







北京市丰台区新发地是一个商品批发市场品牌称号。北京有两家市场使用了该称号,一是北京新发地农产品中心批发市场。二是北京新发地国际水产城。
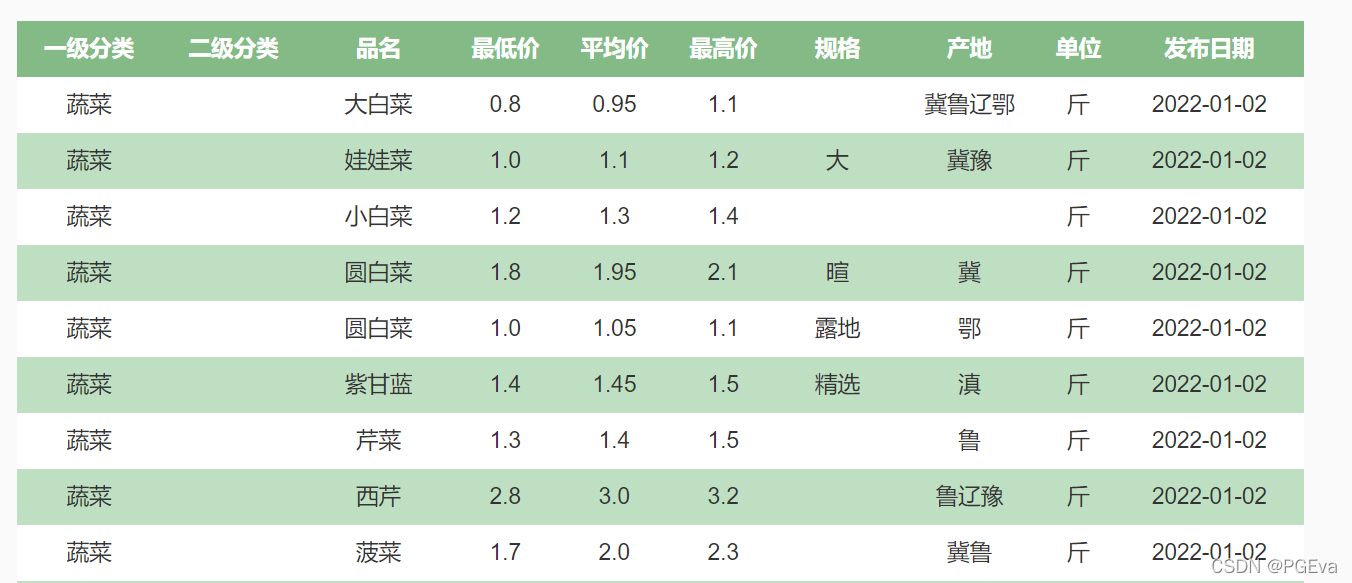
我们查看网页源代码发现,其表格中的数据来自后台的post请求。
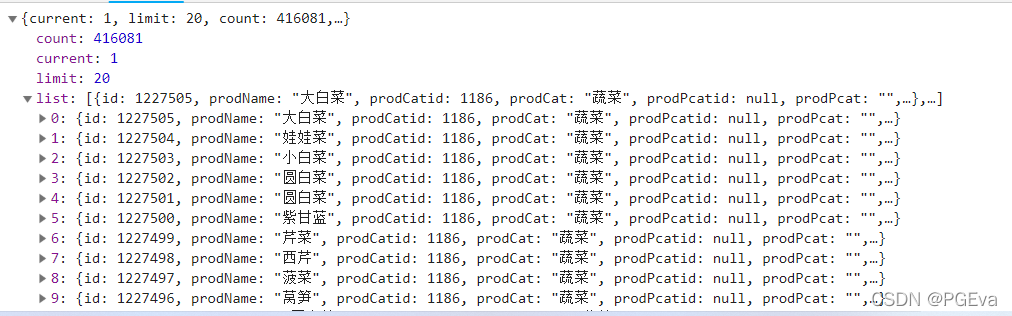
遂爬取之,代码如下:
import requests
import csv
url = "http://www.xinfadi.com.cn/getPriceData.html"
dic = {
"limit": "",
"current": "",
"pubDateStartTime": "",
"pubDateEndTime": "",
"prodPcatid": "",
"prodCatid": "",
"prodName": "",
}
r1 = requests.post(url, data=dic)
resp = r1.json()
print(resp)
all_count = int(resp["count"])
limit = int(resp["limit"])
all_page_number = int(all_count / limit)
with open("新发地菜价.csv", mode="a+", newline='') as f:
csvwriter = csv.writer(f)
for i in range(1, all_page_number):
dic1 = {
"limit": limit,
"current": i,
"pubDateStartTime": "",
"pubDateEndTime": "",
"prodPcatid": "",
"prodCatid": "",
"prodName": "",
}
r1 = requests.post(url, data=dic)
list = resp["list"]
count = list
for iter in list:
prodName = iter["prodName"]
avgPrice = iter["avgPrice"]
highPrice = iter["highPrice"]
lowPrice = iter["lowPrice"]
place = iter["place"]
prodCat = iter["prodCat"]
pubDate = iter["pubDate"]
unitInfo = iter["unitInfo"]
csvwriter.writerow([prodName, avgPrice, highPrice, lowPrice, place, prodCat, pubDate, unitInfo])
print("Over")
因为这个数据量比较大 同步爬取的效率会比较低,大概会花费几十分钟时间。结果如下:
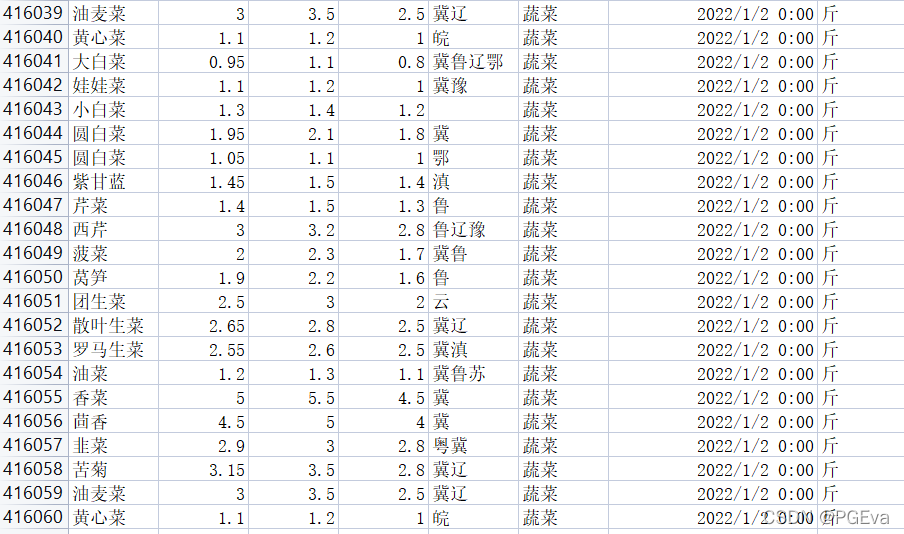














 2043
2043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









