






前言:
近期在weibo上讨论的比较热的话题无非就是“人口”了。TaoTao也看了一些大家发的内容。但是感觉单纯的看文字内容不能很直观的反应出来大家的关切。索性就使用爬虫对数据进行爬取,同时结合着数据可视化的方式让数据自己开口说话。那么接下来就让我们使用技术进行分析吧!
流程:
这里主要可以分为三个流程:
1、数据爬取
2、数据清洗
3、数据可视化
流程如下所示:
数据爬取:
这里TaoTao采用的方式是使用python对数据进行爬取。主要就是爬取实时数据进行分析
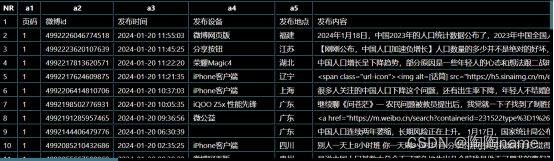
详细数据如下所示:
页码:表示一共爬取了多少页的微博
微博id:表示爬取的是具体的哪一篇微博数据
发布时间:表示微博内容发布的具体时间
发布设备:表示内容发布使用的是什么设备
发布地点:表示发布的内容的地址大概在哪里
发布内容:表示发布的具体内容
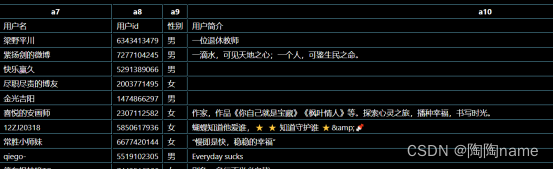
用户名:表示发布的作者用户名称
用户id:表示发布者的微博id
性别:表示该用户的性别
个人简介:表示该用户的简单说明
关注人数:表示用户都关注了多少人
粉丝数:表示用户的粉丝数量

数据清洗:
经过上面的步骤,我们已经获取到了大概1300多条的微博数据。这里我是18号进行采集的,现在应该不止这些了。 数据获取以后,我们观察数据其实不难发现在“发布内容”那一栏存在一些前端的内容,包括表情包呀、一些特殊的字符呀。 其实这些数据并不是我们需要关注的,所以我们需要对其进行数据清洗,将这些信息给过滤掉

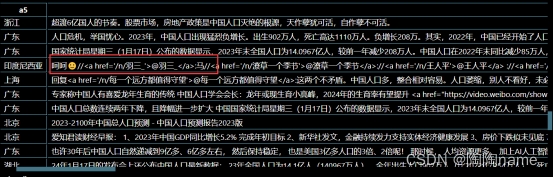
这里呢,TaoTao写了一些代码进行数据的过滤,过滤以后的数据呢如下:
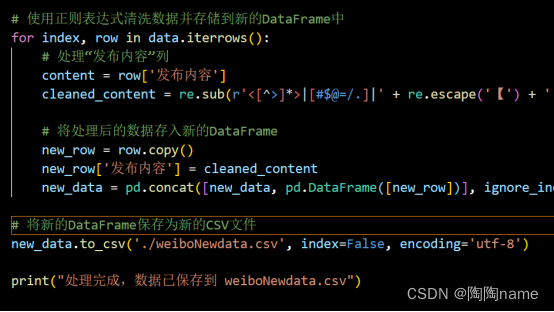
使用上述的代码进行过滤以后的数据如下:
可以看到对比上面的原始数据,数据要整洁许多

数据可视化:
上面的两个步骤,我们进行了数据的获取和数据的清洗。现在获得的数据是比较整洁。数据整理好了以后,就方便进行数据可视化了。那么接下来就让我们进行数据可视化操作吧。
TaoTao这里呢,主要分析的大概是这么几个数据:
1、微博发布时间可视化
2、内容发布的地区可视化
3、内容发布地区top20统计
4、发布者的性别情况
5、发布内容的情感分析
6、关键词Top10
7、发布内容的词云统计
1、“微博发布时间可视化”:
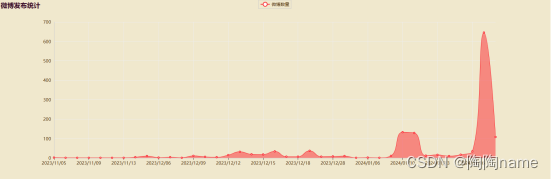
为什么要统计微博发布时间,并进行数据可视化呢?其实TaoTao是这么想的,通过观察哪一个时间段微博发布的数量比较多,从某种程度上可以反应近期大家的情绪反应。微博的发布时间可视化具体如下:
可以看到在2024.1.10-2024.1.16这个期间发布关于“人口”这个话题的人比较多。后来了解到,有关部门大概是在1.16号左右发布了相关数据,所以大家反应的比较积极。
2、“发布内容地区可视化”:
通过对发布内容的地区进行可视化,我们可以在宏观上大概的看出来哪个地区对这个话题比较的感兴趣,具体如下所示。

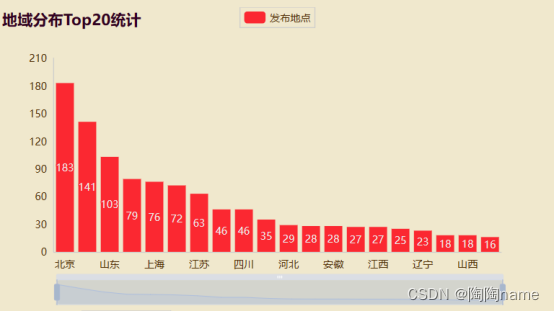
3、“内容发布地区top20统计”:
上面的“发布内容地区可视化”是在宏观上进行数据可视化。这里提到的“内容发布地区top20统计”就可以比骄傲直观的看到具体的一个数据分布情况。具体的数据可视化如下所示:
从图上可以看出来,北京地区好像对这个话题比较感谢兴趣,山西地区对这个就没有那么感兴趣了。具体是什么原因,可以再做详细的分析。
4、“发布者性别统计”:
通过对发布者的性别统计可以大体的看出来好像男性比女性要更加关注这个话题。

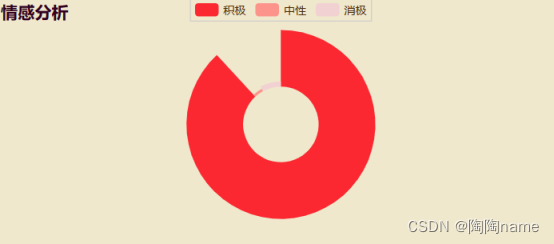
5、“发布内容的情感分析”:
TaoTao这里对大伙发布的内容进行分析,下面是详细的分析结果:
从数据层面可以看出来,大家对于“人口”这个话题好像是偏向于乐观的。
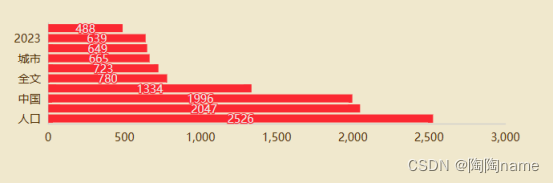
6、“发布内容的top10关键词”:
关键词具体如下所示:
7、“发布内容词云”:
同样的TaoTao也对发布内容进行统计并且制作了词云,具体如下所示:

其他主题大屏


主题大屏其实有十多种,上述TaoTao已经实现了其中的三种,其他的感兴趣的小伙伴可以自己实现。
源码获取链接:【爬虫、数据可视化实战】以“人口”话题为例爬取实时微博数据并进行舆情分析
由于笔者能力有限,在某些表述方面难免有些不准确,还请多多包涵!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











