







大家好,我是crazy_老中医,我写程序就像老中医一样,全屏感觉和经验,但是有用!
废话不多说,现在开始正文,本文将阐述如何将一个Spark程序通过oozie提交到hadoop的Yarn上运行。
准备工作
集群规划
|
| hdp-master | hdp-slave1 | hdp-slave2 |
| hadoop | NameNode DataNode SecondaryNameNode ResourceManager NodeManager | DataNode NodeManager | DataNode NodeManager |
| oozie | Y | N | N |
| spark | Master Worker | Worker | Worker |
hadoop2.6.0
安装路径:
/opt/hadoop-2.6.0
环境变量:
export HADOOP_HOME=/opt/hadoop-2.6.0
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=/opt/hadoop-2.6.0/etc/hadoop
启动hadoop:
$:cd /opt/hadoop-2.6.0
$:./sbin/start-dfs.sh
$:./sbin/start-yarn.sh
启动成功:
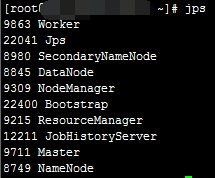
通过jps可看到集群规划中的相关进程。
oozie4.2.0
安装路径:
/opt/oozie-4.2.0
环境变量:
export OOZIE_HOME=/opt/oozie-4.2.0
export PATH=$PATH:$OOZIE_HOME/bin
export PATH=$PATH:$OOZIE_HOME/bin
启动oozie:
$:cd /opt/oozie-4.2.0
$:./bin/oozied.sh start
spark1.4.1
安装路径:
/opt/spark-1.4.1-bin-hadoop2.6
环境变量:
export SPARK_HOME=/opt/spark-1.4.1-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$SPARK_HOME/bin
启动spark:
$:cd /opt/spark-1.4.1-bin-hadoop2.6
$:./sbin/start-all.sh
启动成功:
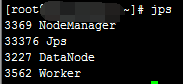
通过jps可看到集群规划中的相关进程。
主节点jps截图
分节点jps截图
编写Spark程序
目的
这里用的是tomcat产生的access日志文件,日志格式如下:
118.118.118.30 - - [15/Jun/2016:18:34:19 +0800] "GET /WebAnalytics/js/ds.js?v=3 HTTP/1.1" 304 -
118.118.118.30 - - [15/Jun/2016:18:34:19 +0800] "GET /WebAnalytics/maindomain? HTTP/1.1" 200 3198
118.118.118.30 - - [15/Jun/2016:18:34:19 +0800] "GET /WebAnalytics/tracker/1.0/tpv? HTTP/1.1" 200 631
118.118.118.30 - - [15/Jun/2016:18:34:22 +0800] "GET /WebAnalytics/tracker/1.0/bind? HTTP/1.1" 200 631
118.118.118.30 - - [15/Jun/2016:18:34:46 +0800] "GET /WebAnalytics/js/ds.js?v=3 HTTP/1.1" 304 -
对日志中ip进行统计,统计结果如下图:

详细代码
package com.simple.spark.oozie.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
/**
* Created by Administrator on 2016/8/25.
