






今天,我们来讲非常简单的并查集
------------------------------------------------------------------------------------------------------------------------------------------
什么是并查集
首先,我们来看一道题目:
1346:【例4-7】亲戚(relation)
时间限制: 1000 ms 内存限制: 65536 KB
提交数: 36521 通过数: 7161
【题目描述】
或许你并不知道,你的某个朋友是你的亲戚。他可能是你的曾祖父的外公的女婿的外甥女的表姐的孙子。如果能得到完整的家谱,判断两个人是否是亲戚应该是可行的,但如果两个人的最近公共祖先与他们相隔好几代,使得家谱十分庞大,那么检验亲戚关系实非人力所能及。在这种情况下,最好的帮手就是计算机。为了将问题简化,你将得到一些亲戚关系的信息,如Marry和Tom是亲戚,Tom和Ben是亲戚,等等。从这些信息中,你可以推出Marry和Ben是亲戚。请写一个程序,对于我们的关于亲戚关系的提问,以最快的速度给出答案。
【输入】
输入由两部分组成。
第一部分以N,M开始。N为问题涉及的人的个数(1≤N≤20000)。这些人的编号为1,2,3,…, N。下面有M行(1≤M≤1000000),每行有两个数ai,biai,bi,表示已知aiai和bibi是亲戚。
第二部分以Q开始。以下Q行有Q个询问(1≤ Q ≤1000000),每行为ci,dici,di,表示询问cici和didi是否为亲戚。
【输出】
对于每个询问ci,dici,di,输出一行:若cici和didi为亲戚,则输出“Yes”,否则输出“No”。
【输入样例】
10 7
2 4
5 7
1 3
8 9
1 2
5 6
2 3
3
3 4
7 10
8 9
【输出样例】
Yes
No
Yes
好的,我们来分析一下这道题目:
首先,我们知道这些人有很多的亲戚关系,根据这些关系,我们可以推出他们的家族
比如小A和小B时亲戚,小C和小B是亲戚,我们就可以说,小A、小B、小C是同一个家族,这个家族里任意两个人都有亲戚关系,能理解吧?
所以,我们只需要想办法存储所有的家族,并把每个家族有哪些人也存起来,那我们就可以轻松地解决这道题目
好,现在,我们的问题是如何存储家族,对吧?那要怎么存呢?看起来这很难,事实上真的很简单。我们思考一下,每一个家族都有一个祖先,没有问题吧?我们可以利用这一点,存储家族
我们可以定义一个数组f,f [ i ]就表示 i 这个人的祖先。我们思考一下,如果小A和小B的祖先是同一个人,那小A和小B肯定属于同一个家族。如果小A用数字1代表,小B用数字2代表,他们的祖宗用数字3代表,那么,数组f [ 1 ] = f [ 2 ] =3,这就代表小A和小B有同一个祖先,那小A和小B就属于同一个家族,那小A和小B的祖先,我们叫他小C,我们把小C的祖先设为自己,因为小C没有祖先了,小C自己是自己的祖先,也就是说,谁的祖先是他自己,那他就是一个祖先,同样的道理,在所有人中,有多少个祖先,就说明有多少个家族(每个家族都有一个祖先)
我们的刚刚的解题的方法就是并查集
------------------------------------------------------------------------------------------------------------------------------------------
并查集怎么写?
好,我们已经理解了并查集的思路,那我们现在需要知道并查集要怎么写
首先,我们的数组 f 肯定要进行初始化吧?那他初始化成什么样呢?
在刚开始的时候,我们应该把每个人的祖先设为自己,因为这个时候我们还不知道他们之间的关系,所以把每个人当成一个家族,当我们输入某种关系后,我们再把某个人的祖宗进行修改
所有,初始化的代码要这么写:
void initFa(int n){
for(int i = 1; i <= n; ++i)
fa[i] = i;//用fa数组来存储每个人的祖先
}我们有的时候,还需要查询某个人的祖先,那这个代码怎么写呢?
我们可以用一个递归的方式来写,当我们找到祖先(自己的祖先是自己),我们就返回,否则就一直找下去
代码是这样的:
int find(int x){//x代表要找x的祖先
if(x == fa[x])//如果x的祖先是他自己
return x;//说明找到了祖先,我们返回x
else
return fa[x] = find(fa[x]);//否则就还没找到,继续找
//这里,fa[x]是x的祖先,find(fa[x])就是找x祖先的祖先
}细心的读者会发现,在找x的祖先的祖先的时候,我们返回 fa[x] = find( fa[x] ),而不是返回 find(fa[x]) ,这是为什么呢?
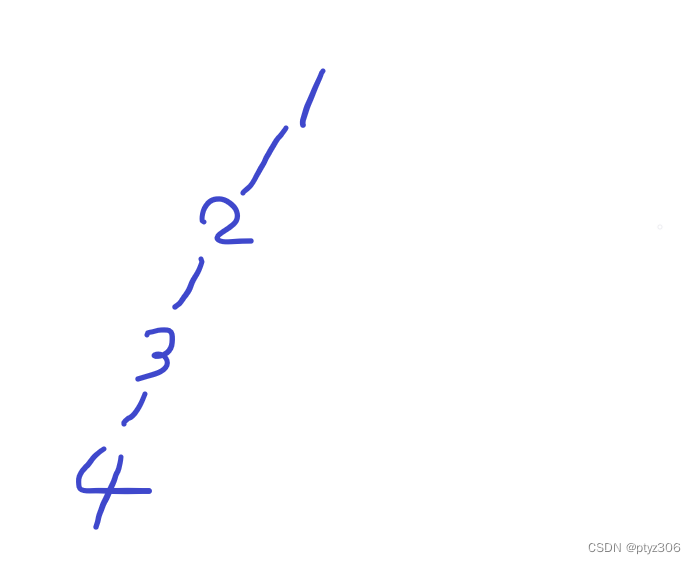
图片中,1是2的祖先,2是3的祖先,我们如果要找4的祖先,我们就需要递归4词,这就导致代码效率十分低下,我们可以进行优化:

