



一种面向云计算数据安全的改进型基于属性的加密技术
1 | 引言
如今,人类行为已随着技术的发展而得到延伸,但尚无法实现机器支持的知识创造。1,2知识贯穿于文化的整个生命周期。为了促进知识发展,已经开发出知识网格计算平台,这是一种多学科系统,旨在利用万维网和互联网实现全球范围内的知识创造与共享。为了实现知识和资源的共享,科学家们正在开发支持按需服务、开放系统、复杂智能应用以及分布式计算的下一代Web技术。云计算是这些新一代Web技术之一,它基于效用计算、虚拟化、面向服务的架构以及并行与分布式计算,用于资源和知识的共享。3在云计算中,主要涉及三方:云服务提供商(CSP)、数据拥有者(DO)和用户。云服务提供商记录每个用户和数据拥有者的用户档案,并控制云服务器的所有任务,提供按需服务。4云服务提供商允许数据所有者将其数据或资源存储在云服务器上,用户可以从云服务器访问这些数据。由于存在黑客或云服务提供商对数据拥有者的敏感数据或资源的非法使用,用户的敏感数据面临日益增长的安全问题。在将任何数据存储到云服务器之前,应关注四个主要安全需求。首先,云服务提供商应确保用户敏感数据的数据机密性。其次,由于用户的访问权限基于其提供的身份信息授予,因此用户机密信息存在风险,必须谨慎处理用户身份。第三,由于互联网上存在大量黑客和恶意用户,云服务提供商应提供适当机制以抵御这些黑客,保障数据安全。第四,数据在预定义时间之前不应被访问,并应在过期时间之后被删除。由于黑客可能随时发起数据访问请求,一种可行的解决方案是仅允许授权用户在特定时间段内访问数据,并在预定义时间过后从云服务器删除数据。这样可以大大降低用户敏感数据遭受未授权访问的可能性。
多年来,许多研究人员提出了多种方案,以实现高网络性能和高效安全的数据访问。Shamir 首次提出了基于身份的加密(IBE)方案。在基于身份的加密中,消息或数据的发送方指定一个身份,接收方必须匹配该身份才能解密消息。
为了改善安全性和隐私问题,可搜索加密概念非常流行。在可搜索加密中,索引项被用于数据搜索过程。在此过程中,执行检索操作的实体无法读取响应内容。目前已存在许多可搜索加密方案。18,19这些方案的主要缺点之一是需要复杂的密码学操作。20在云计算中,用户需要对每个数据执行复杂的密码学操作,因此云服务提供商无法向所有用户提供云服务。当多个用户请求相同的数据或文件时,情况变得更加严峻。
因此,应当存在一种高效的数据访问控制模型,使云服务提供商能够为每个用户提供数据服务。
由于云环境中存在许多攻击者或恶意用户,数据所有者(DOs)通常希望数据在他们设定的预定义时间之前无法被访问。21定时释放加密(TRE)是解决此问题的一种有效技术。22许多研究人员提出了多种现有的TRE方案,23,24这些方案需要一个时间服务器来计算时间参考,并将加密密钥与预定义时间绑定。接收方或用户从时间服务器获取时间受限密钥,以计算解密密钥。所有这些方案均未考虑机密数据在过期时间之后的隐私或安全性。为解决该问题,最有效的解决方案之一是在过期时间后删除数据。许多研究人员已提出了多种自毁数据的解决方案。25,26所有这些方案都将DHT网络27与ABE方案或IBE方案相结合。28,29这些自毁方案的主要问题是,对于机密数据,它们未考虑预期发布时间的问题,且这些方案也容易受到多种攻击。
在本文中,为了解决上述所有问题,提出了一种新的访问控制模型,用于通过基于属性的加密、分布式哈希表网络和基于身份的定时释放加密实现资源与知识共享。在所提出的方案中,数据拥有者为每个资源或数据指定访问策略,用户通过其私钥生成满足访问策略的索引项以检索加密数据。此外,所提出的方案结合IDTRE方案与DHT网络,使得敏感数据或资源在预定义时间之前无法被读取,并且数据在过期时间之后可轻松实现自毁。本文的主要贡献如下:
i. 所提出的方案利用可搜索加密过程在云计算环境中共享资源。
ii. 所提出的方案适用于需要一次上传、多次下载数据服务的云环境。
iii. 在所提出的方案中,敏感数据或资源在预定义时间之前无法被读取,并且在过期时间之后数据可轻松实现自毁。因此,数据拥有者无需担心云服务提供商或恶意用户对敏感数据或资源的未授权使用。
iv. 所提出的方案是安全的,因为它能够抵御云环境中的多种攻击。
论文的其余部分分为不同的章节。第2节介绍了相关工作。第3节给出了所提出方案的系统模型与安全需求。第4节介绍了预备知识与定义。第5节描述了所提出的方案。第6节给出了所提出方案的安全分析。第7节进行了性能分析。最后,第8节对全文进行总结。
2 | 相关工作
萨海和沃特斯于2005年首次提出了支持复杂访问控制模型的基于属性的加密方案。ABE主要基于公钥,通过使用访问策略来实现数据访问控制,属性与公钥和密文相关联。已提出许多基于访问树的ABE方案,即基于密钥策略的ABE(KPABE)和基于密文策略的ABE(CPABE)。在KPABE中,密文与一组属性相关联,用户的私钥与表示用户身份的访问结构相关联。如果用户的访问树满足密文的属性,则该用户能够解密该密文。在CPABE中,每个密文都被分配一个访问策略,用户的私钥根据其属性生成。如果用户的属性满足密文中指定的访问策略,则该用户能够解密该密文。现有方案中最重要的一项缺点是由于配对运算导致系统开销非常高。CPABE中密文的访问结构以及KPABE中的属性列表均以明文形式保存,因此攻击者或云服务提供商可以轻易地从云数据库或服务器获取敏感数据,因为访问结构和属性列表均处于明文形式。目前已存在许多支持访问策略隐藏的ABE方案。但由于这些方案中解密密钥可能被可信第三方访问,因此它们不适用于云服务器环境,无法实现安全的数据访问控制。
