (String s : stringLongHashMap.keySet()) {
result.add(Tuple2.of(s, stringLongHashMap.get(s)));
}
result.sort(new Comparator<Tuple2<String, Long>>() {
@Override
public int compare(Tuple2<String, Long> o1, Tuple2<String, Long> o2) {
return o2.f1.intValue() - o1.f1.intValue();
}
});
return result;
}
@Override
public HashMap<String, Long> merge(HashMap<String, Long> stringLongHashMap, HashMap<String, Long> acc1) {
return null;
}
}
// 实现自定义全窗口函数,包装信息输出结果
public static class UrlAllWindowResult extends ProcessAllWindowFunction<ArrayList<Tuple2<String, Long>>,String, TimeWindow>{
@Override
public void process(ProcessAllWindowFunction<ArrayList<Tuple2<String, Long>>, String, TimeWindow>.Context context, Iterable<ArrayList<Tuple2<String, Long>>> iterable, Collector<String> collector) throws Exception {
ArrayList<Tuple2<String, Long>> list = iterable.iterator().next();
StringBuilder result = new StringBuilder();
result.append("---------------------\n");
result.append(" 窗口结束时间: " + new Timestamp(context.window().getEnd())+"\n");
// 取list前两个,包装信息输出
for (int i = 0; i < 2; i++) {
Tuple2<String, Long> currTuple = list.get(i);
String info = "No. " + (i + 1) + " "
+ "url: " + currTuple.f0 + " "
+ " 访问量 :" + currTuple.f1 + " \n";
result.append(info );
}
result.append("---------------------\n");
collector.collect(result.toString());
}
}
}
7.4.2 使用 KeyedProcessFunction
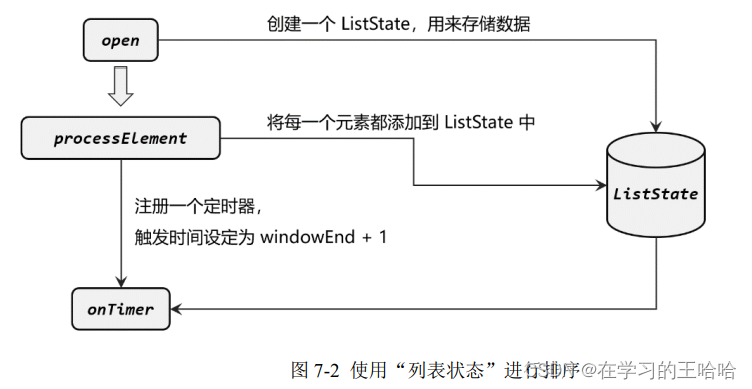
处理的都是数据流
到了一个窗口的触发时间,按照key输出好几个统计结果
不需要开开五秒的窗口,只需要等一会就可以了,数据收集齐就可以了
按照窗口信息windowend进行一个分组,分组之后就是当前同一个窗口收集到的所有统计数据,然后基于所有收集到的所有统计数据定一个定时器,等一会,全部到了之后,把所有数据进行排序输出。
在windowEnd的基础上,多等1ms。因为都是waterMark触发,和乱序数据无关,只要waterMark超过了windowEnd+1MS,我们可以保证所有的数据都到齐了
没有窗口了,我们 应该对后面的算子单独定义一个列表(可以创建状态,状态只跟当前的key 有关系,keyedStated),把所有的数据保存进来。
所以来一个数据,就把它塞进去。而且创建一个按照窗口结束时间+1ms之后的触发的定时器,等到触发定时器的时候确保所有数据都到齐了,我们就从这个状态列表里提取出来,然后做一个排序输出。
我们需要用Flink把 状态列表管理起来,就必须要运行时环境中获取状态,
任务跑起来之后才有运行时,所有我们在open生命周期中获取状态。
package com.atguigu.chapter07;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import com.atguigu.chapter06.UrlCountViewExample;
import com.atguigu.chapter06.UrlViewCount;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Comparator;
public class TopNExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1. 读取数据
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
// 2. url分组,统计窗口内每个url的访问量
SingleOutputStreamOperator<UrlViewCount> urlCountStream = stream.keyBy(data -> data.url)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))) // 定义滑动窗口
.aggregate(new UrlCountViewExample.UrlViewCountAgg(), new UrlCountViewExample.UrlViewCountResult());
urlCountStream.print("url count");
// 3. 对于同一窗口统计出的访问量,进行收集和排序
urlCountStream.keyBy(data -> data.windowEnd)
.process(new TopNProcessResult(2))
.print();
env.execute();
}
// 实现自定义的keyedPridessFunction
public static class TopNProcessResult extends KeyedProcessFunction<Long, UrlViewCount, String>{
// 定义一个属性
private int n;
// 定义列表状态
private ListState<UrlViewCount> urlViewCountListState;
public TopNProcessResult(int n) {
this.n = n;
}
// 在环境中获取状态
@Override
public void open(Configuration parameters) throws Exception {
urlViewCountListState = getRuntimeContext().getListState(
new ListStateDescriptor<UrlViewCount>("url-count-list", Types.POJO(UrlViewCount.class))
);
}
@Override
public void processElement(UrlViewCount value, KeyedProcessFunction<Long, UrlViewCount, String>.Context ctx, Collector<String> out) throws Exception {
// 将数据保存在状态中
urlViewCountListState.add(value);
// 注册windowEnd + 1ms定时器
ctx.timerService().registerEventTimeTimer(ctx.getCurrentKey() + 1);
}
@Override
public void onTimer(long timestamp, KeyedProcessFunction<Long, UrlViewCount, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
ArrayList<UrlViewCount> urlViewCountArrayList = new ArrayList<>();
for (UrlViewCount urlViewCount : urlViewCountListState.get()) {
urlViewCountArrayList.add(urlViewCount);
}
// 排序
urlViewCountArrayList.sort(new Comparator<UrlViewCount>() {
@Override
public int compare(UrlViewCount o1, UrlViewCount o2) {
return o2.count.intValue() - o1.count.intValue();
}
});
// 包装信息,打印输出
StringBuilder result = new StringBuilder();
result.append("---------------------\n");
result.append(" 窗口结束时间: " + new Timestamp(ctx.getCurrentKey())+"\n");
// 取list前两个,包装信息输出
for (int i = 0; i < 2; i++) {
UrlViewCount currTuple = urlViewCountArrayList.get(i);
String info = "No. " + (i + 1) + " "
+ "url: " + currTuple.url + " "
+ " 访问量 :" + currTuple.count + " \n";
result.append(info );
}
result.append("---------------------\n");
out.collect(result.toString());
}
}
}
8. 多流转换
多流转换可以分为“分流”和“合流”两大类。目前分流的操作一般是通过侧输出流(side output)来实现,而合流的算子比较丰富,根据不同的需求可以调用 union、connect、join 以及 coGroup 等接口进行连接合并操作。
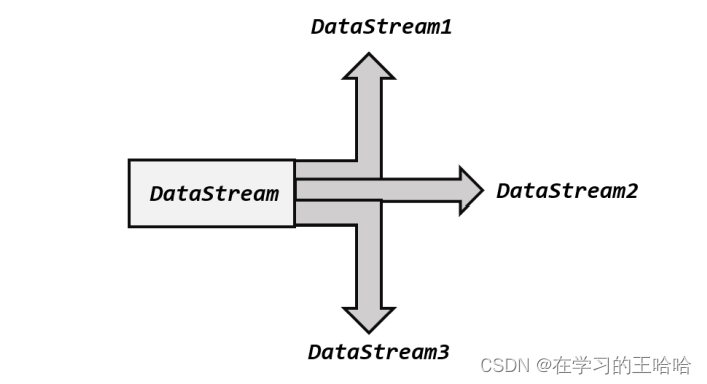
8.1 分流
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个DataStream,得到完全平等的多个子 DataStream,如图所示。一般来说,我们会定义一些筛选条件,将符合条件的数据拣选出来放到对应的流里。
8.1.1 简单实现
底层将流复制了三份
其实根据条件筛选数据的需求,本身非常容易实现:只要针对同一条流多次独立调用.filter()方法进行筛选,就可以得到拆分之后的流了。
例如,我们可以将电商网站收集到的用户行为数据进行一个拆分,根据类型(type)的不同,分为“Mary”的浏览数据、“Bob”的浏览数据等等。那么代码就可以这样实现:
package com.atguigu.chapter08;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SplitStreamByFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env
.addSource(new ClickSource());
// 筛选 Mary 的浏览行为放入 MaryStream 流中
DataStream<Event> MaryStream = stream.filter(new FilterFunction<Event>()
{
@Override
public boolean filter(Event value) throws Exception {
return value.user.equals("Mary");
}
});
// 筛选 Bob 的购买行为放入 BobStream 流中
DataStream<Event> BobStream = stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.user.equals("Bob");
}
});
// 筛选其他人的浏览行为放入 elseStream 流中
DataStream<Event> elseStream = stream.filter(new FilterFunction<Event>()
{
@Override
public boolean filter(Event value) throws Exception {
return !value.user.equals("Mary") && !value.user.equals("Bob") ;
}
});
MaryStream.print("Mary pv");
BobStream.print("Bob pv");
elseStream.print("else pv");
env.execute();
}
}
8.1.2 使用侧输出流
在 Flink 1.13 版本中,已经弃用了.split()方法,取而代之的是直接用处理函数(process function)的侧输出流(side output)。
简单来说,只需要调用上下文 ctx 的.output()方法,就可以输出任意类型的数据了。而侧输出流的标记和提取,都离不开一个“输出标签”(OutputTag),它就相当于 split()分流时的“戳”,指定了侧输出流的id 和类型。
package com.atguigu.chapter08;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
public class SplitStreamTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
// 定义输出标签
OutputTag<Tuple3<String, String, Long>> maryTag = new OutputTag<Tuple3<String, String, Long>>("Mary") {};
OutputTag<Tuple3<String, String, Long>> bobTag = new OutputTag<Tuple3<String, String, Long>>("Bob") {};
SingleOutputStreamOperator<Event> processedStream = stream.process(new ProcessFunction<Event, Event>() {
@Override
public void processElement(Event event, ProcessFunction<Event, Event>.Context context, Collector<Event> collector) throws Exception {
if (event.user.equals("Mary"))
context.output(maryTag, Tuple3.of(event.user, event.url, event.timestamp));
else if (event.user.equals("Bob"))
context.output(bobTag, Tuple3.of(event.user, event.url, event.timestamp));
else
collector.collect(event);
}
});
processedStream.print("else");
processedStream.getSideOutput(maryTag).print("Mary");
processedStream.getSideOutput(bobTag).print("Bob");
env.execute();
}
}
8.2 基本合流操作
8.2.1 联合(Union)
最简单的合流操作,就是直接将多条流合在一起,叫作流的“联合”(union)
联合操作要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。这种合流方式非常简单粗暴,就像公路上多个车道汇在一起一样。
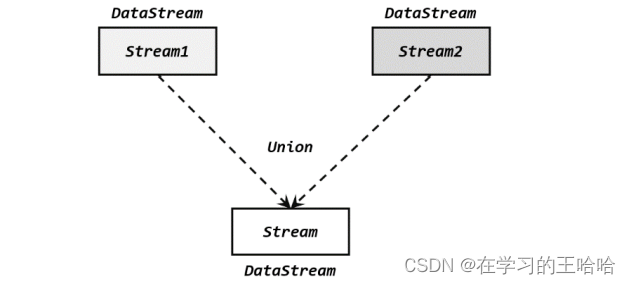
在代码中,我们只要基于 DataStream 直接调用.union()方法,传入其他 DataStream 作为参数,就可以实现流的联合了;得到的依然是一个 DataStream:
stream1.union(stream2, stream3, ...)
