







索引内容比较多,一次性学不完就分批记录吧.
说起优化sql,很多人第一反应就是添加索引,那索引到底是什么,为什么能优化sql? 这也是我学习索引的目的.
概念: 索引是协助快速查询,更新数据库表中数据的有序的数据结构.
Mysql的数据模型:
这也是我今天学习的重点,我一直认为想对一项技术了解的更深入,不妨从它为什么被创造,解决了哪些问题开始了解.
先从有序数组,链表结构说起,这两种结构是我们常见的.
有序数组,如ArrayList,特点是查找快,增删慢,链表结构,如LinkedLisr,特点是增删快,查找慢,相信很多人都背过这个.
ArrayList为什么查询快呢? 因为它可以通过索引快速定位元素位置,从而查找出来.
而针对大量数据查找,如何快速定位数据位置呢?相信很多人都知道,就是二分法.
因此有了二叉查找树模型
二叉查找树: 特点是左子树的节点 < 父节点,右子树的节点 > 父节点,这样一来需要查询的索引值大于父节点时我直接从右子树开始查询即可,实现快速查找.但二叉查找树存在一个问题,当所有数据都比父节点大(小)时,树结构会只有右(左)侧,导致树结构不平衡,看起来像链表结构,这样一来,查找起来依然很慢了.

为了解决斜树的问题,所以有了平衡二叉树(AVL树)
平衡二叉树(AVL树): 特点是左右子树深度差绝对值不能超过1,当两侧深度绝对值 大于1时,会进行旋转操作,将中间值提升为父节点.
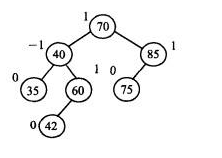
每个节点存储了键值,数据磁盘地址以及子节点的引用.
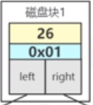
平衡二叉树也存在一些问题,每个节点存储的数据较少,而每访问一次树节点会进行一次I/O操作,而节点数据较少的情况下I/O的效率是非常低的,更不幸的是如果查询的数据在最深的节点,I/O操作非常频繁,既浪费了空间也浪费了效率.
上述问题依然有解决方案,就是多路平衡查找树(BTree)
多路平衡查找树(Btree): 每个节点可以拥有多个键值及子树,子树数量叫做度,将空间利用更大化,同时因为空间的压缩,树的深度也会减少,I/O操作也会降低很多.

而Mysql使用的数据模型则是BTree的升级版,B+Tree.
B+tree:

从图中可以看到几点:
关键字数等于度数,只有叶子节点会存储数据,且叶子节点之间数据有序排列,同时还有指针指向下一节点,形成链表结构.
在区间查询时,当查询完第一次后无需重新回到父节点再次查询,可以直接通过叶子节点的有序链表查询后面的数据,因此I/O操作更少一些,同时更加稳定.
今日学习就这么多,明天再更新.
--------------------------------------------------------------更新----------------------------------------------------------------
Mysql中存储引擎索引如何落地?
主要说Myisam和InnoDB.
首先可以进入默认的数据目录/var/lib/mysql中
会发现有以下几个文件

先说Myisam:
其中MYI和MYD就是Myisam存储数据的方式.MYI是索引文件,MYD是数据文件.而在通过索引查询数据时,会先查找到MYI,找到键值对应的数据的磁盘地址,然后通过磁盘地址从MYD文件找到对应的数据.

InnoDB:
聚集索引: 是指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以,对应的聚集索引只能有一个。如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度。
InnoDB中只有idb文件,以主键作为索引来组织数据的存储,在InnoDB中只有主键是聚集索引,其他字段都是非聚集索引,而当表中未定义主键时,InnoDB将第一个没有NULL值唯一列作为索引,如果还是没有,会使用隐藏的ROWID作为索引.

在InnoDB中,除了主键索引外,也存在一些辅助索引,而辅助索引并不会直接存储对应的数据,而是存储了索引和主键值,当通过辅助索引查询数据的时候,也会先查出主键值,然后通过主键值查询出对应的数据.

Mysql索引使用原则
索引虽然能大大提高查询效率,但并不是所有字段都要添加索引的,这样只会白白增加大量的消耗.
离散度公式: count(distinct(column_name)):count(*)
count(distinct(column_name))表示该列不同的值,例如 count(distinct(gender)) 而gender只有男,女两个值,用0,1表示.
当一列数据重复值越多,它的离散度就越低,也越不适合作为索引,离散度越高的列更适合作为索引.
添加索引: ALTER TABLE 表名 ADD INDEX 索引名(字段名); 给某个字段添加索引
可通过explain [查询语句] , rows列代表预估要查询的数据条数,.
联合索引:
添加联合索引: ALTER TABLE 表名 ADD INDEX 索引名(字段名1,字段名2);
最左匹配原则:
例: ALTER TABLE 表名 ADD INDEX 索引名(name,phone);
name字段在前,因此在创建B+tree结构时,name字段也是在前面的

仔细观察也会发现,即使是name字段也是有序排列的,当左边字段相同时,才会将phone字段进行排序
而在使用联合索引时,必须要将最左字段作为查询条件,否则联合索引无效.
覆盖索引:
需要查询的字段包含在了索引中即为覆盖索引.
举个例子:
ALTER TABLE 表名 ADD INDEX 索引名(name,phone); // 给name和phone添加索引
select name,phone from user where name = ‘programmer_hard’; //查询我的姓名,电话
此时需要查询的字段都包含在了索引中,这就是覆盖索引. 但是这有什么意义呢?
可以先说说回表的概念:
回表: 上面提到过当我们在使用辅助索引查询数据时,会先扫描辅助索引的B+tree,然后根据扫描出的主键值去扫描主键索引,而扫描两次B+Tree的操作就叫做回表,主键索引查询是无需回表的.
而覆盖索引也是无需回表的,可直接查询出数据. 这也是为什么我们常说在为什么查询时尽量只查询我们需要的字段原因.
索引下推:
索引下推是主要针对,辅助索引的功能.
开启方式: set optimizer_switch = “index_condition_pushdown = on”
至于有什么作用举例说明,
例:
select * from user where last_name = “wang” and first_name like “%zi”;
其中last_name 和first_name 都为索引
我们都知道,当使用like关键字时,%在前面索引是无效的,因此这个sql语句where后面第一个条件是符合索引查询,第二个条件是不符合的,这样会产生什么问题呢?
在前面的文章我提到过,Mysql的架构可分为连接层,服务层,存储引擎层三层.
数据是存储在存储引擎中的,而这条sql语句中先会从存储引擎中查询到所有姓王的用户,然后在server层进行过滤名字以zi结尾的用户 ,而如果在一张表中,姓王的人有100W个,而名字是以zi结尾的只有1个,这样会导致sever层的工作量会很大.
而通过索引下推操作会直接将第二个条件下推到存储引擎层执行.
OVER















 1784
1784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