博恩等人基于IBE首次提出了可搜索加密方案,即带关键词的公钥加密(PEKS)。37可搜索加密方案的主要目标是提供针对中间网关的安全性。PEKS在访问策略方面不具备丰富的表达能力。为了解决这一问题,许多研究人员提出了多种方案。Boneh和Waters提出了一种隐向量加密(HVE)方案,该方案支持合取和范围查询。18在HVE中,密文大小随着属性数量线性增加,为了提供关键词隐私,HVE需要将每个索引项包含在每个密文中。在HVE和PEKS中,需要进行深度搜索以提供数据。
PEKS和HVE的主要缺点之一是这两个方案仅关注一次性消息传递过程,因此不支持一次上传多次下载模式的数据服务。Koo 等人通过在云计算环境中使用基于属性的加密(ABE),提出了一种高效安全的数据访问控制模型。19该方案的主要优势在于通过最小化搜索索引减少了数据访问时间。但Koo 等人未考虑过期时间后敏感数据的安全性,这带来了严重的安全问题。
许多先进的方案已被提出以提高点对点(P2P)网络的性能。6,8,10,12,14诸葛和李通过将映射链接用于度量空间,提出了三种改进的八卦技术,并动态选择邻居节点来传播消息。6在此,节点根据连接特性进行区分和链接。谐波环(HRing)已在诸葛等人中提出,12其中路由表基于节点之间的距离而非节点ID构建,从而消除了节点ID分布不均和负载均衡的影响。它支持离开与重新加入的负载均衡,而不会导致长链分布不均。在此,节点ID可以是任何形式,例如数字、地址、字符串和日期。一种虚拟环方法已被提出用于分析和设计小型结构化P2P网络。14该方案的主要思想是基于距离度量抽象出虚拟环。在P2P网络中实现语义能力和可扩展性是一个极具挑战性的问题。为解决这些问题,分布式后缀树(DST)覆盖层被提出作为语义覆盖层和DHT覆盖层之间的中间层。10该方案在负载均衡方面快速且高效。
1996年,Rivest 等人首次提出了限时释放加密。22他们使用时间服务器来提高数据安全性,使得即使数据的发送方也无法在预定义时间之前访问该数据。Hwang 等人提出了一种利用预开启能力的TRE。38在他们的方案中,接收方可以在预定义的释放时间之后解密数据。接收方使用发送方提供的释放密钥和其自身的私钥来解密消息。Liang 等人提出了一种新概念,即限时释放条件代理广播重加密(TRCPBRE)。39他们考虑了安全模型的两个不同方面。第一方面是黑客不允许获取密钥,但允许获取限时释放密钥,因此即使他们拥有限时释放密钥,在没有密钥的情况下仍无法获得原始数据。第二方面是相反的情况,意味着即使黑客拥有密钥,如果没有适当的限时释放密钥,也无法获取原始数据。现有的TRE方案不支持发送方和接收方的匿名性。为了解决这个问题,Chan 和 Blake 使用了双线性对的概念,并将IBE与TRE相结合。40在他们的方案中,可信时间服务器与发送方或接收方之间不需要交互。即使可信时间服务器也不知道用户的存在,因此他们的方案不仅提供了消息的安全性,还提供了用户的匿名性。
Geambasu 等人首次提出了一种用于自毁数据的Vanish系统,以确保数据安全性和性能41。在他们的方案中,敏感信息(如文件和电子邮件)会在无需用户或中央管理员任何操作的情况下实现自毁。2013年,Wang 等人改进了Vanish系统,并提出了一种用于电子数据的安全自毁方案(SSDD)42。在SSDD中,数据首先被加密,然后提取密文使其不完整。接着,提取后的密文和解密密钥被分发到DHT网络中。为了获取原始数据,授权用户必须从DHT网络中获取提取的密文和解密密钥。Xiong 等人将ABE方案与DHT网络相结合,提出了一种保护用户敏感数据的自毁方案26。该方案在用户敏感数据的生命周期内提供了细粒度数据访问控制,并且能够抵御DHT网络中的多种攻击,例如暴力破解攻击、跳攻攻击和嗅探攻击。Zeng 等人基于T10 OSD标准提出了SeDas系统,通过删除文件和加密密钥来确保数据安全43。在SeDas中,基于主动存储框架,采用基于对象的存储接口来管理和存储密钥。
3 | 系统模型与安全需求
3.1 | 系统模型
在所提出的方案中,有七个实体用于安全的数据访问:云服务提供商、数据拥有者、用户、攻击者、可信第三方、时间服务器和DHT网络的节点。云服务提供商为数据拥有者和用户提供数据存储服务和检索服务。数据拥有者以加密形式将数据存储在云服务器上,以便只有具备必要属性和解密密钥的授权用户才能解密加密数据并获取原始数据。攻击者是试图从云服务器进行未授权访问的实体,他们不仅尝试在预期发布时间之前访问数据,还可能在数据过期时间之后尝试访问。云服务提供商应保护数据免受这些攻击者或恶意用户的侵害。可信第三方负责维护数据拥有者和用户的属性,并生成所提出技术所需的全部系统参数,例如公共参数、主私钥和解密密钥。时间服务器是一个记录参考时间的实体,不与其他实体进行任何形式的交互,它通过时间绑定的密钥更新来记录准确的释放时间。DHT网络的节点负责管理和存储密钥分片。攻击者也可能试图获取这些密钥分片,因此云服务提供商应对其进行保护。