注意:union()的参数可以是多个 DataStream,所以联合操作可以实现多条流的合并。
对于合流之后的水位线,也是要以最小的那个为准
package com.atguigu.chapter08;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class UnionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream1 = env.socketTextStream("hadoop102",7777)
.map(data -> {
String[] field = data.split(",");
return new Event(field[0].trim(),field[1].trim(), Long.valueOf(field[2].trim()) );
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream1.print("stream1");
SingleOutputStreamOperator<Event> stream2 = env.socketTextStream("hadoop103",7777)
.map(data -> {
String[] field = data.split(",");
return new Event(field[0].trim(),field[1].trim(), Long.valueOf(field[2].trim()) );
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream2.print("stream2");
// 合并两条流
stream1.union(stream2).process(new ProcessFunction<Event, String>() {
@Override
public void processElement(Event event, ProcessFunction<Event, String>.Context context, Collector<String> collector) throws Exception {
collector.collect("水位线: " + context.timerService().currentWatermark());
}
}).print();
env.execute();
}
}
8.2.2 连接(Connect)应用广泛
连接(connect)。顾名思义,这种操作就是直接把两条流像接线一样对接起来。
两种连接方式
appStream.keyBy(data -> data.f0)
.connect(thirdPartStream.keyBy(data -> data.f0));
appStream.connect(thirdPartStream)
.keyBy(data->data.f0,data-> data.f0);
1. 连接流(ConnectedStreams)
为了处理更加灵活,连接操作允许流的数据类型不同。但我们知道一个 DataStream 中的数据只能有唯一的类型,所以连接得到的并不是 DataStream,而是一个“连接流”(ConnectedStreams)。连接流可以看成是两条流形式上的“统一”,被放在了一个同一个流中;事实上内部仍保持各自的数据形式不变,彼此之间是相互独立的。要想得到新的 DataStream,还需要进一步定义一个“同处理”(co-process)转换操作,用来说明对于不同来源、不同类型的数据,怎样分别进行处理转换、得到统一的输出类型。所以整体上来,两条流的连接就像是“一国两制”,两条流可以保持各自的数据类型、处理方式也可以不同,不过最终还是会统一到同一个 DataStream 中,如图 所示。
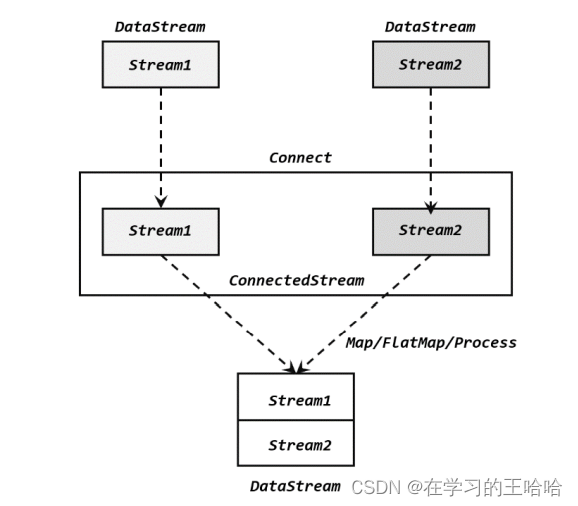
在代码实现上,需要分为两步:首先基于一条 DataStream 调用.connect()方法,传入另外一条 DataStream 作为参数,将两条流连接起来,得到一个 ConnectedStreams;然后再调用同处理方法得到 DataStream。这里可以的调用的同处理方法有.map()/.flatMap(),以及.process()方法。
package com.atguigu.chapter08;
import com.atguigu.chapter05.Event;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
public class ConnectTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Integer> stream1 = env.fromElements(1, 2, 3);
DataStreamSource<Long> stream2 = env.fromElements(4L, 5L, 6L);
stream1.connect(stream2)
.map(new CoMapFunction<Integer, Long, String>() {
@Override
public String map1(Integer integer) throws Exception {
return "Integer: " + integer.toString();
}
@Override
public String map2(Long aLong) throws Exception {
return "Long: " + aLong.toString();
}
}).print();
env.execute();
}
}
2. CoProcessFunction
对于连接流 ConnectedStreams 的处理操作,需要分别定义对两条流的处理转换,因此接口中就会有两个相同的方法需要实现,用数字“1”“2”区分,在两条流中的数据到来时分别调用。我们把这种接口叫作“协同处理函数”(co-process function)。与 CoMapFunction 类似,如果是调用.flatMap()就需要传入一个 CoFlatMapFunction,需要实现 flatMap1()、flatMap2()两个方法;而调用.process()时,传入的则是一个 CoProcessFunction。
下面是 CoProcessFunction 的一个具体示例:我们可以实现一个实时对账的需求,也就是app 的支付操作和第三方的支付操作的一个双流 Join。App 的支付事件和第三方的支付事件将会互相等待 5 秒钟,如果等不来对应的支付事件,那么就输出报警信息。程序如下:
package com.atguigu.chapter08;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class BillCheckExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 来自app的支付日志
SingleOutputStreamOperator<Tuple3<String, String, Long>> appStream = env.fromElements(
Tuple3.of("order-1", "app", 1000L),
Tuple3.of("order-2", "app", 2000L),
Tuple3.of("order-3", "app", 3500L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> stringStringLongTuple3, long l) {
return stringStringLongTuple3.f2;
}
})
);
// 来自第三方支付平台的支付日志
SingleOutputStreamOperator<Tuple4<String, String,String, Long>> thirdPartStream = env.fromElements(
Tuple4.of("order-1", "third-party","success", 3000L),
Tuple4.of("order-3", "third-party","success", 4000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple4<String, String,String, Long>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple4<String, String, String, Long>>() {
@Override
public long extractTimestamp(Tuple4<String, String, String, Long> stringStringStringLongTuple4, long l) {
return stringStringStringLongTuple4.f3;
}
})
);
// 检测统一支付单子在两条流中是否匹配,不匹配就报警
appStream.keyBy(data -> data.f0)
.connect(thirdPartStream.keyBy(data -> data.f0));
appStream.connect(thirdPartStream)
.keyBy(data->data.f0,data-> data.f0)
.process(new OrderMatchResult())
.print();
env.execute();
}
// 自定义是实现CoProcesssFuncton
public static class OrderMatchResult extends CoProcessFunction<Tuple3<String, String, Long>,Tuple4<String, String,String, Long>,String>{
// 定义状态变量,用来保存已经到达的事件
private ValueState<Tuple3<String, String, Long>> appEventState;
private ValueState<Tuple4<String, String,String, Long>> thirdPartyEvent;
@Override
public void open(Configuration parameters) throws Exception {
appEventState = getRuntimeContext().getState(
new ValueStateDescriptor<Tuple3<String, String, Long>>("app-event", Types.TUPLE(Types.STRING, Types.STRING, Types.LONG))
);
thirdPartyEvent = getRuntimeContext().getState(
new ValueStateDescriptor<Tuple4<String, String,String, Long>>("thirdparty-event", Types.TUPLE(Types.STRING, Types.STRING, Types.STRING, Types.LONG))
);
}
@Override
public void processElement1(Tuple3<String, String, Long> stringStringLongTuple3, CoProcessFunction<Tuple3<String, String, Long>, Tuple4<String, String, String, Long>, String>.Context context, Collector<String> collector) throws Exception {
// 来的是app的 event,看另一条流中的事件是否来过
if( thirdPartyEvent.value() != null){
collector.collect("对账成功: " + stringStringLongTuple3 + " " + thirdPartyEvent.value());
// 清空状态
thirdPartyEvent.clear();
}else {
// 更新装载
appEventState.update(stringStringLongTuple3);
// 注册一个定时器,开始等待另一条流的事件
context.timerService().registerEventTimeTimer(stringStringLongTuple3.f2 + 5000L);
}
}
@Override
public void processElement2(Tuple4<String, String, String, Long> stringStringStringLongTuple4, CoProcessFunction<Tuple3<String, String, Long>, Tuple4<String, String, String, Long>, String>.Context context, Collector<String> collector) throws Exception {
if( appEventState.value() != null){
collector.collect("对账成功: " + appEventState.value() + " " + stringStringStringLongTuple4 );
// 清空状态
appEventState.clear();
}else {
// 更新装载
thirdPartyEvent.update(stringStringStringLongTuple4);
// 注册一个定时器,开始等待另一条流的事件
