



更快更便宜更好:优化AI推理,Baseten赞助
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, Base 10, Faster Model Inference, Cheaper Model Inference, Better Model Inference, Performance Optimization Techniques, Distributed Infrastructure Scaling]
导读
优化机器学习模型推理不仅仅关乎模型本身,而是涉及整个技术栈的每一层。在这个简短演讲中,了解Baseten如何优化AI原生产品在生产环境中的延迟、吞吐量和成本。探索应用模型性能研究和分布式GPU基础设施两个领域的主题,展示这两个领域如何结合,为初创公司和企业实现关键任务推理工作负载。本演讲由亚马逊云科技合作伙伴Baseten为您带来。
演讲精华
以下是小编为您整理的本次演讲的精华。
在2024年亚马逊云科技 re:Invent大会上,Baseten公司的联合创始人Phil登台发表了一场全面的演讲,探讨了如何优化AI推理的速度、成本效益和质量。凭借自公司创立以来与Baseten的基础设施和性能团队密切合作的丰富经验,Phil分享了提升AI模型性能的宝贵见解。
Phil首先强调了性能、可靠性和成本效益对于提供卓越客户体验的重要性。他指出,在当今竞争激烈的市场环境中,缓慢、不一致或成本高昂的产品是不可接受的。他的主要目标是阐明Baseten如何以无与伦比的速度、规模和可靠性,以经济高效的方式在生产环境中提供开源、微调和定制的AI模型。
演讲分为两个部分。第一部分探讨了专门为AI工作负载量身定制的各种技术,以推动卓越性能,而后半部分则关注如何有效地将这些性能提升应用于为数千或数百万用户提供服务。
在评估性能时,Baseten专注于三个关键指标:延迟、吞吐量和质量。延迟衡量模型从客户角度的响应速度,包括每秒令牌数和生成第一个令牌所需的时间。吞吐量则衡量模型的效率,考虑每个实例处理的输入数量以及生成输出的成本效益。最后,质量确保在进行性能优化的同时,保持输出的一致高质量。
在这三个约束条件之间取得最佳平衡是一项艰巨的挑战,但Phil强调,通过精心规划,可以实现满足客户需求且不超出预算限制的结果。
为了证明他们的方法,Phil分享了真实的客户案例和示例,说明了优化策略的实际应用。其中一个值得注意的例子是他们与企业LLM公司Riidr的合作。通过两个团队的密切合作,Baseten使Riidr实现了每秒令牌数量惊人的60%增长,同时将成本降低了35%。
Baseten的模型性能优化过程考虑了三个不同层面:硬件、运行时和模型本身。每个层面都提供了一组可调整的杠杆,用于优化不同的性能方面,例如选择合适的GPU、批处理和分块输入、使用不同的模型服务运行时、量化以及应用算法改进(如投机解码)。