3.2 | 安全需求
在本小节中,讨论了所提出方案的安全需求。
i. 数据机密性:数据拥有者的敏感数据应受到保护,防止无访问权限的攻击者或恶意用户访问。此处的访问权限指充分的凭证,授权用户在访问任何数据前必须满足这些凭证要求。
ii. 抗合谋性:抗合谋性意味着即使多个用户共谋并将其各自的密钥组合起来尝试解密加密数据,他们仍然无法成功解密该加密数据。
iii. 抗攻击性:所提出的方案应能抵御多种攻击,例如暴力破解攻击和女巫攻击。在暴力破解攻击中,攻击者或恶意用户会尝试使用所有可能的密钥来解密加密数据。在女巫攻击中,攻击者或恶意用户会利用多个身份尝试解密加密数据。
iv. 敏感数据在预设发布时间前不应可访问:敏感数据仅应在授权时段内可访问。在预期发布时间之前,任何人都无法访问该数据,从而提升所提出方案的安全性。
v. 敏感数据在过期时间后应被删除:敏感数据应在过期时间后自动自毁,无需数据拥有者(DO)进行任何操作。即使授权用户在数据过期后也无法再访问该数据。
4 | 预备知识与定义
4.1 | 双线性映射
设G1、G2和GT是三个素数阶Q的循环群。一个双线性映射e:G1××G2→→GT满足以下性质:
i. 双线性:对所有 u ∈ G1;v ∈ G2 以及所有 a, b ∈ZQ,均有 e(ua, vb) = e(u, v)ab。
ii. 非退化:双线性映射不会将 G1×G2 中的每一对元素都映射为零。
iii. 可计算性:对于任意 u ∈ G1 和 v ∈ G2,,存在高效算法来计算 e(u, v)。
4.2 | 访问结构
设参与方集合表示为 {P1, P2,…,Pn}。对于 ∀B,C,若参与方集合A⊆2 P 1 ;P 2 n f g;…;P 是单调的,即若 B ∈A 且 B⊆C,则 C ∈A。访问结构是 2 P 1 ;P 2 n f g;…;P 的非空子集的集合。在 A 中的参与方被识别为授权参与方,不在 A 中的参与方被识别为非授权参与方。
4.3 | 关于时间的数据安全范式
i. 预期发布时间:由数据拥有者预先定义。在规定的预期发布时间之前,用户无法读取数据或文件。
ii. 过期时间:由数据拥有者预先定义。在预定义的过期时间之后,用户无法访问任何数据。因此,为提高数据安全性,敏感数据应在过期时间后被删除。
iii. 授权时段:授权时间是指从预期发布时间到过期时间之间的时间区间。
iv. 完整生命周期时间:是包含授权时段、预期发布时间和过期时间的时间间隔。用户敏感数据应在各自数据的生命周期时间内受到保护。
4.4 | 定义
Setup(κ) :可信机构执行该算法以进行系统初始化。该算法以隐式安全参数(κ)作为输入,输出系统参数(params)、公钥(PK)和主密钥(MK)。
KeyGeni(MK, Λi) :该算法用于生成每个用户的私钥。该算法以主密钥MK和用户(ui)的属性集合(Λi)作为输入,输出结果为私钥或密钥(SK)。
KeyGeno(MK,IDo) :该算法由可信机构执行,用于保护访问树中暴露的属性。该算法以主密钥MK和数据拥有者(DO)的身份IDo 作为输入,输出一个匿名密钥Ao 以混淆属性。
PseudoGen (PK,IDo) :该算法由DO在数据分发过程之前执行。该算法以IDo 和PK作为输入,输出一个假名(Po),从而能够在保护DO身份的同时生成其属性的混淆值。
Encrypt (PK;M; (Po);A) :该算法由DO执行,以PK、消息(M)、Po和访问结构A作为输入,输出密文(CT′′),使得只有满足访问树的授权客户或用户才能获取外包数据并进一步获得原始消息。
属性混淆(CT′′, Ao, S) :该算法由数据拥有者(DO)执行,用于保护密文CT′中的属性。该算法的输入为CT′′、Ao以及一个属性集合S。DO利用Ao为S中的属性生成混淆索引项(SITo, S),并在将S在CT′′中替换为SITo, S后输出新的密文(CT′)。
ReEncrypt (CT′, K, params) :该算法由数据拥有者(DO)执行,以密文CT′、参数params和随机密钥K作为输入,输出用户机密数据的密文(CT)。该算法提高了用户敏感数据的安全性。
数据提取(DataExtract) (CT,params) :该算法由数据拥有者执行,以密文和参数作为输入,输出提取密文(CTE)和封装密文(CTD)。提取密文用于生成密文份额(CTS),封装密文用于封装自毁数据对象(SDO)时使用。
IDTimeReEncrypt(K,params, IDi,T) :该算法由数据拥有者执行,以随机密钥(K)、参数(params)、授权用户的标识(IDi)和释放时间(T)作为输入,输出密钥密文(CTK)。
PolyGen(CTE, CTK) :该算法由数据拥有者执行,以CTE和CTK作为输入,输出拉格朗日多项式。
CTSGen (polynomials, params) :该算法由数据拥有者执行,以拉格朗日多项式和参数为输入,生成n个不同的CTS。
CTSDist (L,CTS) :该算法由数据拥有者(DO)执行,以随机访问密钥(L)和n个不同的CTS作为输入。它将n个不同的CTS分散到DHT网络中。