将2、3、4的祖宗都变为1,这样在找4的祖宗的时候,我们只需要递归一次就能找到
这个过程叫做路径压缩
所以,我们需要返回fa[x] = find( fa[x] )
当我们输入两个人是亲戚关系时,我们需要修改两人的祖先
代码时这样的:
void merge(int x, int y){//x和y两个人要设为同一个祖先
fa[find(x)] = find(y);
//find(x)是找x的祖先,fa[find(x)]就是x的祖先的祖先
//find(y)是找y的祖先,fa[find(x)] = find(y)就是把x的祖先的祖先设为y的祖先
//find函数的作用是寻找某个人的祖先
}我们现在就可以写出亲戚这道题的完整代码了:
#include<bits/stdc++.h>
using namespace std;
#define N 20005//将N设为20005
int fa[N];//定义数组f,存储的是谁的亲戚是谁
void initFa(int n){
for(int i = 1; i <= n; ++i)
fa[i] = i;//用fa数组来存储每个人的祖先
}
int find(int x){//x代表要找x的祖先
if(x == fa[x])//如果x的祖先是他自己
return x;//说明找到了祖先,我们返回x
else
return fa[x] = find(fa[x]);//否则就还没找到,继续找
//这里,fa[x]是x的祖先,find(fa[x])就是找x祖先的祖先
}
void merge(int x, int y){//x和y两个人要设为同一个祖先
fa[find(x)] = find(y);
//find(x)是找x的祖先,fa[find(x)]就是x的祖先的祖先
//find(y)是找y的祖先,fa[find(x)] = find(y)就是把x的祖先的祖先设为y的祖先
//find函数的作用是寻找某个人的祖先
}
int main(){
ios::sync_with_stdio(false);
cin.tie(0);cout.tie(0);
//上面两行代码可以加速我们cin和cout的速度,也就是加速
int n, m, q, a, b, c, d;
cin >> n >> m;//有n个人,m对关系
initFa(n);//对数组f进行初始化
for(int i = 1; i <= m; ++i){
cin >> a >> b;//读入有亲戚关系的两人
merge(a, b);//将两人分为同一个家族
}
cin >> q;//q此询问
while(q--){
cin >> c >> d;//c和d是否是亲戚?
cout << (find(c) == find(d) ? "Yes" : "No") << '\n';
//三目运算符,意思是这样的:c的祖宗和d的祖宗是不是同一个人?
//如果是,输出yes,否则输出no,然后换行('\n'就是换行,听说比endl更快哦)
}
return 0;
}------------------------------------------------------------------------------------------------------------------------------------------
文章结束啦,你学会并查集了吗?















 1175
1175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