Phil深入探讨了量化技术,该技术通过牺牲数值精度来换取性能提升。通过将高精度数字替换为较小的数字(如将32位替换为8位),量化可以改善首个令牌的时间、每秒令牌数量和内存带宽效率。这种方法使模型更快、更经济高效,但可能会降低质量。量化对性能的影响取决于诸如模型的数值稳定性和GPU硬件对低精度算术的优化等因素。
对于自回归模型(如LLM),投机解码和Medusa头部技术被视为有前景的优化技术。这些方法涉及使用较小的模型提前预测潜在的完成情况,从而避免了当投机路径准确时,较大模型所需的计算量昂贵的操作。Baseten的内部基准测试显示,在各个领域训练Medusa头部时,性能都有了显著提升,在Meta的ISLA 3模型上甚至实现了两倍或更高的改进。
为了让这些复杂的技术更容易被更广泛的受众接受,Baseten投资于开发人员友好的工具,如TensorRT LLM Engine Builder。该工具生成支持量化和投机解码等高级优化的现代模型推理服务器,使开发人员能够部署基础模型或利用Baseten内部专业知识的定制模型,从而实现最先进的延迟和吞吐量。
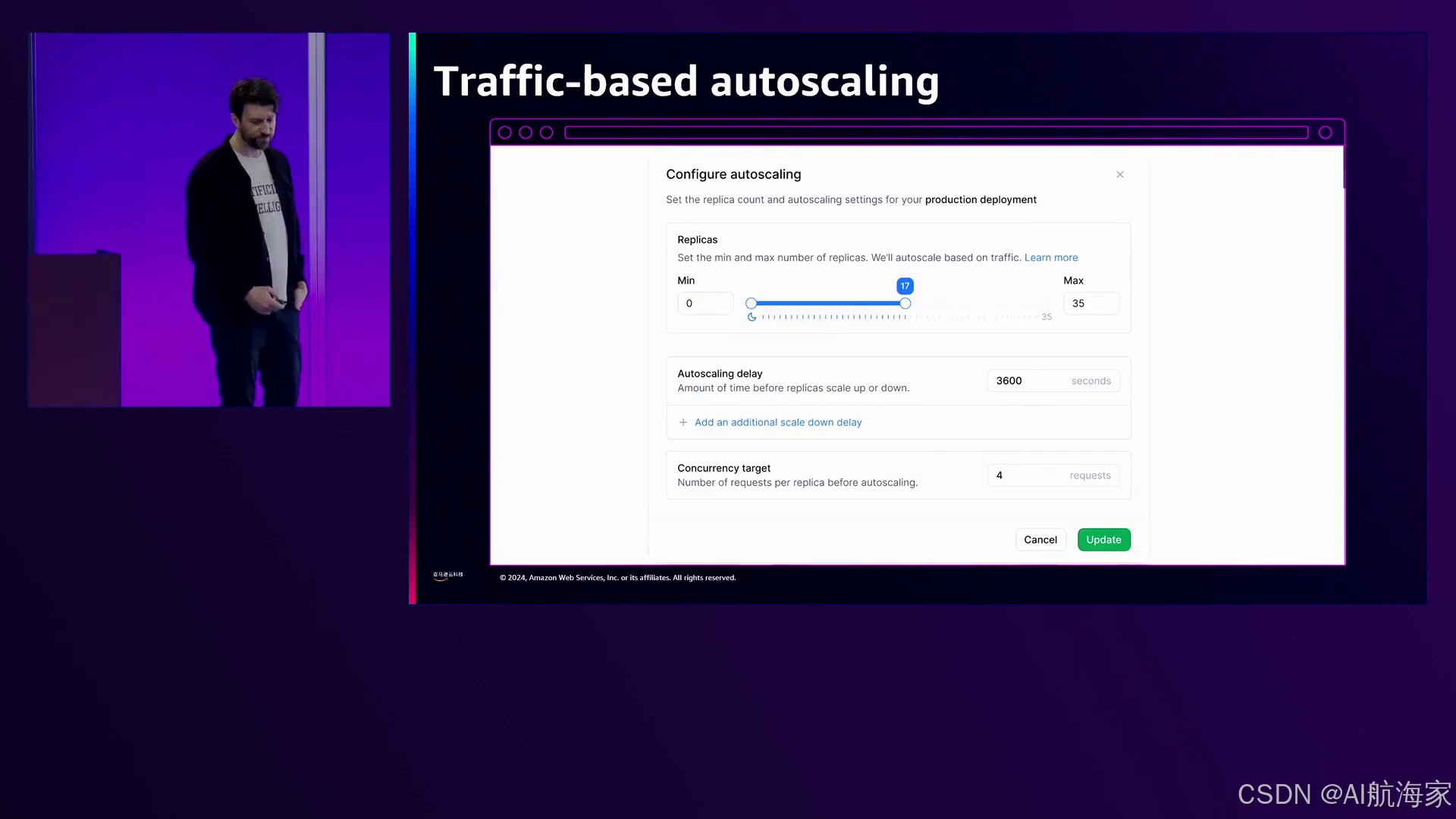
转向基础设施方面,大规模运行AI模型带来了一系列分布式基础设施挑战。为满足客户需求而进行自动扩展会引入冷启动问题,因为在运行时需要加载大量模型权重,可能高达10到100GB。确保可靠的用户体验和持续的正常运行时间,同时缓解GPU容量问题,并解决合规性、监管和可移植性问题至关重要。
Baseten强调基本原则,例如确保可靠且一致的P90延迟(最坏情况),正常运行时间100%,正如他们与客户Rhyme的成功合作所证明的那样。
可以在集群、多集群和全球范围内的不同层面来扩展AI推理基础设施,包括在客户的云环境中进行自托管或混合部署。Baseten投入大量资源开发可配置的自动扩展策略、负载均衡策略,并在客户的基础设施中完全运行他们的技术,以解决合规性和监管问题。
Phil强调的一个值得注意的合作项目是Baseten与Blandai的合作,他们提供了高性能模型和分布式基础设施,实现了具有自然延迟感的实时AI电话,就像普通电话对话一样。
总之,Baseten通过综合方法解决了优化AI推理速度、成本效益和质量的多方面挑战,该方法包括量化和投机解码等模型级技术,以及自动扩展、负载均衡和自托管或混合部署等基础设施级解决方案。通过全面解决模型和基础设施性能,Baseten旨在提供出色的结果,满足并超越客户的苛刻要求。
下面是一些演讲现场的精彩瞬间:
强调了在提供卓越的客户体验时,性能、可靠性和经济高效性的重要性,尤其是在人工智能带来的额外复杂性下。