SDOGen (L, CTD, 参数) :数据拥有者执行该算法,以 L、CTD 和参数作为输入。该算法封装并创建 SDO,然后将其发送给云服务提供商。
解封装(Decapsulate) :该算法由授权用户执行,以获取L和CTD。该算法以封装的SDO作为输入,输出L和CTD。
ID释放时间消息 crypt(CTK) :该算法由授权用户执行,以获取释放时间 T 和原始密钥 K。
查询(PK, SK, Po) :仅授权用户使用此算法来获取混淆的索引项。该算法以公钥 PK、私钥 SK 以及数据拥有者的假名 Po作为输入,输出私钥 SK 中每个元素的混淆属性,记为 SITo;Λi。授权用户使用 SITo;Λ′i发送查询以获取所需的检索服务,其中 SITo;Λ′i⊆SITo; Λi。
检索 SIT o;Λ′i;CT :该算法由云服务提供商执行,用于检查用户请求的加密数据。它以从云数据库获取的一组密文 CT 和 SITo;Λ′i 作为输入。如果 SITo;Λ′i 满足 CT ∈CT 中的访问结构,则查询返回真,并向用户提供密文 CT;否则,查询返回假,且不向用户提供密文 CT。
Decrypt (PK,CT,SK) :授权用户使用该算法解密密文并获得原始消息M。该算法以PK、CT和SK作为输入,当属性满足对密文CT的访问权限时,返回消息M。图1展示了所提出方案的工作流程。
5 | 提出方案
在本节中,提出了一种新的高效安全的数据访问控制模型,该模型在云计算环境中结合了基于属性的加密、分布式哈希表网络和基于身份的定时释放加密技术。所提方案的详细内容如下所述。
5.1 | 系统初始化
该算法以一个较大的隐式安全参数(κ)作为输入。它涉及三个群G、G1 和G2 ,它们均具有素数阶Q,g是群G的生成元,g1 是群G1 的生成元。该算法还选择两个随机指数 α、 β ∈∈ZQ,以及三个密码学哈希函数H: 0 1 f g→;G;H1: 0 1 f g→;G1 和H2:G2 → 0; 1 f gn。该算法输出三个结果,即公钥PK、主密钥MK和系统参数。公钥PK可被所有人获取,而主密钥MK需保密。相关符号说明如下:t表示阈值,n表示密钥分片数量,b表示每次提取中存在的总比特数,bt=表示提取的总次数。
MK ¼ β;g α ;x ∈ Z Q ð Þ
PK ¼ G ; g ; g 1 ; y ¼ x g ð Þ ∈ G 1 ; h ¼ g β ;ω ¼ e g ; g ð Þα
因此,系统参数可以表示如下:
params ¼ κ; t; b; bt; n; H; H1; H2; G; G1; G2; Q;g;g1; e; y; α; β ð Þ:
5.2 | 私钥或密钥生成
可信机构为具有身份IDi的用户ui执行密钥生成算法KeyGeni,并输出私钥SK。此处,首先从ZQ中随机选择r,然后为每个属性 λj ∈⋀i再次从ZQ中随机选择一个随机变量rj ∈。私钥的计算如下所示
SK ¼ D ¼ g αþ r
β;∀λi ∈ ⋀ i: D j ¼ g r : H λ j r
j; D ′
j ¼ g r j; D ′′
j ¼ H λ j
β
n o 0@ 1
A:
5.3 | 匿名密钥生成
在此阶段,可信机构为数据拥有者生成匿名密钥。对于具有IDo的数据拥有者,可信机构运行算法KeyGeno,并输出一个匿名密钥Ao = H(IDo) β 给该数据拥有者。
5.4 | 假名生成
数据拥有者通过运行PseudoGen算法生成数据的假名。在此过程中,数据拥有者从ZQ中随机选择t1,并自行创建其假名Po ¼ HID ð oÞt1。Ao和Po与用户协商一个会话密钥,该密钥用于混淆访问结构中显示的属性。
5.5 | 数据加密
DO通过在访问树T 下执行加密算法来加密数据M,并输出密文CT′′。该算法以自顶向下的方式为访问树的每个节点选择一个多项式qx 。对于访问树中的每个节点,算法设置qx 的次数(dx),该次数比该节点的阈值小1。因此,dx =kx −1。对于根节点R,该算法从ZQ 中随机选择一个值s,并设置qR (0) = s。然后,它随机选择dR 以确定多项式qR 的其他点。对于树中的其他节点,算法设置qx( 0)= qparent(x)( index(x)),并为qx 的其他点随机选择dx。
如果Y是T中叶节点的集合,则密文构造如下
CT′′ ¼ T;Ce ¼ Mωs; C ¼ hs; C′′ ¼ Po;∀y ∈ Y: Cy ¼ gqy ð0 Þ; C′ y ¼ H attry ð Þqy ð0 Þ n o :
5.6 | 属性扰乱
该阶段负责混淆属性值。由于密文中包含了以明文形式存在的访问树,因此属性集合是公开的。为此,数据拥有者运行AttributeScrm算法,对访问树T中的所有属性进行隐藏,从而得到另一个访问树T′。对于访问树中的属性集合S ={λi,…, λk},数据拥有者进行如下计算
SITo;S ¼ ∀λj ∈ S: e A0t1; H λj
¼ ∀λj ∈ S: e Hð IDoÞβt1; H λj ¼ λj ∈ S: e Hð IDoÞ; H λj βt1:
数据拥有者随后将scmattrx ∈SITo;S分配给叶节点,而不是根据属性attrx将其分配给 λx。最后,在密文 ′′中用T′替换T后,数据拥有者生成新的密文′如下:
CT′ ¼ T′;Ce; C; C′′;∀y ∈ Y: Cy; C′ y
:
5.7 | 数据重新加密
数据拥有者运行重加密算法以提高安全性。数据拥有者将密文′、参数和随机密钥K作为输入,输出密文(CT)。
5.8 | 数据提取
在此阶段,数据拥有者首先将密文划分为 s 个部分,每部分 m 位。为了获得等长,密文的最后一部分用零填充。因此,密文 =(CT1, CT2,…, CTs)。然后,算法从 CTi 的 [1, b*bt] 位置提取消息,其中 i= 1, 2, …, bt,得到 mi。提取出的密文表示为 CTE ¼ m 1 b t ð Þ 2 ; m ; …; m ,其中 mi=(m[i][0], m[i][1], …, m[i][t − 1]),剩余的密文称为封装密文 CTD。
5.9 | 基于身份的定时重加密
该算法以随机密钥K和参数params作为输入,收集一个有效用户的身份IDi和释放时间(T)。然后执行以下步骤:
- 计算 ωE= H1(IDi) + H1(T)。
-
选择一个数 r1 ∈ZQ,并计算 ω ¼ ey; ω ð ÞEr1 ¼ exg1 ð Þ ω ;Exr1。
K的密文计算为CTK¼ 。
5.10 | 多项式生成
在此阶段,数据拥有者通过运行PolyGen算法生成拉格朗日多项式。该算法将K的密文划分为t个部分,例如CTK = CTK0 , CTK1 ,…,CTKt−1 ,并生成bt + 1个多项式F1xð Þ;F2xð Þ;…;Fbtþ1xð Þ,其中
F 1 ðx Þ ¼ m ½ 1 t − 1 ½ x t − 1 þ m ½1 t − 2 ½ x t − 2 þ...þ m ½ 1 ½0 ;
F i ðx Þ ¼ m ½ i t − 1 ½ x t − 1 þ m ½ i t − 2 ½ x t − 2 þ...þ m ½ i ½ 0;
............
F b t ðx Þ ¼ m b t − 1 ½ x t − 1 þ m b t − 2 ½ x t − 2 þ...þ m b t ½ ½0 ;
F b t þ1 ðx Þ ¼ ck t − 1 ½ x t − 1 þ ck t − 2 ½ x t − 2 þ...þ ck 1 x þ ck 0 :
5.11 | 密文份额生成
该算法以bt + 1个拉格朗日多项式F1(x)、F2(x)、…、Fbtþ1xð Þ和参数params作为输入,生成密文份额。它选择随机值x1,、x2,、…、xn ,其中 xi > 1对应i= 1、2、…、n,并设置CTS i ¼xi i ð Þ ð Þ 1 i ð Þ 2 i ð Þ btþ1 ;Fx;Fx;…;Fx。该算法输出n个不同的密文份额CTS=(CTS1 ,、 CTS2 ,、…、CTS n) 。
5.12 | 密文份额分发
DO执行CTSDist算法来分发CTSs。对于给定的密文份额,该算法随机选择访问密钥L。访问密钥L用于通过伪随机数生成器生成n个索引l1,l2,…,ln。在 DHT网络的随机位置 li上,该算法分发所有n个密文份额 CTSi。
5.13 | 自毁数据对象(SDO)生成
数据拥有者通过运行SDOGen算法生成SDO。数据拥有者生成并封装一个自毁数据对象SDO=(L, CD, params),该对象存储在云服务器上。
5.14 | 解封装
在SDO授权时,解封装算法可以解封装并获得L和CD。L的值用作伪随机数生成器的种子,以获取超过t −1个索引,从而从分布式哈希表网络中检索t −1个CTSi。因此,通过该算法,用户可以轻松计算出CTS。然后,通过使用拉格朗日插值多项式函数,用户可以轻松获得bt+ 1个多项式来构造CTE和CTK。最后,利用CTE和CTD,用户可以恢复密文。
5.15 | 基于身份的定时重解密
授权用户可以通过运行IDTimeReDecrypt算法获取K。用户可以从服务器获得其私钥kIDi ¼ xH1 ID ð iÞ ∈G1和最近的时间绑定密钥xH1(T)。对于密文CTK,该算法执行以下任务:
- 将时间限定密钥与私钥结合计算 ωD= xH1(IDi) + xH1(T)。因此, ωD= xωE。
- 计算配对函数 ω′ ¼ eðr1 Þ 1 ω g;D。
- 密文K被解密为 K⊕H2 ðω Þ⊕H2ω′以获得随机密钥。
这里,er1 ωD ð Þ ¼ 1 g;er1 ωE ð Þ ¼ 1 g;xeg 1 ωE ð Þxr 1;。因此, ω′ ¼ ω这意味着 K⊕H2 ðω Þ⊕H2 ω′ ¼ K。所以,用户能够使用 K 解密密文,并获得密文 CT′。
5.16 | 原始查询用于数据访问
为了获取原始数据,授权用户通过使用查询算法向云服务提供商发送查询请求。首先,用户获取数据拥有者的假名列表。当用户使用C′′ =Po访问任意数据拥有者的数据时,将根据与相应属性相关的加密索引项生成会话密钥,如下所示:
SIT o; ⋀ i ¼ ∀j ∈ ⋀ i : e D ′′
j
; C ′′
¼ ∀λj ∈ ⋀ i : e H λ j β; H ID ð oÞt 1
¼ ∀λj ∈ ⋀ i : e H λ j
; H ID ð oÞβt 1
:
用户随后发送根据偏好,将打乱索引SITo ; ⋀ ′ i ∈SITo ; ⋀ i 的信息作为数据请求发送给云服务提供商 .