*/
public class OozieAction {
public static void main(String[] args){
String input = args[0];
String output = args[1];
String master = "local[*]";
if(args.length >= 3){
master = args[2];
}
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("OozieAction - " + System.currentTimeMillis());
if(!"none".equals(master))
sparkConf.setMaster(master);
JavaSparkContext context = new JavaSparkContext(sparkConf);
JavaRDD<String> stringJavaRDD = context.textFile(input);
stringJavaRDD.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String s) throws Exception {
String key = s.split(" ")[0];
return new Tuple2<String, Integer>(key, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
}).saveAsTextFile(output);
context.close();
}
}
Oozie工作流
示例工作流只有一个spark节点,节点工作流配置参照:
http://oozie.apache.org/docs/4.2.0/DG_SparkActionExtension.html#Spark_on_YARN
workflow.xml
<workflow-app name="Spark_Workflow" xmlns="uri:oozie:workflow:0.5">
<start to="spark-SparkOozieAction"/>
<kill name="Kill">
<message>Action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<action name="spark-SparkOozieAction">
<spark xmlns="uri:oozie:spark-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<master>${jobmaster}</master>
<mode>${jobmode}</mode>
<name>${jobname}</name>
<class>${jarclass}</class>
<jar>${jarpath}</jar>
<spark-opts>${sparkopts}</spark-opts>
<arg>${jararg1}</arg>
<arg>${jararg2}</arg>
<arg>${jararg3}</arg>
</spark>
<ok to="End"/>
<error to="Kill"/>
</action>
<end name="End"/>
</workflow-app>oozie.use.system.libpath=True
oozie.wf.application.path=/user/root/oozie/t1/workflow.xml
security_enabled=False
dryrun=False
jobTracker=hdp-master:8032
nameNode=hdfs://hdp-master:8020
jobmaster=yarn-cluster
jobmode=cluster
