







 本文探讨阿里云伏羲计算平台如何在SortBenchmark中取得优异成绩,重点分析了流水线策略、IO双buffer和NetWork Shuffle等关键技术。NetWork Shuffle通过将排序工作移至reduce端,减少了map端的磁盘IO和多路归并,从而提高整体性能。然而,这种优化可能增加资源依赖和容错性的挑战。
本文探讨阿里云伏羲计算平台如何在SortBenchmark中取得优异成绩,重点分析了流水线策略、IO双buffer和NetWork Shuffle等关键技术。NetWork Shuffle通过将排序工作移至reduce端,减少了map端的磁盘IO和多路归并,从而提高整体性能。然而,这种优化可能增加资源依赖和容错性的挑战。
看到了阿里云伏羲计算平台获得了sortbenchmark冠军,并且是投入使用版(Daytona)和内部实验版(Indy)双冠,为国内的云计算事业感到自豪,详情见http://sortbenchmark.org/FuxiSort2015.pdf 。
那么为什么伏羲计算框架在排序可以达到这么快的速度,究竟在哪里做了哪些优化呢,在文中提到了流水线策略、IO双buffer、NetWork Shuffle等优化点。
看了这些优化点,还是可以略知一二的,比如IO双buffer,很显然的作用就是加快了读写速度,让task在读写数据时的速度加快。那么NetWork Shuffle呢?这个是什么意思呢?下面会针对NetWork Shuffle进行较为详细的分析。
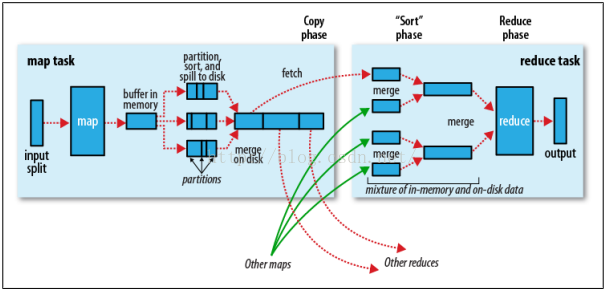
首先我们需要了解什么是shuffle。先来看一张Hadoop的架构图。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2543
2543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









