







 本文介绍了使用Python进行网页爬虫的实践经验,以搜狗壁纸为例,详细阐述了如何找到动态加载图片的真实URL,通过调试和分析网络请求,成功实现了批量下载图片的目标。爬虫的关键在于确定正确的数据源,并逐步调试代码确保每个步骤的准确性。
本文介绍了使用Python进行网页爬虫的实践经验,以搜狗壁纸为例,详细阐述了如何找到动态加载图片的真实URL,通过调试和分析网络请求,成功实现了批量下载图片的目标。爬虫的关键在于确定正确的数据源,并逐步调试代码确保每个步骤的准确性。
最近几天,研究了一下一直很好奇的爬虫算法。这里写一下最近几天的点点心得。下面进入正文:
你可能需要的工作环境:
Python 3.9官网下载
我们这里以sogou作为爬取的对象。
首先我们进入搜狗图片https://pic.sogou.com/,进入壁纸分类(当然只是个例子Q_Q),因为如果需要爬取某网站资料,那么就要初步的了解它… 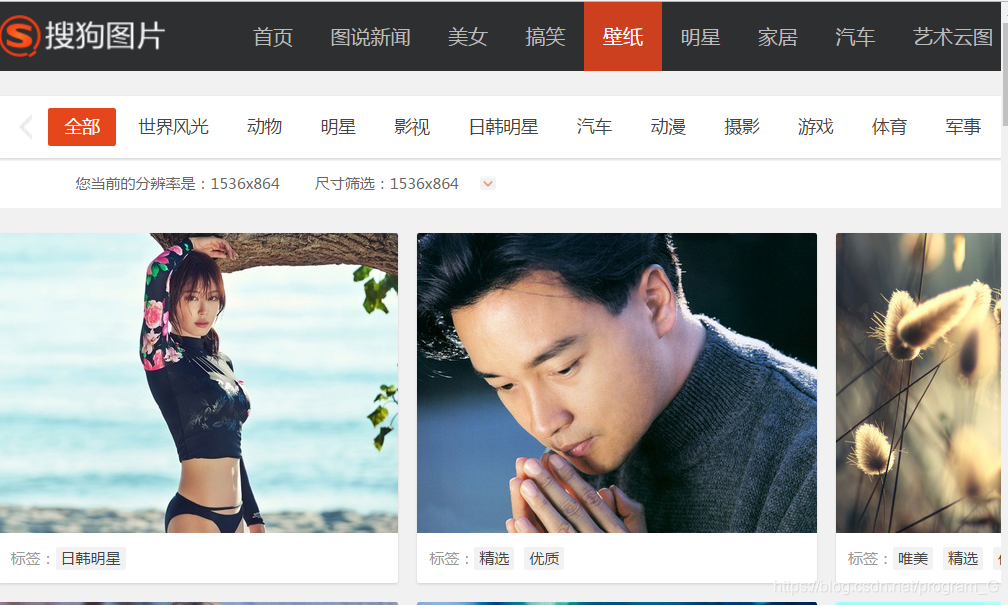
进去后就是这个啦,然后F12进入开发人员选项,笔者用的是Chrome。
右键图片>>检查
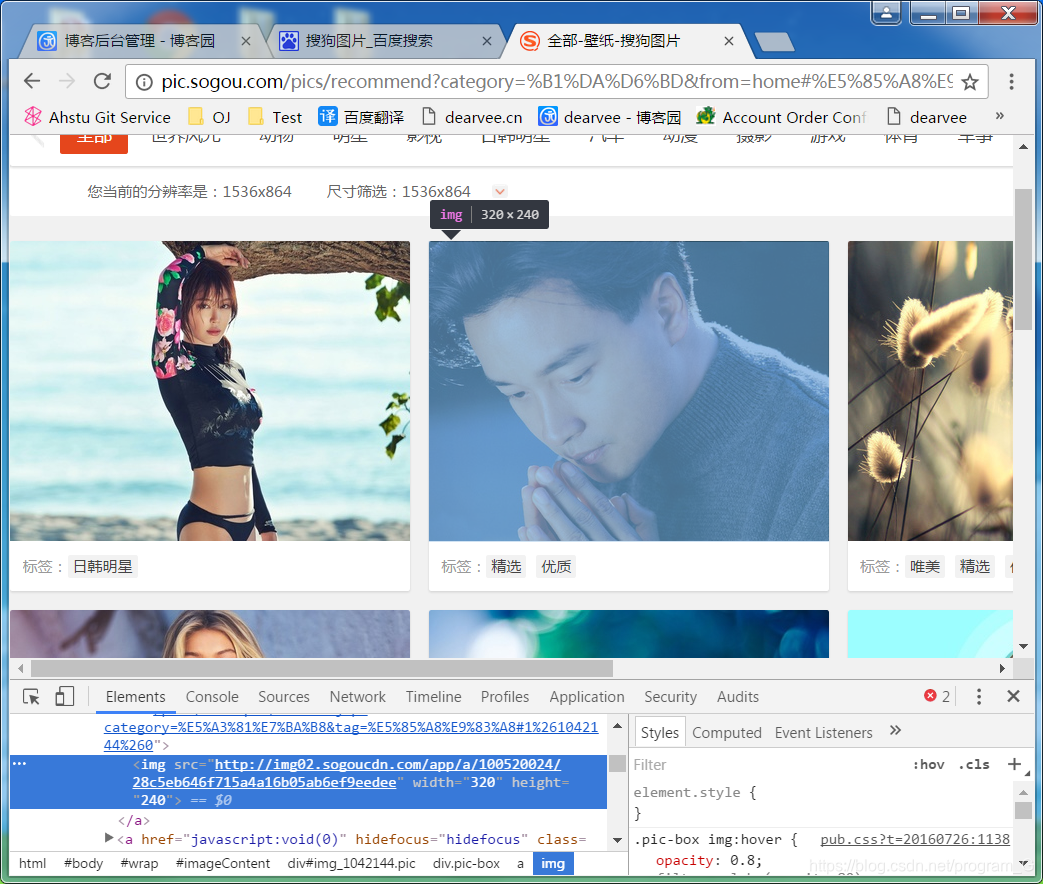
发现我们需要的图片src是在img标签下的,于是先试着用 Python 的 requests提取该组件,进而获取img的src然后使用urllib.request.urlretrieve逐个下载图片,从而达到批量获取资料的目的,思路好了;
下面应该告诉程序要爬取的url为http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD,此url来自进入分类后的地址栏。明白了url地址我们来开始愉快的代码时间吧:
在写这段爬虫程序的时候,最好要逐步调试,确保我们的每一步操作正确,这也是程序猿应该有的好习惯。下面我们来剖析该url指向的网页。
import requests
import urllib
from bs4 import BeautifulSoup
res = requests.get('http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD')
soup = BeautifulSoup 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