context.timerService().registerEventTimeTimer(stringStringStringLongTuple4.f3);
}
}
@Override
public void onTimer(long timestamp, CoProcessFunction<Tuple3<String, String, Long>, Tuple4<String, String, String, Long>, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
// 定义器触发,判断状态,如果某个状态不为空,说明另一条流中事件没来
if(appEventState.value() != null){
out.collect("对账失败: " + appEventState.value() + " " + "第三方支付平台信息未到");
}
if(thirdPartyEvent.value() != null){
out.collect("对账失败: " + thirdPartyEvent.value() + " " + "app信息未到");
}
appEventState.clear();
thirdPartyEvent.clear();
}
}
}
3. 广播连接流(BroadcastConnectedStream)
关于两条流的连接,还有一种比较特殊的用法:DataStream 调用.connect()方法时,传入的参数也可以不是一个 DataStream,而是一个“广播流”(BroadcastStream),这时合并两条流得到的就变成了一个“广播连接流”(BroadcastConnectedStream)。
这种连接方式往往用在需要动态定义某些规则或配置的场景。因为规则是实时变动的,所以我们可以用一个单独的流来获取规则数据;而这些规则或配置是对整个应用全局有效的,所以不能只把这数据传递给一个下游并行子任务处理,而是要“广播”(broadcast)给所有的并行子任务。而下游子任务收到广播出来的规则,会把它保存成一个状态,这就是所谓的“广播
状态”(broadcast state)。
8.3 基于时间的合流–双流联结(Join)
注:SQL 中 join 一般会翻译为“连接”;我们这里为了区分不同的算子,一般的合流操作connect 翻译为“连接”,而把 join 翻译为“联结”。
8.3.1 窗口联结(Window Join)
基于时间的操作,最基本的当然就是时间窗口了。Flink 为这种场景专门提供了一个窗口联结(window join)算子,可以定义时间窗口,并将两条流中共享一个公共键(key)的数据放在窗口中进行配对处理
1. 窗口联结的调用
窗口联结在代码中的实现,首先需要调用 DataStream 的.join()方法来合并两条流,得到一个 JoinedStreams;接着通过.where()和.equalTo()方法指定两条流中联结的 key;然后通过.window()开窗口,并调用.apply()传入联结窗口函数进行处理计算。通用调用形式如下:
stream1.join(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
上面代码中.where()的参数是键选择器(KeySelector),用来指定第一条流中的 key;
而.equalTo()传入的 KeySelector 则指定了第二条流中的 key。两者相同的元素,如果在同一窗口中,就可以匹配起来,并通过一个“联结函数”(JoinFunction)进行处理了。
这里.window()传入的就是窗口分配器,之前讲到的三种时间窗口都可以用在这里:滚动窗口(tumbling window)、滑动窗口(sliding window)和会话窗口(session window)。
而后面调用.apply()可以看作实现了一个特殊的窗口函数。注意这里只能调用.apply(),没有其他替代的方法。
传入的 JoinFunction 也是一个函数类接口,使用时需要实现内部的.join()方法。这个方法有两个参数,分别表示两条流中成对匹配的数据。
2. 窗口联结的处理流程
两条流的数据到来之后,首先会按照 key 分组、进入对应的窗口中存储;当到达窗口结束时间时,算子会先统计出窗口内两条流的数据的所有组合,也就是对两条流中的数据做一个笛卡尔积(相当于表的交叉连接,cross join),然后进行遍历,把每一对匹配的数据,作为参数(first,second)传入 JoinFunction 的.join()方法进行计算处理,得到的结果直接输出如图 8-8 所示。所以窗口中每有一对数据成功联结匹配,JoinFunction 的.join()方法就会被调用一次,并输出一个结果
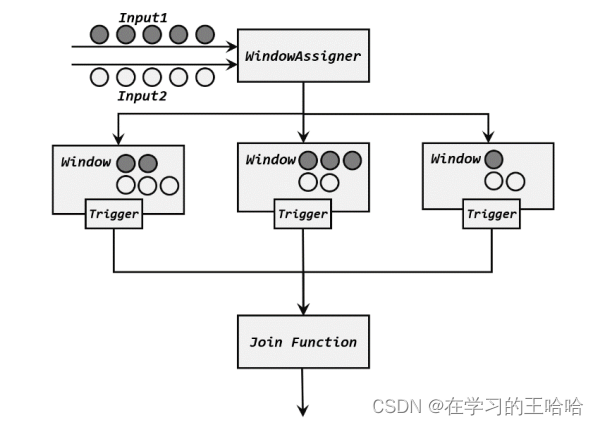
3. 窗口联结实例
在电商网站中,往往需要统计用户不同行为之间的转化,这就需要对不同的行为数据流,按照用户 ID 进行分组后再合并,以分析它们之间的关联。如果这些是以固定时间周期(比如1 小时)来统计的,那我们就可以使用窗口 join 来实现这样的需求。
package com.atguigu.chapter08;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
public class WindowJoinTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple2<String, Long>> stream1 = env.fromElements(
Tuple2.of("a", 1000L),
Tuple2.of("b", 1000L),
Tuple2.of("a", 2000L),
Tuple2.of("b", 2000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
})
);
SingleOutputStreamOperator<Tuple2<String, Integer>> stream2 = env.fromElements(
Tuple2.of("a", 3000),
Tuple2.of("b", 4000),
Tuple2.of("a", 4500),
Tuple2.of("b", 5500)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Integer>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Integer>>() {
@Override
public long extractTimestamp(Tuple2<String, Integer> stringIntegerTuple2, long l) {
return stringIntegerTuple2.f1;
}
})
);
stream1.join(stream2)
.where(data -> data.f0)
.equalTo(data -> data.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction<Tuple2<String, Long>, Tuple2<String, Integer>, Object>() {
@Override
public Object join(Tuple2<String, Long> stringLongTuple2, Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringLongTuple2 + " -> " + stringIntegerTuple2;
}
}).print();
env.execute();
}
}
8.3.2 间隔联结(Interval Join)
不要把窗口时间确定死,基于数据后面一段时间的触发而已
间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,看这期间是否有来自另一条流的数据匹配。
1. 间隔联结的原理
间隔联结具体的定义方式是,我们给定两个时间点,分别叫作间隔的“上界”(upperBound)和“下界”(lowerBound);于是对于一条流(不妨叫作 A)中的任意一个数据元素 a,就可以开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound],即以 a 的时间戳为中心,下至下界点、上至上界点的一个闭区间:我们就把这段时间作为可以匹配另一条流数据的“窗口”范围。所以对于另一条流(不妨叫 B)中的数据元素 b,如果它的时间戳落在了这个区间范围内,a 和 b 就可以成功配对,进而进行计算输出结果。所以匹配的条件为:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
这里需要注意,做间隔联结的两条流 A 和 B,也必须基于相同的 key;下界 lowerBound应该小于等于上界 upperBound,两者都可正可负;间隔联结目前只支持事件时间语义。
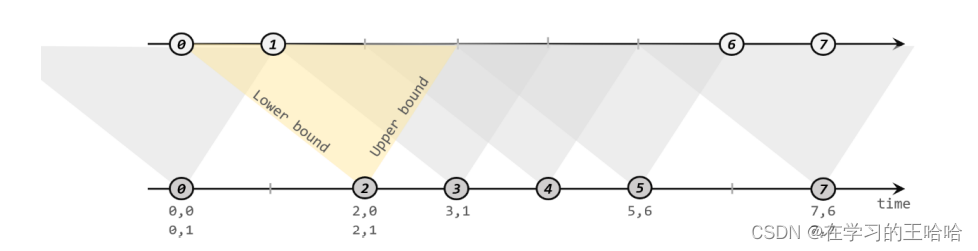
2. 间隔联结的调用
间隔联结在代码中,是基于 KeyedStream 的联结(join)操作。DataStream 在 keyBy 得到KeyedStream 之后,可以调用.intervalJoin()来合并两条流,传入的参数同样是一个 KeyedStream,两者的 key 类型应该一致;得到的是一个 IntervalJoin 类型。后续的操作同样是完全固定的:
先通过.between()方法指定间隔的上下界,再调用.process()方法,定义对匹配数据对的处理操作。调用.process()需要传入一个处理函数,这是处理函数家族的最后一员:“处理联结函数”ProcessJoinFunction。
stream1
.keyBy(<KeySelector>)
.intervalJoin(stream2.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx,
Collector<String> out) {
out.collect(left + "," + right);
}
});
3. 间隔联结实例
在电商网站中,某些用户行为往往会有短时间内的强关联。我们这里举一个例子,我们有两条流,一条是下订单的流,一条是浏览数据的流。我们可以针对同一个用户,来做这样一个联结。也就是使用一个用户的下订单的事件和这个用户的最近十分钟的浏览数据进行一个联结查询
package com.atguigu.chapter08;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class IntervalJoinExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple2<String, Long>> orderStream = env.fromElements(
Tuple2.of("Mary", 5000L),
Tuple2.of("Alice", 5000L),
Tuple2.of("Bob", 20000L),
Tuple2.of("Alice", 20000L),
Tuple2.of("Alice", 51000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
})
);
SingleOutputStreamOperator<Event> clickStream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("BOb", "./cart", 2000L),
new Event("BOb", "./prod?id=100", 3000L),
new Event("BOb", "./prod?id=18", 3900L),
new Event("BOb", "./prod?id=140", 4000L),
new Event("Alice", "./prod?id=140", 5000L),
new Event("Alice", "./prod?id=240", 20000L),
new Event("Alice", "./prod?id=040", 5000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
orderStream.keyBy(data -> data.f0)
.intervalJoin(clickStream.keyBy(data -> data.user))
.between(Time.seconds(-5),Time.seconds(10))
.process(new ProcessJoinFunction<Tuple2<String, Long>, Event, Object>() {
@Override
public void processElement(Tuple2<String, Long> stringLongTuple2, Event event, ProcessJoinFunction<Tuple2<String, Long>, Event, Object>.Context context, Collector<Object> collector) throws Exception {
collector.collect(event + " =》 " + stringLongTuple2);
}
}).print();
env.execute();
}
}
8.3.3 窗口同组联结(Window CoGroup)
它的用法跟 window join 非常类似,也是将两条流合并之后开窗处理匹配的元素,调用时只需要将.join()换为.coGroup()就可以了。
stream1.coGroup(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.apply(<CoGroupFunction>)
