







1.前言
这段日子在用tornado 在sae 上搭建一些东西。tornado这个框架是个很不错的东西,在网上看了很多人的测试报告,在python中的几个框架里,tornado处理相同量的速度是最快的。这就归功于tornado的异步机制了。
不过tornado的异步实现起来并不是那么简单,即使你加@tornado.web.asynchronous 装饰器,然后 yield tornado.gen.Task(xxxxx,x,x),如果你编写的客户端不是异步的,再怎样负荷规范的写代码也不能异步的调用啊。这样假设一个请求有10秒,那你的线程就要阻塞10妙。这种情况相当的严重啊。
根据网上的搜索,终于找到了 celery 这个东西。不过网上对这个东西的教程真是少的可怜,没办法只能通过阅读celery的官方文档自己学习。
2.认识CELERY
2.1 环境搭建
由于我是在tornado中搭建的所以必须要安装两样东西 celery和tornado-celery 。
2.1.1 celery 安装
python easy_install celery
或者
pip install celery
2.12 tornado-celery 安装
tornado-celery 是基于celery的tornado客户端,通过tornado-celery可以将耗时任务加入到任务队列中处理,在celery中创建任务,tornado中就可以像调用AsyncHttpClient一样调用这些任务。
下载地址 https://github.com/mher/tornado-celery
下载解压后
python setup.py install
或者通过pip 和easy_install 的方法安装
2.13 broker(中间人)安装
至于这个中间人,至于安装了有什没用,怎么用?安装好了之后在下面的学习过程中我再详细告诉大家。
不过大家可以先有个大概的了解--celery需要一个解决方案来发送和接收消息,而这个解决方案就是中间人了,既然是中间人那么就应独立分开于Server了。
celer 支持的Broker见下图
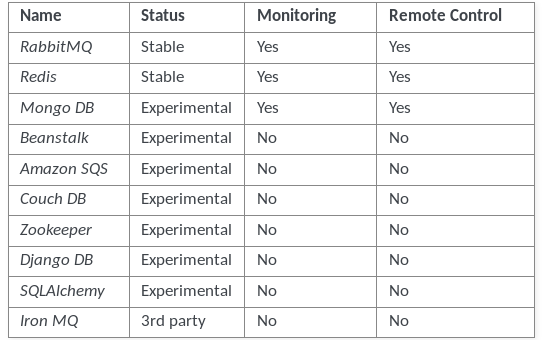
RabbitMQ 是AMPQ高级消息队列协议的实现,也是celer默认的Broker,所以我们再这里就用它了
RabbitMQ安装:
yum install rabbitmq
or
apt-get install rabbitmq安装后要启动它再能有效果,不然你写的程序是连接不到Broker的
sudo rabbitmq-server -detached
2. 窥探 celery
2.1创建celery实例
这个最重要的一步也是第一步,通过这个celery实例我们可以做我们想做的一切。对于小项目我们用单一模块就够了,对于大项目我们要创建一个[专用模块](http://docs.celeryproject.org/en/master/getting-started/next-steps.html#project-layout%20%E4%B8%93%E7%94%A8%E6%A8%A1%E5%9D%97) (我们先看代码再分析)
2.2最简单的Celery代码
tasks.py
from celery import Celery
app = Celery('tasks', broker='amqp://guest@localhost//')
@app.task
def add(x, y):
return x + y2.2.1 分析 :
调用Celery 创建Celery的实例。Celery中要有两个参数,
第一个参数(The first argument to Celery is the name of the current module)是当前模块的名称,
第二个参数是broker 关键字参数指定要使用的消息代理URL,这里是RabbitMQ,也是默认选项。
我们在add()函数前加了装饰器@app.task,表明我们定义了这个任务
2.3启动worker
celery -A tasks worker --loglevel=info
2.4调用task
打开python输入
from tasks import add
add.delay(4, 4)
这里你肯定有疑问了——为什么调用不直接调用add(),反而要调用add.delay().除了delay 还有其他的调用方式麽?
2.5 解开疑问
我们在官方文档中找到了这个:

有三种调用方式。
第一种 例如
add.apply_async(args=[2,2])第二种
add.delay(2,2)其实第一种跟第二种是差不多的。不过唯一的区别在于第二种调用起来更加自由一些。官网说第二种是第一种的捷径,只不过不支持执行选项。
举个例子就可以清楚的对比他们了:
task.delay(arg1, arg2, kwarg1='x', kwarg2='y')
#delay更像是常规的地调用
task.apply_async(args=[arg1, arg2], kwargs={'kwarg1': 'x', 'kwarg2': 'y'})不过经过我的测试使用delay()响应速度更快。
#add.apply_async([4,4])
[2015-05-30 16:49:59,357: INFO/MainProcess] Received task: tasks1.add[8d378500-8b07-40de-b18f-20f003d67225]
[2015-05-30 16:49:59,359: INFO/MainProcess] Task tasks1.add[8d378500-8b07-40de-b18f-20f003d67225] succeeded in 0.000862701999722s: 8
----------------
#add.delay(4,4)
[2015-05-30 16:50:11,748: INFO/MainProcess] Received task: tasks1.add[dfd494c1-d57b-482c-94ab-3b56f05d6879]
[2015-05-30 16:50:11,750: INFO/MainProcess] Task tasks1.add[dfd494c1-d57b-482c-94ab-3b56f05d6879] succeeded in 0.000724498999261s: 8
第三种
add(4,4)直接调用,这样直接调用中间人是不会发送它的,我们打开worker seviec 是不会看见它出现的痕迹的。
PS:一般情况下建议使用apply_async















 4743
4743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