5.17 | 数据检索
当云服务提供商接收到带有混淆索引SITo ; ⋀ ′的数据请求时,云服务提供商首先检查用户请求的数据是否存在于云数据库中。云服务提供商可以检索出一个密文列表,其中SITo ; ⋀′i⊆ scmattr x 位于访问树T中。
在进一步处理之前,制定了一种比较算法 C T;SIT o ; ⋀ ′,该算法返回“true”或“false”值。假设树T的子树表示为 Tx,X′ 是其父节点为 x 的子节点集合,其中 X′ ={x ′ ∈Yx 且 parent(x ′ ) = x}。算法 C T; SIT o ; ⋀ ′ 递归计算如下:如果 x 是叶节点,则算法 C T; SIT o ; ⋀ ′ 当且仅当 attr x ∈SITo ; ⋀ ′ 时返回“true”;如果 x 是非叶节点,则 C T; SIT o ; ⋀ ′ 当且仅当至少有 kx 个子节点返回“true”时才返回“true”。云服务提供商检查云数据库上每个密文的算法 C T; SIT o ; ⋀ ′,若算法返回“true”,则将相应的密文发送给用户。
5.18 | 数据解密
当用户以加密形式从云服务提供商处获取请求的数据后,通过运行解密算法来获得原始数据,该过程由一个递归算法描述。这里考虑了一个递归算法 DecryptNode (CT, SK, x),它接受三个输入,即 CT、SK 和来自树 T 的节点 x。
如果x是树T的一个叶节点,则我们假设i= attrx,并按如下方式计算DecryptNode(CT, SK,x):
DecryptNode CT; SK;x ð Þ ¼ e Di; Cx ð Þ
e D′ i; C ′
x
¼ e g;g ð Þrqx ð0 Þ:
需要注意的是,T 中的每个 i =attrx 都与混淆的索引项相关联,这种关联方式只有数据拥有者和用户才能共同生成。如果 i ∉S,上述算法将返回空(⊥)值。
如果x是一个非叶节点,对于x的所有子节点z,调用算法DecryptNode(CT,SK,z),并将输出结果记为Fz。令Sx为z的任意一个大小为kx的子节点集合,且满足Fz ≠⊥。如果没有这样的集合存在,则该节点不满足访问条件,返回null。否则,按如下方式计算Fx并返回结果:
Fx ¼ ∏
z ∈ Sx
FzΔ i;S ' x
ð0 Þ Where; i ¼ index ðz Þ and S ' x ¼ index ðz Þ:z ∈ Sx f g h i
¼ ∏
z ∈ Sx
e g;g ð Þrqz ð0 Þ
Δi; S ' x
ð0 Þ
¼ ∏
z ∈ Sx
e g;g ð Þrqparentð z Þindex ðz Þ
Δi;S ' x
ð0 Þ
By construction ½
¼ e g;g ð Þrqx ð0 Þ Using polynomial interpolation ½
现在,该算法在访问树的根节点上调用函数Fx。如果该树T存在任何满足条件,则按如下方式计算集合A:
A ¼ DecryptNode CT; SK; R ð Þ
¼ e g;g ð Þrqr ð0 Þ
¼ e g;g ð Þrs
最后,该算法通过以下计算得到原始消息M:
e
C e C; D ð Þ
A
¼ Mωs
e h s
;g
ðαþrÞ=β
e g;g ð Þrs
¼ M
6 | 安全分析
所提出的方案提供了数据机密性,并且能够抵抗多种攻击。在所提出的方案中,密钥的密文和密文份额被分发到DHT网络中,由于DHT网络的独特属性,这些密文将自动删除。所提出方案的安全性可以通过以下五个问题进行分析:
i. 所提出的方案是否为用户的敏感数据提供数据机密性?
ii. 所提出的方案是否能够抵抗合谋攻击?
iii. 加密算法是否能够抵御传统攻击?
iv. DHT网络是否能够抵御女巫攻击?
v. 系统模型是否能够同时抵御女巫攻击和传统攻击?