与 window join 的区别在于,调用.apply()方法定义具体操作时,传入的是一个CoGroupFunction。这也是一个函数类接口。
内部的.coGroup()方法,有些类似于 FlatJoinFunction 中.join()的形式,同样有三个参数,分别代表两条流中的数据以及用于输出的收集器(Collector)。不同的是,这里的前两个参数不再是单独的每一组“配对”数据了,而是传入了可遍历的数据集合。也就是说,现在不会再去计算窗口中两条流数据集的笛卡尔积,而是直接把收集到的所有数据一次性传入,至于要怎样配对完全是自定义的。这样.coGroup()方法只会被调用一次,而且即使一条流的数据没有任何另一条流的数据匹配,也可以出现在集合中、当然也可以定义输出结果了。
所以能够看出,coGroup 操作比窗口的 join 更加通用,不仅可以实现类似 SQL 中的“内连接”(inner join),也可以实现左外连接(left outer join)、右外连接(right outer join)和全外连接(full outer join)。事实上,窗口 join 的底层,也是通过 coGroup 来实现的。
package com.atguigu.chapter08;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class CoGroupTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple2<String, Long>> stream1 = env.fromElements(
Tuple2.of("a", 1000L),
Tuple2.of("b", 1000L),
Tuple2.of("a", 2000L),
Tuple2.of("b", 2000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
})
);
SingleOutputStreamOperator<Tuple2<String, Integer>> stream2 = env.fromElements(
Tuple2.of("a", 3000),
Tuple2.of("b", 4000),
Tuple2.of("a", 4500),
Tuple2.of("b", 5500)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Integer>>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Integer>>() {
@Override
public long extractTimestamp(Tuple2<String, Integer> stringIntegerTuple2, long l) {
return stringIntegerTuple2.f1;
}
})
);
stream1.coGroup(stream2)
.where(data -> data.f0)
.equalTo(data -> data.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new CoGroupFunction<Tuple2<String, Long>, Tuple2<String, Integer>, Object>() {
@Override
public void coGroup(Iterable<Tuple2<String, Long>> iterable, Iterable<Tuple2<String, Integer>> iterable1, Collector<Object> collector) throws Exception {
collector.collect(iterable + " => " + iterable1);
}
}).print();
env.execute();
}
}
9. 状态编程
Flink处理机制的核心,就是“有状态的流式计算”
9.1 Flink 中的状态
在流处理中,数据是连续不断到来和处理的。每个任务进行计算处理时,可以基于当前数据直接转换得到输出结果;也可以依赖一些其他数据。这些由一个任务维护,并且用来计算输出结果的所有数据,就叫作这个任务的状态。
9.1.1 有状态算子
在 Flink 中,算子任务可以分为无状态和有状态两种情况。
无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果,如图 9-1 所示。例如,可以将一个字符串类型的数据拆分开作为元组输出;也可以对数据做一些计算,比如每个代表数量的字段加 1。我们之前讲到的基本转换算子,如 map、filter、flatMap,计算时不依赖其他数据,就都属于无状态的算子。

而有状态的算子任务,则除当前数据之外,还需要一些其他数据来得到计算结果。这里的“其他数据”,就是所谓的状态(state),最常见的就是之前到达的数据,或者由之前数据计算出的某个结果。比如,做求和(sum)计算时,需要保存之前所有数据的和,这就是状态;窗口算子中会保存已经到达的所有数据,这些也都是它的状态。另外,如果我们希望检索到某种“事件模式”(event pattern),比如“先有下单行为,后有支付行为”,那么也应该把之前的行为保存下来,这同样属于状态。容易发现,之前讲过的聚合算子、窗口算子都属于有状态的算子。
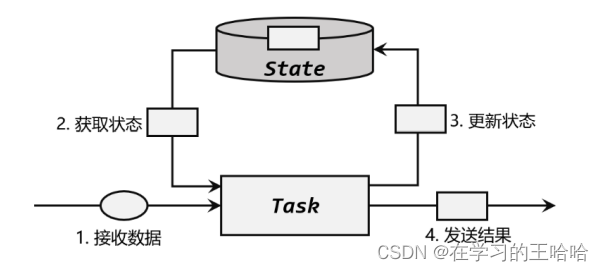
如图所示为有状态算子的一般处理流程,具体步骤如下。
(1)算子任务接收到上游发来的数据;
(2)获取当前状态;
(3)根据业务逻辑进行计算,更新状态;
(4)得到计算结果,输出发送到下游任务。
9.1.2 状态的管理
在传统的事务型处理架构中,这种额外的状态数据是保存在数据库中的。而对于实时流处理来说,这样做需要频繁读写外部数据库,如果数据规模非常大肯定就达不到性能要求了。所以 Flink 的解决方案是,将状态直接保存在内存中来保证性能,并通过分布式扩展来提高吞吐量。
在 Flink 中,每一个算子任务都可以设置并行度,从而可以在不同的 slot 上并行运行多个实例,我们把它们叫作“并行子任务”。而状态既然在内存中,那么就可以认为是子任务实例上的一个本地变量,能够被任务的业务逻辑访问和修改。
Flink 有一套完整的状态管理机制,将底层一些核心功能全部封装起来,包括状态的高效存储和访问、持久化保存和故障恢复,以及资源扩展时的调整。
9.1.3 状态的分类
1. 托管状态(Managed State)和原始状态(Raw State)
托管状态就是由 Flink 统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由 Flink 实现,我们只要调接口就可以;Flink 也提供了值状态(ValueState)、列表状态(ListState)、映射状态(MapState)、聚合状态(AggregateState)等多种结构,内部支持各种数据类型。
而原始状态则是自定义的,相当于就是开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复。
2. 算子状态(Operator State)和按键分区状态(Keyed State)
(1)算子状态(Operator State)
状态作用范围限定为当前的算子任务实例,也就是只对当前并行子任务实例有效。这就意味着对于一个并行子任务,占据了一个“分区”,它所处理的所有数据都会访问到相同的状态,状态对于同一任务而言是共享的,
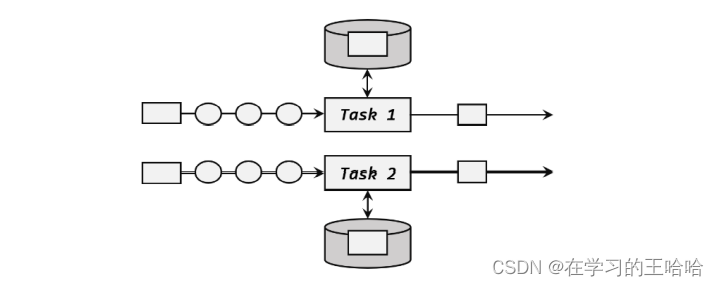
算子状态可以用在所有算子上,使用的时候其实就跟一个本地变量没什么区别——因为本地变量的作用域也是当前任务实例。在使用时,我们还需进一步实现 CheckpointedFunction 接口。
(2)按键分区状态(Keyed State)
状态是根据输入流中定义的键(key)来维护和访问的,所以只能定义在按键分区流(KeyedStream)中,也就 keyBy 之后才可以使用,
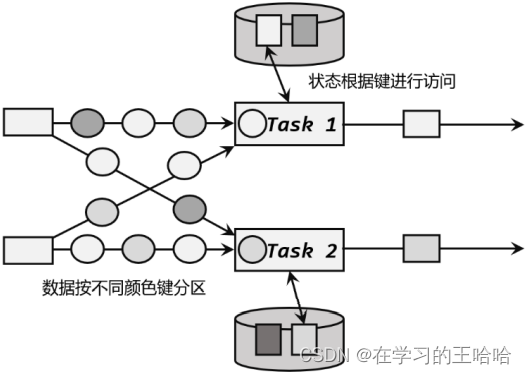
按键分区状态应用非常广泛。之前讲到的聚合算子必须在 keyBy 之后才能使用,就是因为聚合的结果是以 Keyed State 的形式保存的。另外,也可以通过富函数类(Rich Function)来自定义 Keyed State,所以只要提供了富函数类接口的算子,也都可以使用 Keyed State。
所以即使是 map、filter 这样无状态的基本转换算子,我们也可以通过富函数类给它们“追加”Keyed State,或者实现 CheckpointedFunction 接口来定义 Operator State;从这个角度讲,Flink 中所有的算子都可以是有状态的,不愧是“有状态的流处理”
9.2 按键分区状态(Keyed State)
在实际应用中,我们一般都需要将数据按照某个 key 进行分区,然后再进行计算处理;所以最为常见的状态类型就是 Keyed State。之前介绍到 keyBy 之后的聚合、窗口计算,算子所持有的状态,都是 Keyed State。
9.2.1 基本概念和特点
按键分区状态(Keyed State)顾名思义,是任务按照键(key)来访问和维护的状态。它的特点非常鲜明,就是以 key 为作用范围进行隔离。
- 相同 key 的所有数据都会到访问相同的状态,而不同 key 的状态之间是彼此隔离的
- 保证了对状态的操作都是本地进行的,对数据流和状态的处理做到了分区一致性
- 在应用的并行度改变时,状态也需要随之进行重组。
需要注意,使用 Keyed State 必须基于 KeyedStream。没有进行 keyBy 分区的 DataStream,即使转换算子实现了对应的富函数类,也不能通过运行时上下文访问 Keyed State。
9.2.2 支持的结构类型
1. 值状态(ValueState)
顾名思义,状态中只保存一个“值”(value)
public interface ValueState<T> extends State {
T value() throws IOException;
void update(T value) throws IOException;
}
我们可以在代码中读写值状态,实现对于状态的访问和更新。
T value():获取当前状态的值;update(T value):对状态进行更新,传入的参数 value 就是要覆写的状态值。
在具体使用时,为了让运行时上下文清楚到底是哪个状态,我们还需要创建一个“状态描述器”(StateDescriptor)来提供状态的基本信息。例如源码中,ValueState 的状态描述器构造方法如下:
public ValueStateDescriptor(String name, Class<T> typeClass) {
super(name, typeClass, null);
}
这里需要传入状态的名称和类型——这跟我们声明一个变量时做的事情完全一样。有了这个描述器,运行时环境就可以获取到状态的控制句柄(handler)了。
2. 列表状态(ListState)
将需要保存的数据,以列表(List)的形式组织起来。在 ListState接口中同样有一个类型参数 T,表示列表中数据的类型。ListState 也提供了一系列的方法来操作状态,使用方式与一般的 List 非常相似
Iterable<T> get():获取当前的列表状态,返回的是一个可迭代类型 Iterable;update(List<T> values):传入一个列表 values,直接对状态进行覆盖;add(T value):在状态列表中添加一个元素 value;addAll(List<T> values):向列表中添加多个元素,以列表 values 形式传入
3. 映射状态(MapState)
把一些键值对(key-value)作为状态整体保存起来,可以认为就是一组 key-value 映射的列表。对应的 MapState<UK, UV>接口中,就会有 UK、UV 两个泛型,分别表示保存的 key和 value 的类型。同样,MapState 提供了操作映射状态的方法,与 Map 的使用非常类似。
UV get(UK key):传入一个 key 作为参数,查询对应的 value 值;put(UK key, UV value):传入一个键值对,更新 key 对应的 value 值;putAll(Map<UK, UV> map):将传入的映射 map 中所有的键值对,全部添加到映射状态中;remove(UK key):将指定 key 对应的键值对删除;boolean contains(UK key):判断是否存在指定的 key,返回一个 boolean 值。另外,MapState 也提供了获取整个映射相关信息的方法:Iterable<Map.Entry<UK, UV>> entries():获取映射状态中所有的键值对;Iterable<UK> keys():获取映射状态中所有的键(key),返回一个可迭代 Iterable 类型;Iterable<UV> values():获取映射状态中所有的值(value),返回一个可迭代 Iterable类型;boolean isEmpty():判断映射是否为空,返回一个 boolean 值。
4. 归约状态(ReducingState)
类似于值状态(Value),不过需要对添加进来的所有数据进行归约,将归约聚合之后的值作为状态保存下来。
5. 聚合状态(AggregatingState)
与归约状态非常类似,聚合状态也是一个值,用来保存添加进来的所有数据的聚合结果。与 ReducingState 不同的是,它的聚合逻辑是由在描述器中传入一个更加一般化的聚合函数(AggregateFunction)来定义的;这也就是之前我们讲过的 AggregateFunction,里面通过一个累加器(Accumulator)来表示状态,所以聚合的状态类型可以跟添加进来的数据类型完全不同,使用更加灵活。
