







 本文介绍了如何解决力扣平台上关于查找字符串数组中最长公共前缀的问题,涉及横向搜索、纵向搜索、分治法和二分查找的解法,以及性能优化的过程。
本文介绍了如何解决力扣平台上关于查找字符串数组中最长公共前缀的问题,涉及横向搜索、纵向搜索、分治法和二分查找的解法,以及性能优化的过程。
「力扣」14. 最长公共前缀
题目描述
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入: strs = ["flower","flow","flight"]
输出: "fl"
示例 2:
输入: strs = ["dog","racecar","car"]
输出: ""
解释: 输入不存在公共前缀。
提示:
1 <= strs.length <= 2000 <= strs[i].length <= 200strs[i]仅由小写英文字母组成
题解
解法1(横向搜索)
可以先求两个字符串的最大公共前缀,然后在将计算结果与后面的字符串再求最大公共前缀,以此类推,如下图所示:
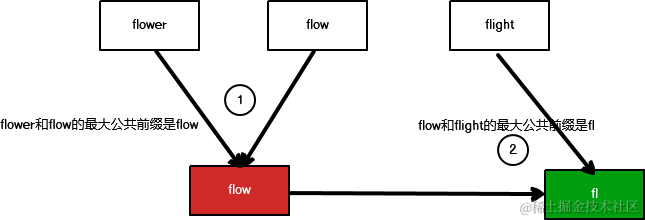
字符串数组是:[“flower”,“flow”,“flight”],先求flower和flow的最大公共前缀,结果是flow(图中红色部分),然后再用这个计算结果flow与字符串数组后面的flight计算最大公共前缀,得到结果fl(图中绿色部分)。
代码如下:
class Solution {
public String longestCommonPrefix(String[] strs) {
String lcp = strs[0];
for (int i = 1; i < strs.length; i++) {
lcp = longestCommonPrefix(lcp, strs[i]);
}
return lcp;
}
private String longestCommonPrefix(String s1, String s2) {
char[] s1Array = s1.toCharArray();
char[] s2Array = s2.toCharArray();
String ans = "";
for (int i = 0; i < Integer.min(s1Array.length, s2Array.length); i++) {
if (s1Array[i] == s2Array[i]) {
ans += s1Array[i];
} else {
break;
}
}
return ans;
}
}
提交结果如下:
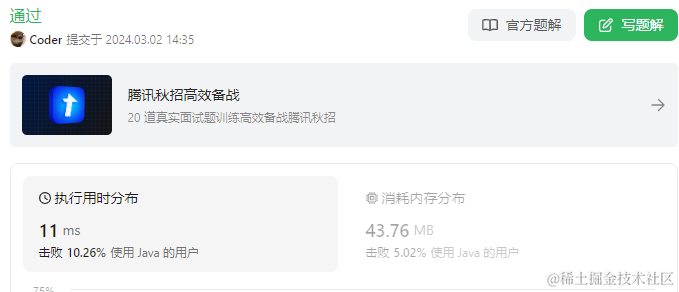
执行时间只击败了10.26%的java用户,内存43.76M,只击败了5.02%的java用户,写的这么烂吗?烂在哪里了?内存使用过高?