所提出的方案的安全性已在以下小节中基于上述五个问题进行了分析。
6.1 | 数据机密性的安全分析
在云环境中,数据不仅要防范恶意用户,还要防范云服务提供商(CSP),因为CSP也可能利用用户的敏感数据获取收入。在所提出的方案中,用户必须满足数据拥有者设定的访问策略,才能解密加密数据。此外,用户还必须拥有数据解密密钥,才能获得原始数据。在所提出的方案中,每个授权用户都被分配一个唯一值r。如果攻击者或CSP不满足访问策略,则无法在解密过程中获得e(g, g)rs,因此他们无法从C e C;Dð Þ ¼ M:e g, gð Þrs中获取原始数据M。因此,所提出的方案保证了数据机密性。此外,在所提出的技术中,授权用户只能在其授权时段内访问敏感数据,且数据在预定义时间后会自毁。因此,数据泄露给未授权用户的概率非常低。
6.2 | 抗合谋性的安全分析
在所提出的方案中,每个用户的私钥被分配的方式使得用户无法通过合谋获取私钥。在密钥生成算法中,可信机构为不同用户生成不同的r值,从而防止攻击者和恶意用户通过合谋计算出e(g, g)rs。对于任意属性,攻击者必须使用公钥中的Di和密文中的Cx来计算e(g, g)rs。此外,解密算法不允许合并来自不同用户的r值。如果一个授权用户拥有满足秘密共享方案的足够密钥组件,并且对应相同的r值,则可以便于消除e(g, g)rs。因此,所提出的方案能够轻松抵抗合谋攻击。
6.3 | DHT网络的安全分析
在Vanish方案中,如果攻击者或黑客希望在过期时间之前获得足够的密钥份额,由于DHT网络的特性,他们将面临诸多问题。41 Zeng 等人已证明,Vanish方案无法抵御女巫攻击,即在授权时段内持续保存密钥份额。44女巫攻击主要体现在以下几个方面:
i. 跳跃攻击:在Vanish方案中,密钥分片的大小范围为16和51字节,且密钥分片的长度取决于解密密钥的长度。在此范围内,攻击者能够发起攻击并获取密钥分片以构造解密密钥。因此,这种跳攻攻击增强了女巫攻击的有效性。在Safe Vanish方案中,用户可以增加密钥分片的长度,从而提高了该方案对跳跃攻击的安全性。44在SSDD方案中,密文的长度可以增加。因此,SSDD方案也能够抵抗跳跃攻击。42在基于 IBE的自毁方案(ISS)中,通过使用IBE算法加密解密密钥,以增加密文份额的长度。45在所提出的方案中,通过使用IDTimeReEncrypt算法加密解密密钥来增加密文份额的长度。因此,所提出的方案也能够抵御跳跃攻击。
ii. 嗅探攻击:在Vanish系统中,在将密钥分片放入DHT网络之前,嗅探攻击者能够获取密钥分片以构造解密密钥。在SSDD中,攻击者能够通过使用嗅探操作获取密钥分片。因此,SSDD无法抵御嗅探攻击,用户敏感数据可能面临诸多安全问题。为解决此问题,在Safe Vanish中使用了RSA算法。44在Safe Vanish中,攻击者必须拥有接收者的私钥才能获得原始解密密钥,而该方案由于采用了公钥基础设施(PKI)方案而变得复杂。在ISS中,使用IBE算法加密解密密钥。在所提出的方案中,首先通过运行加密算法在访问树下对原始数据进行加密。为了混淆属性值,DO运行AttributeScrm算法并生成密文。然后再次对密文进行重加密。此处使用IDTimeReEncrypt算法加密解密密钥。在ISS和所提出的方案中,密文份额均通过部分密文和解密密钥的密文生成。此外,与PKI相比,IDTimeReEncrypt算法更高效且简单。因此,所提出的方案非常高效,并且能够抵御嗅探攻击。
6.4 | 加密算法的安全分析