9.2.3 代码实现
ValueState myValueState;
ListState myListState;
MapState<String, Long> myMapState;
ReducingState myReducingState;
AggregatingState<Event, String> myAggregatingState;
package com.atguigu.chapter09;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.*;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class StateTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream.keyBy(data -> data.user)
.flatMap(new MyFlatMap()).print();
env.execute();
}
// 实现自定义的FlatMapFunction, 用于KeyedSteate测试
public static class MyFlatMap extends RichFlatMapFunction<Event, String>{
// 定义状态
ValueState<Event> myValueState;
ListState<Event> myListState;
MapState<String, Long> myMapState;
ReducingState<Event> myReducingState;
AggregatingState<Event, String> myAggregatingState;
// 增加一个本地变量进行对比
int count = 0;
@Override
public void open(Configuration parameters) throws Exception {
myValueState = getRuntimeContext().getState(new ValueStateDescriptor<Event>("my-state",Event.class));
myListState = getRuntimeContext().getListState(new ListStateDescriptor<Event>("my-list-state",Event.class));
myMapState = getRuntimeContext().getMapState(new MapStateDescriptor<String, Long>("my-map", String.class,Long.class));
myReducingState = getRuntimeContext().getReducingState(new ReducingStateDescriptor<Event>("my-reduce", new ReduceFunction<Event>() {
@Override
public Event reduce(Event event, Event t1) throws Exception {
return new Event(event.user, event.url, t1.timestamp);
}
}, Event.class));
myAggregatingState = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor<Event, Long, String>("my-agg"
, new AggregateFunction<Event, Long, String>() {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event event, Long aLong) {
return aLong + 1;
}
@Override
public String getResult(Long aLong) {
return "count : " + aLong;
}
@Override
public Long merge(Long aLong, Long acc1) {
return acc1 + aLong;
}
}
, Long.class));
}
@Override
public void flatMap(Event event, Collector<String> collector) throws Exception {
// 访问和更新状态
System.out.println(myValueState.value());
myValueState.update(event);
//System.out.println("My value :" + myValueState.value());
myListState.add(event);
myMapState.put(event.user, myMapState.get(event.user) == null ? 1 : myMapState.get(event.user) + 1);
System.out.println("My map State : " + event.user+ " " + myMapState.get(event.user));
myAggregatingState.add(event);
System.out.println("my agg State : " + myAggregatingState.get());
myReducingState.add(event);
System.out.println("reducing State : " + myReducingState.get());
count++;
System.out.println("count : " + count);
}
}
}
不同类型的状态的应用实例
1. 值状态(ValueState)
我们这里会使用用户 id 来进行分流,然后分别统计每个用户的 pv 数据,由于我们并不想每次 pv 加一,就将统计结果发送到下游去,所以这里我们注册了一个定时器,用来隔一段时间发送 pv 的统计结果,这样对下游算子的压力不至于太大。具体实现方式是定义一个用来保存定时器时间戳的值状态变量。当定时器触发并向下游发送数据以后,便清空储存定时器时间戳的状态变量,这样当新的数据到来时,发现并没有定时器存在,就可以注册新的定时器了,注册完定时器之后将定时器的时间戳继续保存在状态变量中。
package com.atguigu.chapter09;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class PeriodicPvExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream.print("input");
// 统计每个用户的pv
stream.keyBy(data -> data.user)
.process(new PeriodicPvPesult())
.print();
env.execute();
}
// 实现自定义的KeyedProcessFunction
public static class PeriodicPvPesult extends KeyedProcessFunction<String, Event, String>{
// 定义状态,保存当前pv统计值, 以及有没有定时器
ValueState<Long> countState;
ValueState<Long> timerTsState;
@Override
public void open(Configuration parameters) throws Exception {
countState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("count", Long.class));
timerTsState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("timer-ts",Long.class));
}
@Override
public void processElement(Event event, KeyedProcessFunction<String, Event, String>.Context context, Collector<String> collector) throws Exception {
// 每来一条数据,就更新对应的count值
Long count = countState.value();
countState.update(count == null ? 1 : count + 1);
// 注册定时器,如果没有注册定时器的话,采取注册定时器
if(timerTsState.value() == null){
context.timerService().registerEventTimeTimer(event.timestamp + 10 * 1000L);
timerTsState.update(event.timestamp + 10 * 1000L);
}
}
@Override
public void onTimer(long timestamp, KeyedProcessFunction<String, Event, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
// 定时器触发输出一次统计结果
out.collect(ctx.getCurrentKey() + " pv: " + countState.value());
// 清空状态
timerTsState.clear();
//countState.clear(); 如果加上就和十秒钟滚动窗口类似了,但又不完全一样, 我们是基于每来一条数据之后才去定义定时器
// 不增加,数据到来时才触发注册定时器
// 增加了,就立马注册定时器
ctx.timerService().registerEventTimeTimer(timestamp + 10 * 1000L);
timerTsState.update(timestamp + 10 * 1000L);
}
}
}
2. 列表状态(ListState)
在 Flink SQL 中,支持两条流的全量 Join,语法如下:
SELECT * FROM A INNER JOIN B WHERE A.id = B.id;
这样一条 SQL 语句要慎用,因为 Flink 会将 A 流和 B 流的所有数据都保存下来,然后进行 Join。不过在这里我们可以用列表状态变量来实现一下这个 SQL 语句的功能。代码如下:
package com.atguigu.chapter09;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class TwoStreamJoinExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple3<String, String, Long>> stream1 = env.fromElements(
Tuple3.of("a", "stream-1", 1000L),
Tuple3.of("b", "stream-1", 2000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple3<String, String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> t, long l) {
return t.f2;
}
})
);
SingleOutputStreamOperator<Tuple3<String, String, Long>> stream2 = env.fromElements(
Tuple3.of("a", "stream-2", 3000L),
Tuple3.of("b", "stream-2", 4000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple3<String, String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> t, long l) {
return t.f2;
}
}));
// 自定义列表状态进行全外联结
stream1.keyBy(data -> data.f0)
.connect(stream2.keyBy(data -> data.f0))
.process(new CoProcessFunction<Tuple3<String, String, Long>, Tuple3<String, String, Long>, String>() {
// 定义列表状态,用于保存两条流中,已经到达的所有数据
private ListState<Tuple2<String,Long>> stream1ListState;
private ListState<Tuple2<String, Long>> stream2ListState;
@Override
public void open(Configuration parameters) throws Exception {
stream1ListState = getRuntimeContext().getListState(new ListStateDescriptor<Tuple2<String, Long>>(
"stream1-list",
Types.TUPLE(Types.STRING, Types.LONG)));