char[] s1Array = s1.toCharArray(); char[] s2Array = s2.toCharArray(); 这里不转化为数组可能会好一点, 修改代码如下:
class Solution {
public String longestCommonPrefix(String[] strs) {
String lcp = strs[0];
for (int i = 1; i < strs.length; i++) {
lcp = longestCommonPrefix(lcp, strs[i]);
}
return lcp;
}
private String longestCommonPrefix(String s1, String s2) {
String ans = "";
for (int i = 0; i < Integer.min(s1.length(), s2.length()); i++) {
char c1 = s1.charAt(i);
char c2 = s2.charAt(i);
if (c1 == c2) {
ans += c1;
} else {
break;
}
}
return ans;
}
}
提交:
额,没啥效果。
难道是多次字符串拼接导致的运行时间长?可以只计算索引,最后截取字符串。
class Solution {
public String longestCommonPrefix(String[] strs) {
String lcp = strs[0];
for (int i = 1; i < strs.length; i++) {
lcp = longestCommonPrefix(lcp, strs[i]);
}
return lcp;
}
private String longestCommonPrefix(String s1, String s2) {
int index = 0;
for (int i = 0; i < Integer.min(s1.length(), s2.length()); i++) {
char c1 = s1.charAt(i);
char c2 = s2.charAt(i);
if (c1 == c2) {
index++;
} else {
break;
}
}
return s1.substring(0, index);
}
}
提交结果:
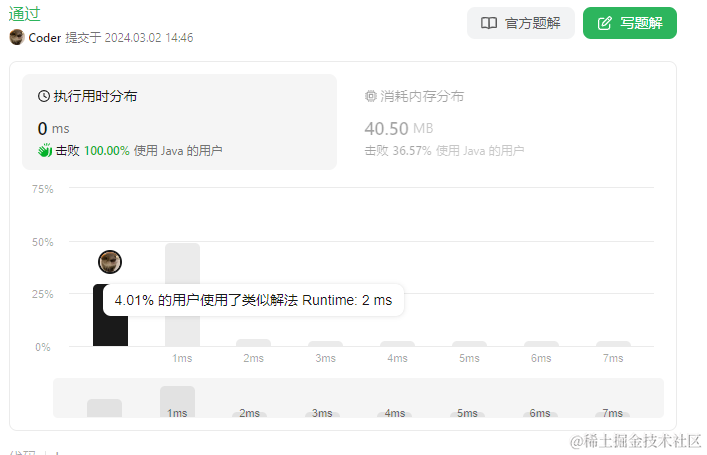
oh yeah! 击败了100%的用户,内存使用也更少了。
时间复杂度是
O(mn),m是字符串数组中的字符串的平均长度,n是字符串的数量,空间复杂度是O(1),因为没有额外开辟空间。
解法2(纵向搜索)
还有一种解法是,数组中每个字符串按照位置一一比较,比如所有字符串0位置处是否相等,如果相等,继续比较所有后续位置,如果出现不相等,则对比结束,会得到最大公共前缀。
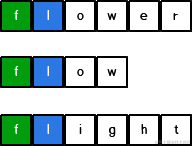
如图所有绿色的相等,然后所有蓝色的相等,后面不相等则结束比较。
代码如下:
class Solution {
public String longestCommonPrefix(String[] strs) {
String first = strs[0];
for (int i = 0; i < first.length(); i++) {
char c = strs[0].charAt(i); // 第一个字母,第i个位置的字符
for (int j = 1; j < strs.length; j++) {
if (i == strs[j].length() || c != strs[j].charAt(i)) {
return strs[0].substring(0, i);
}
}
}
return strs[0];
}
}
提交:
这里要考虑字符串长度不一样的问题,
i == strs[j].length()就是说如果达到了字符串的长度,那么就直接返回即可。
空间复杂度和时间复杂度跟解法1是一样的。
运行时间击败了70.07%的java用户,内存使用击败了67.59%用户,也不是很好呀,还有更好的解法吗?想了半天我也没想出来,看了下力扣的题解,看到了分治法和二分查找法。
解法3(分治法)
没想到分治算法,看了题解才知道,分治算法的思想很简单,就是将数据分片,单独计算,然后合并结果,如下图所示:
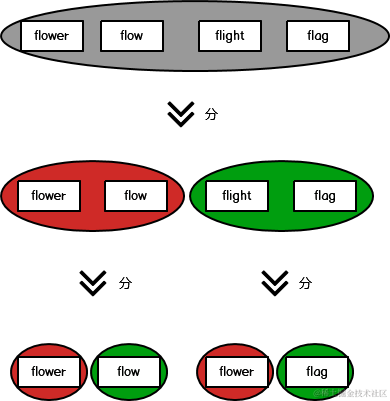
正如上图所示,将数据层层切分,当在最下层的时候开始计算左右两个字符串的最大公共前缀,以此类推,逐层向上计算,这也是递归的思想,先“递”后“归”,代码如下:
class Solution {