NVIDIA的H100 GPU提供了硬件级别的优化,用于处理低精度算术运算如FP8,从而实现更高性能,同时保持输出质量。

演讲者解释了Medusa heads技术如何通过提前推测潜在的完成情况,从而加快大型语言模型的速度,使模型能够跳过昂贵的计算并实现显著的性能提升,而不会牺牲质量。
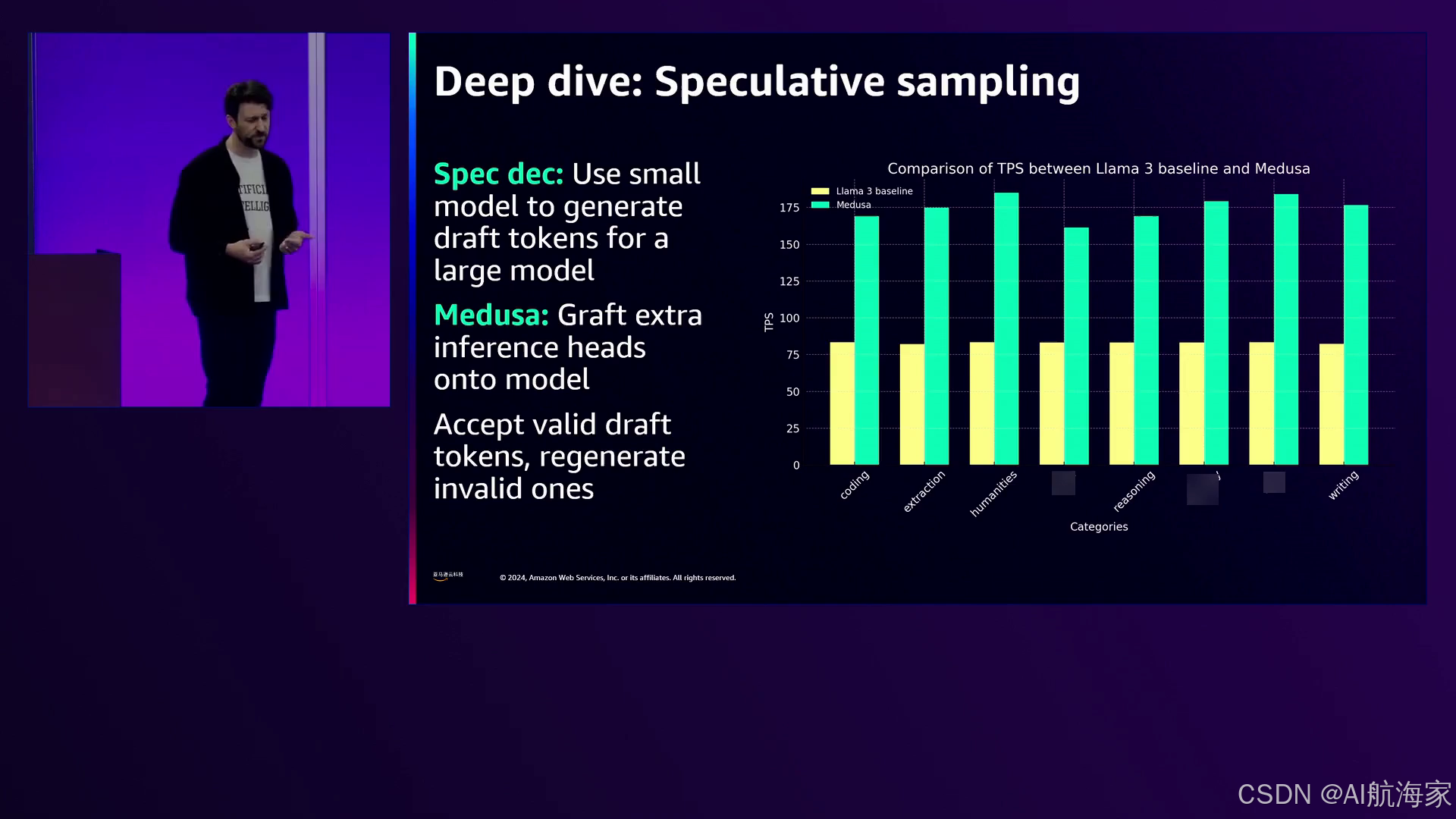
演讲者强调使用草稿模型的潜在好处,如更快的性能和成本节约,同时承认该方法的复杂性和特定领域的性质。

NVIDIA的TensorRT LLM Engine Builder通过先进的优化技术,简化了基础模型或自定义模型的部署,实现了更快、更经济高效的模型推理。

亚马逊强调了他们在自动扩展和负载均衡策略方面的投资,以优化大规模运行机器学习基础设施的性能和成本。
亚马逊云科技和Blandai之间的合作,通过优化模型和基础设施性能,实现了具有自然延迟的实时人工智能电话通话。

总结
在一个以性能、可靠性和成本为客户体验核心的世界中,Base10开创了优化AI推理模型的速度、效率和质量的技术。他们的方法包括利用硬件、运行时和模型级优化来权衡延迟、吞吐量和输出质量之间的平衡。
通过量化、推测解码和算法改进(如Medusa头),Base10在每秒令牌数和成本降低方面取得了显著的提升,同时保持了高质量的输出。他们的TensorRT LLM Engine Builder简化了优化模型的部署,使先进技术对开发人员来说更加易于访问。
除了模型优化之外,Base10还解决了扩展AI推理的分布式基础设施挑战。他们的解决方案涉及冷启动、全球分布、可靠性、合规性和云集成。通过允许用户配置自动扩展策略、负载均衡策略和混合云部署,Base10确保了大规模时的一致性能和成本效率。
最终,Base10的整体方法将模型和基础设施优化相结合,实现了突破性的合作,如具有自然延迟的实时AI电话。他们的平台使企业和初创公司都能够利用AI的力量,同时满足严格的性能、成本和监管要求。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