stream2ListState = getRuntimeContext().getListState(new ListStateDescriptor<Tuple2<String, Long>>(
"stream2-list",
Types.TUPLE(Types.STRING, Types.LONG)));
}
@Override
public void processElement1(Tuple3<String, String, Long> left, CoProcessFunction<Tuple3<String, String, Long>, Tuple3<String, String, Long>, String>.Context context, Collector<String> collector) throws Exception {
// 获取另一条流中所有数据,配对输出
for (Tuple2<String, Long> right : stream2ListState.get()) {
collector.collect(left.f0 + " " + left.f2 + " -> " + right);
}
stream1ListState.add(Tuple2.of(left.f0, left.f2));
}
@Override
public void processElement2(Tuple3<String, String, Long> right, CoProcessFunction<Tuple3<String, String, Long>, Tuple3<String, String, Long>, String>.Context context, Collector<String> collector) throws Exception {
for (Tuple2<String, Long> left : stream1ListState.get()) {
collector.collect(left + " -> " + right.f0 + " " + right.f2);
}
stream2ListState.add(Tuple2.of(right.f0, right.f2));
}
}).print();
env.execute();
}
}
3. 映射状态(MapState)
映射状态的用法和 Java 中的 HashMap 很相似。在这里我们可以通过 MapState 的使用来探索一下窗口的底层实现,也就是我们要用映射状态来完整模拟窗口的功能。这里我们模拟一个滚动窗口。我们要计算的是每一个 url 在每一个窗口中的 pv 数据。我们之前使用增量聚合和全窗口聚合结合的方式实现过这个需求。这里我们用 MapState 再来实现一下。
每一个窗口都应该有个list,来保存当前的所有数据。不同窗口的数据还应该按照窗口的起始或者结束时间戳去做分别的保存。
(已经按照不同的key划分开了)我们可以使用HashMap, key为窗口的id,value为count值
package com.atguigu.chapter09;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.Map;
public class FakedWindowExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
// 乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream.print("data");
stream.keyBy(data-> data.url)
.process(new FakedWindowResult(10000L))
.print();
env .execute();
}
// 实现自定义的KeyedProcessFunction
public static class FakedWindowResult extends KeyedProcessFunction<String, Event, String> {
private Long windowSize;
public FakedWindowResult(Long windowSize) {
this.windowSize = windowSize;
}
// 定义一个mapState,用来保存每个窗口中统计的count值
MapState<Long, Long> windowUrlCountMapState;
@Override
public void open(Configuration parameters) throws Exception {
windowUrlCountMapState = getRuntimeContext().getMapState(new MapStateDescriptor<Long, Long>("window-Count", Long.class, Long.class));
}
@Override
public void processElement(Event event, KeyedProcessFunction<String, Event, String>.Context context, Collector<String> collector) throws Exception {
// 每来一条数据,根据数据戳判断属于哪个窗口(窗口分配器)
Long windowStart = event.timestamp / windowSize * windowSize;
Long windowEnd = windowStart + windowSize;
// 注册 end - 1 的定时器
context.timerService().registerEventTimeTimer(windowEnd - 1);
// 更新状态,进行增量聚合
if (windowUrlCountMapState.contains(windowStart)) {
Long count = windowUrlCountMapState.get(windowStart);
windowUrlCountMapState.put(windowStart, count + 1);
} else {
windowUrlCountMapState.put(windowStart, 1L);
}
}
// 定时器触发时 输出计算结果
@Override
public void onTimer(long timestamp, KeyedProcessFunction<String, Event, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
Long windowEnd = timestamp + 1;
Long windowStart = windowEnd - windowSize;
Long count = windowUrlCountMapState.get(windowStart);
out.collect("窗口: " + new Timestamp(windowStart) + " ~ " + new Timestamp(windowEnd)
+ " Url: " + ctx.getCurrentKey()
+ " count : " + count);
// 模拟窗口的关闭,清除 map中对应的key-value
windowUrlCountMapState.remove(windowStart);
}
}
}
4. 聚合状态(AggregatingState)
我们举一个简单的例子,对用户点击事件流每 5 个数据统计一次平均时间戳。这是一个类似计数窗口(CountWindow)求平均值的计算,这里我们可以使用一个有聚合状态的RichFlatMapFunction 来实现
package com.atguigu.chapter09;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.AggregatingState;
import org.apache.flink.api.common.state.AggregatingStateDescriptor;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class AverageTimestampExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
// 乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream.print("data");
// 自定义实现平均时间戳的统计
stream.keyBy(data -> data.user)
// 可以不用prcessfunction, 因为之前需要定义定时器,和时间有关
// 我们只需要简单的转换,自定义状态就可以了, 要用到状态,所以用rich
.flatMap(new AvgTsRuselt(5L))
.print();
env .execute();
}
// 实现自定义的 RichFlatmapFunction
public static class AvgTsRuselt extends RichFlatMapFunction<Event, String>{
private Long count;
public AvgTsRuselt(Long count) {
this.count = count;
}
// 定义一个聚合的状态,用来保存平均时间戳
AggregatingState<Event,Long> avgTsAggState;
// 定义一个值状态。保存用户访问的次数
ValueState<Long> countState;
@Override
public void open(Configuration parameters) throws Exception {
avgTsAggState = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor<Event, Tuple2<Long, Long>, Long>(
"avg-ts",
new AggregateFunction<Event, Tuple2<Long, Long>, Long>() {
@Override
public Tuple2<Long, Long> createAccumulator() {
return Tuple2.of(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Event event, Tuple2<Long, Long> longLongTuple2) {
return Tuple2.of(longLongTuple2.f0 + event.timestamp, longLongTuple2.f1 + 1);
}
@Override
public Long getResult(Tuple2<Long, Long> longLongTuple2) {
return longLongTuple2.f0 / longLongTuple2.f1;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> longLongTuple2, Tuple2<Long, Long> acc1) {
return null;
}
},
Types.TUPLE(Types.LONG, Types.LONG)
));
countState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("count", Long.class));
}
@Override
public void flatMap(Event event, Collector<String> collector) throws Exception {
// 每来一条数据, curr count 加1
Long currCount = countState.value();
if(currCount== null){
currCount = 1L;
}else {
currCount ++ ;
}
// 更新状态
countState.update(currCount);
avgTsAggState.add(event);
// 如果达到count次数就输出结果
if(currCount.equals(count)){
collector.collect(event.user + " 过去" + count + "次访问平均时间戳为: " + avgTsAggState.get());
// 清理状态
countState.clear();
avgTsAggState.clear();
}
}
}
}
9.2.4 状态生存时间(TTL)
在实际应用中,很多状态会随着时间的推移逐渐增长,如果不加以限制,最终就会导致存储空间的耗尽。一个优化的思路是直接在代码中调用.clear()方法去清除状态,但是有时候我们的逻辑要求不能直接清除。这时就需要配置一个状态的“生存时间”(time-to-live,TTL),当状态在内存中存在的时间超出这个值时,就将它清除。
每一次更新状态进行刷新
配置状态的 TTL 时,需要创建一个 StateTtlConfig 配置对象,然后调用状态描述器的.enableTimeToLive()方法启动 TTL 功能。
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<Event> valueStateDescriptor = new ValueStateDescriptor<>("my-state", Event.class);
myValueState = getRuntimeContext().getState(valueStateDescriptor);
// 配置状态的TTL