jobname=SparkOozieAction
jarclass=com.simple.spark.oozie.action.OozieAction
jarpath=hdfs://hdp-master:8020/user/root/oozie/t1/SparkOozieAction-jar-with-dependencies.jar
sparkopts=--executor-memory 128M --total-executor-cores 2 --driver-memory 256M --conf spark.yarn.jar=hdfs://hdp-master:8020/system/spark/lib/spark-assembly-1.4.1-hadoop2.6.0.jar --conf spark.yarn.historyServer.address=http://hdp-master:18088 --conf spark.eventLog.dir=hdfs://hdp-master:8020/user/spark/applicationHistory --conf spark.eventLog.enabled=true
jararg1=/data/access_log.txt
jararg2=/out/oozie/t1
jararg3=cluster本文重点:oozie spark on yarn官方文档有说明,要提交spark到yarn上,需要配置以下属性
1.确保spark-assembly-1.4.1-hadoop2.6.0.jar在oozie中可用,这个我理解了很久都没有参透,后面查阅相关文章后才知道,这里的意思是在提交任务时指定要应用的jar包,本文通过spark-opts参数--conf spark.yarn.jar=hdfs://hdp-master:8020/system/spark/lib/spark-assembly-1.4.1-hadoop2.6.0.jar指定。
2.master只能指定为yarn-client或者yarn-cluster,本文为:yarn-cluster
3. spark.yarn.historyServer.address=http://SPH-HOST:18088
4. spark.eventLog.dir=hdfs://NN:8020/user/spark/applicationHistory 这里的目录
必须事先创建好,spark会提示这个目录不存在的错误
5. spark.eventLog.enabled=true
$:hadoop fs -put /user/root/oozie/t1/workflow.xml$:hadoop fs -put /user/root/oozie/t1/SparkOozieAction-jar-with-dependencies.jarhadoop fs -mkdir put /user/spark/applicationHistoryhadoop fs -put /user/root/oozie/t1/SparkOozieAction-jar-with-dependencies.jar
提交程序到oozie
$:cd /opt/oozie-4.2.0
$:./bin/oozie job -oozie http://hdp-master:11000/oozie -config /opt/myapps/spark/t1/job.properties -run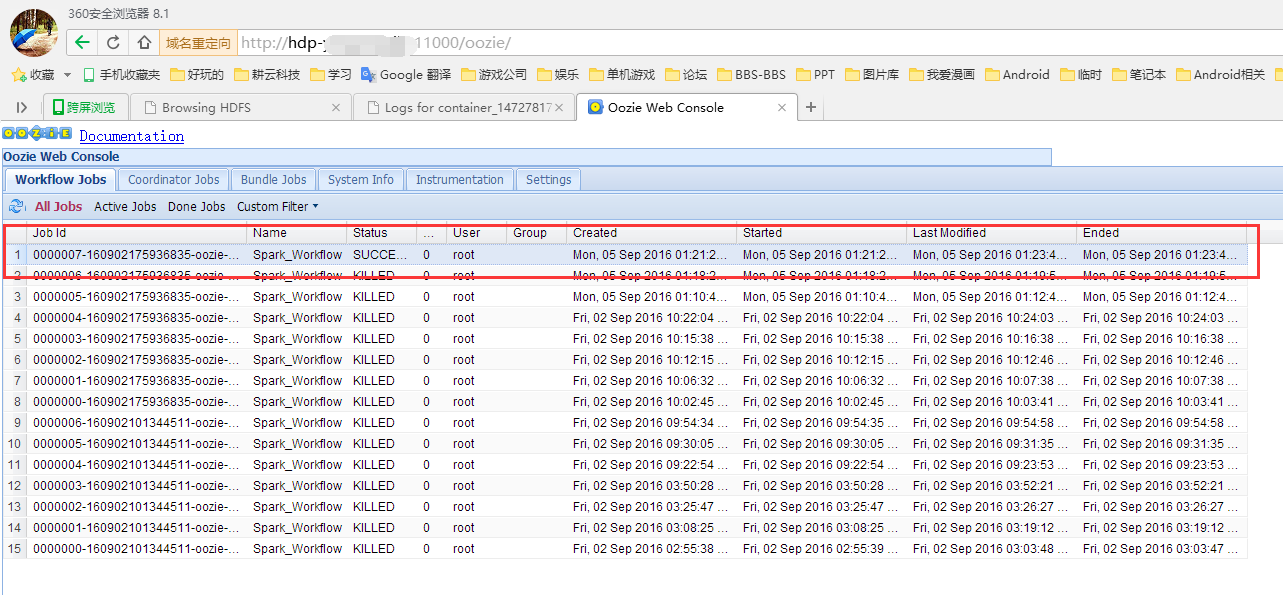
到yarn UI查看spark在yarn上的运行情况
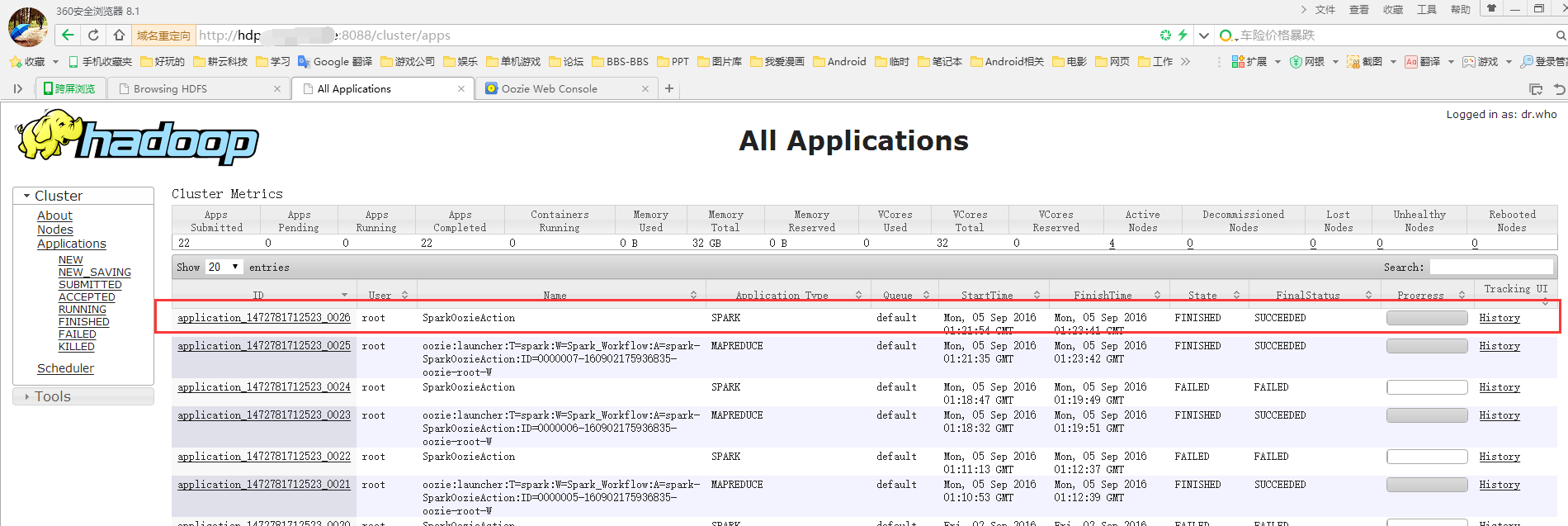
至此,spark 通过oozie提交到hadoop yarn上完毕。
谢谢!















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