public String longestCommonPrefix(String[] strs) {
// 开始的时候传递整个数组
return longestCommonPrefix(strs, 0, strs.length - 1);
}
public String longestCommonPrefix(String[] strs, int start, int end) {
// 当start=end的时候,说明数字只有一个元素,一个元素的最大公共前缀就是它自己
if (start == end) {
return strs[start];
}
// 每次将数组拆分一半
int mid = (end - start) / 2 + start;
// 递归获取左边的最大公共前缀
String lcpLeft = longestCommonPrefix(strs, start, mid);
// 递归获取右边的最大公共前缀
String lcpRight = longestCommonPrefix(strs, mid + 1, end);
// 计算左右两个最大公共前后缀的最大公共前后缀
return commonPrefix(lcpLeft, lcpRight);
}
public String commonPrefix(String lcpLeft, String lcpRight) {
int minLength = Math.min(lcpLeft.length(), lcpRight.length());
for (int i = 0; i < minLength; i++) {
if (lcpLeft.charAt(i) != lcpRight.charAt(i)) {
return lcpLeft.substring(0, i);
}
}
return lcpLeft.substring(0, minLength);
}
}
提交到力扣:
时间上击败了
100%的java用户,空间复杂度上击败了50.28%的用户,从结果上看确实是性能提升了,时间复杂度依然是O(mn),m是字符串数组中的字符串的平均长度,n是字符串的数量,空间复杂度是O(mlogn),空间复杂度主要取决于递归调用的层数,层数最大为logn,每层需要m的空间存储返回结果。
解法4(二分查找法)
二分查找法我也是没有想到,看了官方的解释才明白,具体什么意思呢?看如下说明:
要知道一点,最大公共前缀的长度一定是小于所有字符串中最小长度。
比如:

最小长度是minLength=4,那么最大公共前缀的长度一定是[0, minLength],所有可以通过[0, minLength]来实现二分查找,代码如下:
class Solution {
public String longestCommonPrefix(String[] strs) {
// 首先要找出最小长度值minLength
int minLength = Integer.MAX_VALUE;
for (String str : strs) {
minLength = Integer.min(minLength, str.length());
}
// 二分查找
int left = 0;
int right = minLength - 1;
while (left <= right) {
int mid = (left + right) >> 1;
if (isCommonPrefix(strs, mid + 1)) { // mid + 1是长度,也就是计算[0-mid]这个字符串。
left = mid + 1;
} else {
right = mid - 1;
}
}
return strs[0].substring(0, left);
}
public boolean isCommonPrefix(String[] strs, int length) {
String str0 = strs[0].substring(0, length);
int count = strs.length;
for (int i = 1; i < count; i++) {
String str = strs[i];
for (int j = 0; j < length; j++) {
if (str0.charAt(j) != str.charAt(j)) {
return false;
}
}
}
return true;
}
}
提交结果如下:
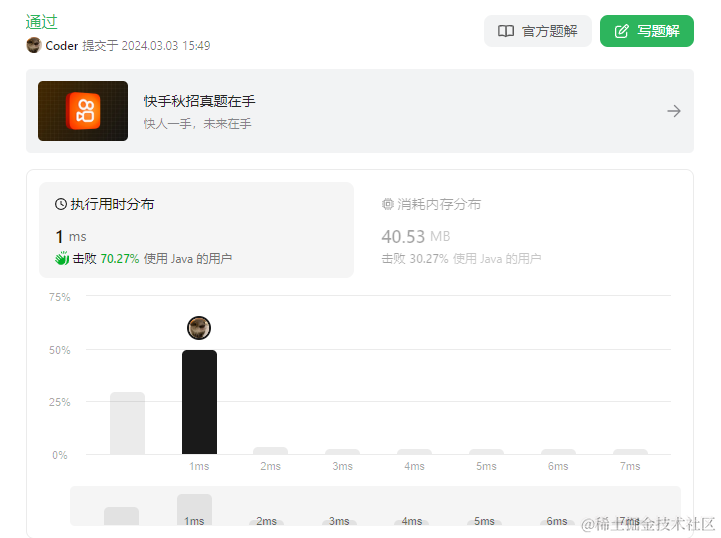
时间上击败了
70.27%的java用户,内存消耗上则击败了30.27%的java用户。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