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.hours(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
.build();
valueStateDescriptor.enableTimeToLive(ttlConfig);
}
这里用到了几个配置项:
- .newBuilder()
状态 TTL 配置的构造器方法,必须调用,返回一个 Builder 之后再调用.build()方法就可以得到 StateTtlConfig 了。方法需要传入一个 Time 作为参数,这就是设定的状态生存时间。 - .setUpdateType()
设置更新类型。更新类型指定了什么时候更新状态失效时间,这里的 OnCreateAndWrite表示只有创建状态和更改状态(写操作)时更新失效时间。另一种类型 OnReadAndWrite 则表示无论读写操作都会更新失效时间,也就是只要对状态进行了访问,就表明它是活跃的,从而延长生存时间。这个配置默认为 OnCreateAndWrite。 - .setStateVisibility()
设置状态的可见性。所谓的“状态可见性”,是指因为清除操作并不是实时的,所以当状态过期之后还有可能基于存在,这时如果对它进行访问,能否正常读取到就是一个问题了。这里设置的 NeverReturnExpired 是默认行为,表示从不返回过期值,也就是只要过期就认为它已经被清除了,应用不能继续读取;这在处理会话或者隐私数据时比较重要。对应的另一种配置是 ReturnExpireDefNotCleanedUp,就是如果过期状态还存在,就返回它的值。
除此之外,TTL 配置还可以设置在保存检查点(checkpoint)时触发清除操作,或者配置增量的清理(incremental cleanup),还可以针对 RocksDB 状态后端使用压缩过滤器(compaction filter)进行后台清理。关于检查点和状态后端的内容,我们会在后续章节继续讲解。
这里需要注意,目前的 TTL 设置只支持处理时间。另外,所有集合类型的状态(例如ListState、MapState)在设置 TTL 时,都是针对每一项(per-entry)元素的。也就是说,一个列表状态中的每一个元素,都会以自己的失效时间来进行清理,而不是整个列表一起清理。
9.3 算子状态(Operator State)
算子状态功能不如按键分区状态丰富,应用场景较少,它的调用方法也会有一些区别。
9.3.1 基本概念和特点
算子状态(Operator State)就是一个算子并行实例上定义的状态,作用范围被限定为当前算子任务。算子状态跟数据的 key 无关,所以不同 key 的数据只要被分发到=同一个并行子任务,就会访问到同一个 Operator State。
算子状态的实际应用场景不如 Keyed State 多,一般用在 Source 或 Sink 等与外部系统连接的算子上,或者完全没有 key 定义的场景。比如 Flink 的 Kafka 连接器中,就用到了算子状态。
在我们给 Source 算子设置并行度后,Kafka 消费者的每一个并行实例,都会为对应的主题(topic)分区维护一个偏移量, 作为算子状态保存起来。这在保证 Flink 应用“精确一次”(exactly-once)状态一致性时非常有用。
当算子的并行度发生变化时,算子状态也支持在并行的算子任务实例之间做重组分配。根据状态的类型不同,重组分配的方案也会不同。
9.3.2 状态类型
算子状态也支持不同的结构类型,主要有三种:ListState、UnionListState 和 BroadcastState。
1. 列表状态(ListState)
与 Keyed State 中的 ListState 一样,将状态表示为一组数据的列表。
与 Keyed State 中的列表状态的区别是:在算子状态的上下文中,不会按键(key)分别处理状态,所以每一个并行子任务上只会保留一个“列表”(list),也就是当前并行子任务上所有状态项的集合。列表中的状态项就是可以重新分配的最细粒度,彼此之间完全独立。
分配策略
当算子并行度进行缩放调整时,算子的列表状态中的所有元素项会被统一收集起来,相当于把多个分区的列表合并成了一个“大列表”,然后再均匀地分配给所有并行任务。这种“均匀分配”的具体方法就是“轮询”(round-robin),与之前介绍的 rebanlance 数据传输方式类似,是通过逐一“发牌”的方式将状态项平均分配的。这种方式也叫作“平均分割重组”(even-split redistribution)。
2. 联合列表状态(UnionListState)
与 ListState 类似,联合列表状态也会将状态表示为一个列表。它与常规列表状态的区别在于,算子并行度进行缩放调整时对于状态的分配方式不同。
UnionListState 的重点就在于“联合”(union)。在并行度调整时,常规列表状态是轮询分配状态项,而联合列表状态的算子则会直接广播状态的完整列表。这样,并行度缩放之后的并行子任务就获取到了联合后完整的“大列表”,可以自行选择要使用的状态项和要丢弃的状态项。这种分配也叫作“联合重组”(union redistribution)。如果列表中状态项数量太多,为资源和效率考虑一般不建议使用联合重组的方式。
3. 广播状态(BroadcastState)
有时我们希望算子并行子任务都保持同一份“全局”状态,用来做统一的配置和规则设定。这时所有分区的所有数据都会访问到同一个状态,状态就像被“广播”到所有分区一样,这种特殊的算子状态,就叫作广播状态(BroadcastState)。
因为广播状态在每个并行子任务上的实例都一样,所以在并行度调整的时候就比较简单,只要复制一份到新的并行任务就可以实现扩展;而对于并行度缩小的情况,可以将多余的并行子任务连同状态直接砍掉——因为状态都是复制出来的,并不会丢失。
在底层,广播状态是以类似映射结构(map)的键值对(key-value)来保存的,必须基于一个“广播流”(BroadcastStream)来创建。
9.3.3 代码实现
1. CheckpointedFunction 接口
在 Flink 中,对状态进行持久化保存的快照机制叫作“检查点”(Checkpoint)。于是使用算子状态时,就需要对检查点的相关操作进行定义,实现一个 CheckpointedFunction 接口。
public interface CheckpointedFunction {
// 保存状态快照到检查点时,调用这个方法
void snapshotState(FunctionSnapshotContext context) throws Exception
// 初始化状态时调用这个方法,也会在恢复状态时调用
void initializeState(FunctionInitializationContext context) throws
Exception;
}
每次应用保存检查点做快照时,都会调用.snapshotState()方法,将状态进行外部持久化。而在算子任务进行初始化时,会调用. initializeState()方法。
使用算子状态去做数据缓存输出的例子
package com.atguigu.chapter09;
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import java.security.PublicKey;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
public class BufferingSinkExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
}));
stream.print("data");
// 批量缓存输出
stream.addSink(new BufferingSink(10));
env.execute();
}
/// 自定义实现SinkFunction
public static class BufferingSink implements SinkFunction<Event>, CheckpointedFunction {
//定义当前类的属性
private final int threshold;
public BufferingSink(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
// 必须作为算子状态保存起来,才能持久化到磁盘,写入到检查点中
private List<Event> bufferedElements;
// 定义一个算子状态
private ListState<Event> checkpointedState;
@Override
public void invoke(Event value, Context context) throws Exception {
bufferedElements.add(value); // 缓存到列表
// 判断如果达到阈值就批量写入
if(bufferedElements.size() == threshold){
// 用打印到控制台模拟写入外部系统
for (Event element : bufferedElements) {
System.out.println(element);
}
System.out.println("==============输出完毕==============");
bufferedElements.clear();
}
}
@Override
public void snapshotState(FunctionSnapshotContext functionSnapshotContext) throws Exception {
// 清空状态
checkpointedState.clear();
// 对状态进行持久化,复制缓存的列表 到 列表状态
for (Event bufferedElement : bufferedElements) {
checkpointedState.add(bufferedElement );
}
}
@Override
public void initializeState(FunctionInitializationContext functionInitializationContext) throws Exception {
// 定义算子状态
ListStateDescriptor<Event> eventListStateDescriptor = new ListStateDescriptor<>("buffered-elements", Event.class);
checkpointedState = functionInitializationContext.getOperatorStateStore().getListState(eventListStateDescriptor);
// 如果从故障恢复,需要将ListState中所有元素复制到 本地列表中
if( functionInitializationContext.isRestored()){
for (Event element : checkpointedState.get()) {
bufferedElements.add(element);
}
}
}
}
}
9.4 广播状态(Broadcast State)
算子状态中有一类很特殊,就是广播状态(Broadcast State)。从概念和原理上讲,广播状态非常容易理解:状态广播出去,所有并行子任务的状态都是相同的;并行度调整时只要直接复制就可以了。然而在应用上,广播状态却与其他算子状态大不相同。
9.4.1 基本用法
一个最为普遍的应用,就是“动态配置”或者“动态规则”。我们在处理流数据时,有时会基于一些配置(configuration)或者规则(rule)。
我们可以将这动态的配置数据看作一条流,将这条流和本身要处理的数据流进行连接(connect),就可以实时地更新配置进行计算了。
在代码上,可以直接调用 DataStream 的.broadcast()方法,传入一个“映射状态描述器”(MapStateDescriptor)说明状态的名称和类型,就可以得到一个“广播流”(BroadcastStream);进而将要处理的数据流与这条广播流进行连接(connect),就会得到“广播连接流”(BroadcastConnectedStream)。注意广播状态只能用在广播连接流中。
9.4.2 代码实例
接下来我们举一个广播状态的应用案例。考虑在电商应用中,往往需要判断用户先后发生的行为的“组合模式”,比如“登录-下单”或者“登录-支付”,检测出这些连续的行为进行统计,就可以了解平台的运用状况以及用户的行为习惯。
package com.atguigu.chapter09;
import org.apache.flink.api.common.state.*;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.KeyedBroadcastProcessFunction;
import org.apache.flink.util.Collector;
public class BehaviorPatterDetecExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 用户的行为数据流
DataStreamSource<Action> actionStream = env.fromElements(
new Action("Alice", "login"),
new Action("Alice", "pay"),
new Action("Bob", "login"),
new Action("Bob", "order")
);
// 行为模式流, 基于它构建广播流
DataStreamSource<Pattern> patternStream = env.fromElements(
new Pattern("login", "pay"),
new Pattern("login", "order")
);
//定义广播状态描述器
MapStateDescriptor<Void, Pattern> descriptor = new MapStateDescriptor<>("pattern", Types.VOID, Types.POJO(Pattern.class));
BroadcastStream<Pattern> broadcastStream = patternStream.broadcast(descriptor);
// 连接两条流进行处理
SingleOutputStreamOperator<Tuple2<String, Pattern>> matches = actionStream.keyBy(data -> data.userId)
.connect(broadcastStream)
.process(new PatternDetector());
matches.print();
env.execute();
}
// 实现自定义的 keyedBroadCastProcessFunction
public static class PatternDetector extends KeyedBroadcastProcessFunction<String, Action, Pattern, Tuple2<String, Pattern>>{
// 定义一个KeyedState,保存上一次用户的行为
ValueState<String> prevActionState;
@Override
public void open(Configuration parameters) throws Exception {
prevActionState = getRuntimeContext().getState(new ValueStateDescriptor<String>("last-action",String.class));
}
@Override
public void processElement(Action action, KeyedBroadcastProcessFunction<String, Action, Pattern, Tuple2<String, Pattern>>.ReadOnlyContext readOnlyContext, Collector<Tuple2<String, Pattern>> collector) throws Exception {
// 从广播状态中,获取匹配模式
ReadOnlyBroadcastState<Void, Pattern> patternState = readOnlyContext.getBroadcastState(new MapStateDescriptor<>("pattern", Types.VOID, Types.POJO(Pattern.class)));
Pattern pattern = patternState.get(null);
// 获取用户上一次的行为
String prevAction = prevActionState.value();
if(pattern != null && prevAction != null){
if(pattern.action1.equals(prevAction) && pattern.action2.equals(action.action)){
collector.collect(new Tuple2<>(readOnlyContext.getCurrentKey(), pattern));
}
}
// 更新状态
prevActionState.update(action.action);
}
@Override
public void processBroadcastElement(Pattern pattern, KeyedBroadcastProcessFunction<String, Action, Pattern, Tuple2<String, Pattern>>.Context context, Collector<Tuple2<String, Pattern>> collector) throws Exception {
// 从上下文中获取广播状态,并用当前数据更新状态
BroadcastState<Void, Pattern> patternState = context.getBroadcastState(new MapStateDescriptor<>("pattern", Types.VOID, Types.POJO(Pattern.class)));
patternState.put(null, pattern);
}
}
// 定义用户行为事件和模式的pojo类
public static class Action{
public String userId;
public String action;
public Action() {
}
public Action(String userId, String action) {
this.userId = userId;
this.action = action;
}
@Override
public String toString() {
return "Action{" +
"userId='" + userId + '\'' +
", action='" + action + '\'' +
'}';
}
}
public static class Pattern{
public String action1;
public String action2;
public Pattern() {
}
public Pattern(String action1, String action2) {
this.action1 = action1;
this.action2 = action2;
}
@Override
public String toString() {
return "Pattern{" +
"action1='" + action1 + '\'' +
", action2='" + action2 + '\'' +
'}';
}
}
}
9.5 状态持久化和状态后端
对状态进行持久化(persistence)保存,这样就可以在发生故障后进行重启恢复。Flink 对状态进行持久化的方式,就是将当前所有分布式状态进行“快照”保存,写入一个“检查点”(checkpoint)或者保存点(savepoint)保存到外部存储系统中。
9.5.1 检查点(Checkpoint)
有状态流应用中的检查点(checkpoint),其实就是所有任务的状态在某个时间点的一个快照(一份拷贝)。
如果保存检查点之后又处理了一些数据,然后发生了故障,那么重启恢复状态之后这些数据带来的状态改变会丢失。为了让最终处理结果正确,我们还需要让源(Source)算子重新读取这些数据,再次处理一遍。这就需要流的数据源具有“数据重放”的能力,一个典型的例子就是 Kafka,我们可以通过保存消费数据的偏移量、故障重启后重新提交来实现数据的重放。
这是对“至少一次”(at least once)状态一致性的保证,如果希望实现“精确一次”(exactly once)的一致性,还需要数据写入外部系统时的相关保证。
默认情况下,检查点是被禁用的,需要在代码中手动开启。直接调用执行环境的.enableCheckpointing()方法就可以开启检查点。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getEnvironment();
env.enableCheckpointing(1000);
这里传入的参数是检查点的间隔时间,单位为毫秒。
9.5.2 状态后端(State Backends)
检查点的保存离不开 JobManager 和 TaskManager,以及外部存储系统的协调。在应用进行检查点保存时,首先会由 JobManager 向所有 TaskManager 发出触发检查点的命令;TaskManger 收到之后,将当前任务的所有状态进行快照保存,持久化到远程的存储介质中;完成之后向 JobManager 返回确认信息。这个过程是分布式的,当 JobManger 收到所有TaskManager 的返回信息后,就会确认当前检查点成功保存,如图 9-5 所示。而这一切工作的协调,就需要一个“专职人员”来完成。
1. 状态后端的分类
状态后端是一个“开箱即用”的组件,可以在不改变应用程序逻辑的情况下独立配置。
Flink 中提供了两类不同的状态后端,一种是“哈希表状态后端”(HashMapStateBackend),另一种是“内嵌 RocksDB 状态后端”(EmbeddedRocksDBStateBackend)。如果没有特别配置,系统默认的状态后端是 HashMapStateBackend。
(1)哈希表状态后端(HashMapStateBackend)
这种方式就是我们之前所说的,把状态存放在内存里。具体实现上,哈希表状态后端在内部会直接把状态当作对象(objects),保存在Taskmanager 的 JVM 堆(heap)上。普通的状态,以及窗口中收集的数据和触发器(triggers),都会以键值对(key-value)的形式存储起来,所以底层是一个哈希表(HashMap),这种状态后端也因此得名。
对于检查点的保存,一般是放在持久化的分布式文件系统(file system)中,也可以通过配置“检查点存储”(CheckpointStorage)来另外指定。
HashMapStateBackend 是将本地状态全部放入内存的,这样可以获得最快的读写速度,使计算性能达到最佳;代价则是内存的占用。它适用于具有大状态、长窗口、大键值状态的作业,对所有高可用性设置也是有效的。
(2)内嵌 RocksDB 状态后端(EmbeddedRocksDBStateBackend)
RocksDB 是一种内嵌的 key-value 存储介质,可以把数据持久化到本地硬盘。配置EmbeddedRocksDBStateBackend 后,会将处理中的数据全部放入 RocksDB 数据库中,RocksDB默认存储在 TaskManager 的本地数据目录里。
由于它会把状态数据落盘,而且支持增量化的检查点,所以在状态非常大、窗口非常长、键/值状态很大的应用场景中是一个好选择,同样对所有高可用性设置有效。
2. 如何选择正确的状态后端
HashMap 和 RocksDB 两种状态后端最大的区别,就在于本地状态存放在哪里:前者是内存,后者是 RocksDB。在实际应用中,选择那种状态后端,主要是需要根据业务需求在处理性能和应用的扩展性上做一个选择。
HashMapStateBackend 是内存计算,读写速度非常快;但是,状态的大小会受到集群可用内存的限制,如果应用的状态随着时间不停地增长,就会耗尽内存资源。
而 RocksDB 是硬盘存储,所以可以根据可用的磁盘空间进行扩展,而且是唯一支持增量检查点的状态后端,所以它非常适合于超级海量状态的存储。不过由于每个状态的读写都需要做序列化/反序列化,而且可能需要直接从磁盘读取数据,这就会导致性能的降低,平均读写性能要比 HashMapStateBackend 慢一个数量级。
3. 状态后端的配置
在不做配置的时候,应用程序使用的默认状态后端是由集群配置文件 flink-conf.yaml 中指定的,配置的键名称为 state.backend。这个默认配置对集群上运行的所有作业都有效,我们可以通过更改配置值来改变默认的状态后端。另外,我们还可以在代码中为当前作业单独配置状态后端,这个配置会覆盖掉集群配置文件的默认值。
(1)配置默认的状态后端
在 flink-conf.yaml 中,可以使用 state.backend 来配置默认状态后端。
配置项的可能值为 hashmap,这样配置的就是 HashMapStateBackend;也可以是 rocksdb,这样配置的就是 EmbeddedRocksDBStateBackend。另外,也可以是一个实现了状态后端工厂StateBackendFactory 的类的完全限定类名。
下面是一个配置 HashMapStateBackend 的例子:
# 默认状态后端
state.backend: hashmap
# 存放检查点的文件路径
state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints
(2)为每个作业(Per-job)单独配置状态后端
每个作业独立的状态后端,可以在代码中,基于作业的执行环境直接设置。代码如下:
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new HashMapStateBackend());
上面代码设置的是 HashMapStateBackend,如果想要设置EmbeddedRocksDBStateBackend,可以用下面的配置方式:
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new EmbeddedRocksDBStateBackend());
需要注意,如果想在 IDE 中使用 EmbeddedRocksDBStateBackend,需要为 Flink 项目添加依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId>
<version>1.13.0</version>
</dependency>
而由于 Flink 发行版中默认就包含了 RocksDB,所以只要我们的代码中没有使用 RocksDB的相关内容,就不需要引入这个依赖。即使我们在 flink-conf.yaml 配置文件中设定了state.backend 为 rocksdb,也可以直接正常运行,并且使用 RocksDB 作为状态后端。















 1927
1927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