在ISS方案、45 SSDD方案、42和Vanish系统中,41数据仅通过对称密钥进行加密。ISS方案和SSDD方案以一种各密文部分相互关联的方式对密文进行分割和提取。在所提出的方案中,原始消息被多次加密以提高安全性。首先,通过运行Encrypt算法,在访问树下对原始数据或消息进行加密。为了混淆属性值,数据拥有者运行AttributeScrm算法并生成一个密文。然后再次对该密文进行重加密,得到另一个密文。ISS方案和SSDD方案不对解密密钥进行加密,而所提出的方案使用IDTimeReEncrypt算法对解密密钥进行加密。只有拥有假名的授权用户才能向云服务提供商发送数据查询,并获得加密数据。如果没有来自IDTimeReDecrypt算法的解密密钥和完整的原始密文,则无法解密原始数据。
攻击者或黑客试图在暴力破解攻击中使用每一个可能的解密密钥来获取原始数据。ISS、SSDD和所提出的方案均涉及DataExtract算法,这使得密文不完整。因此,所有这些方案都能抵御暴力破解攻击。在Safe Vanish和Vanish方案中,整个密文被封装,因此这两种方案无法抵御暴力破解攻击。
在传统密码分析攻击中,攻击者或黑客容易获取原始数据。SSDD、ISS和所提出的方案能够抵御此类攻击。由于访问树在密文中是公开的,所提出的方案使用AttributeScrm算法对密文进行重加密,从而得到另一个密文。此外,在所提出的方案中,IDTimeReEncrypt算法对解密密钥进行加密。因此,所提出的方案比ISS和SSDD方案更安全。Safe Vanish和Vanish方案无法抵御传统密码分析攻击。
6.5 | 系统模型的安全分析
在本小节中,讨论了系统模型的安全性。在临界条件下,攻击者试图通过女巫攻击从DHT网络获取足够的密文份额,同时试图从云环境中获取 SDO。即使在此临界条件下,由于IDTimeReEncrypt算法的存在,攻击者也无法收集到足够的密文份额以获得解密密钥和密文片段。因此,攻击者无法重构原始密文并获取用户的敏感数据。此外,所提出的方案使用AttributeScrm算法来隐藏访问树的属性值,因为密文包含以明文形式存在的访问树。因此,所提出的系统模型是安全的,攻击者无法同时通过上述两种攻击手段获取原始数据。
因此,上述分析表明,所提出的方案能够抵御暴力破解、跳变和嗅探攻击。表1展示了所提出的方案与ISS方案、45 SSDD方案、42 Safe Vanish方案44以及Vanish系统41的对比。
7 | 性能分析
使用基于配对的PBC库测量了所提出的方案在封装阶段的计算开销。实验在DELL OPTIPLEX 9020台式计算机上进行,该计算机配备3.40 GHz Intel Core i7处理器、4GB内存、500GB存储容量,并运行Ubuntu 12.04.4 LTS操作系统。实验采用在有限域上的512位椭圆曲线上构造的超奇异曲线y2= x3+x上的A型配对。
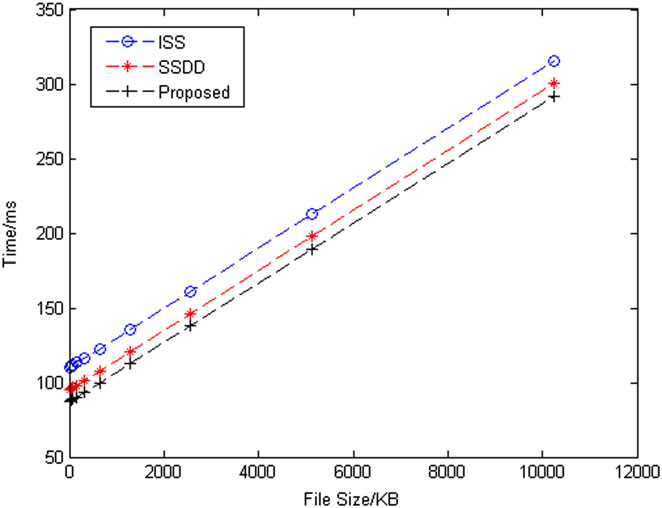
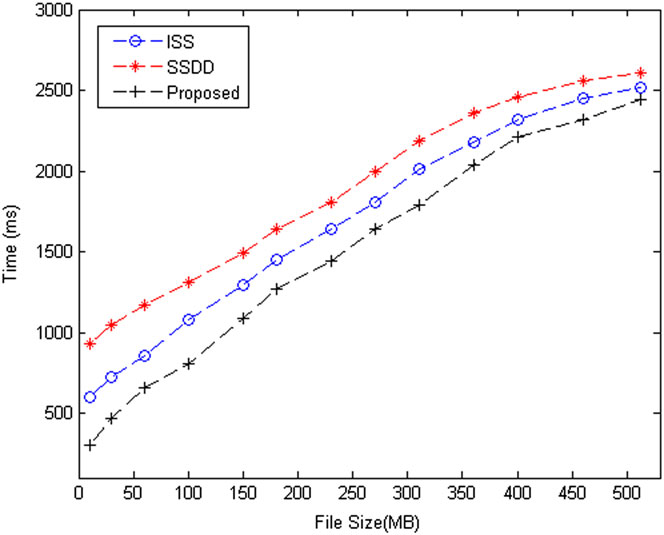
在实验过程中,所有计算均执行100次,然后取平均值。在第一次实验中,选择了十种不同大小的文件,分别为:20 KB、40 KB、80 KB、 160 KB、320 KB、640 KB、1280 KB、2560 KB、5120 KB和10240 KB。计算了ISS、SSDD和所提出的方案在封装阶段对这十种不同大小文件的计算开销,结果如图2所示。计算开销考虑了以下几项操作:数据加密、密文提取、解密密钥加密、密文份额生成以及密文份额分发。对于这些操作,SSDD、ISS和所提出的方案的计算开销几乎相同。然而,SSDD和ISS在提取密文部分之前需要与原始密文进行关联,这导致其计算开销高于所提出的方案。所有这五项操作的统计结果显示,随着文件大小和执行时间的增加,各方案的计算开销呈线性增长趋势。所提出的方案在密文提取过程中无需与原始密文关联,因此具有相对较低的计算开销。
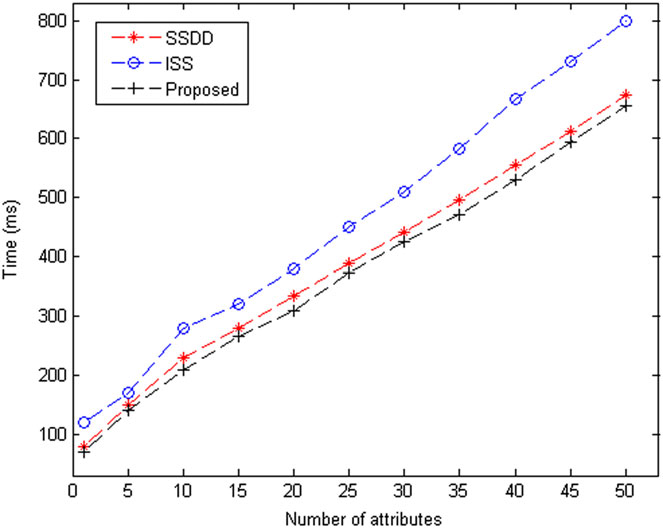
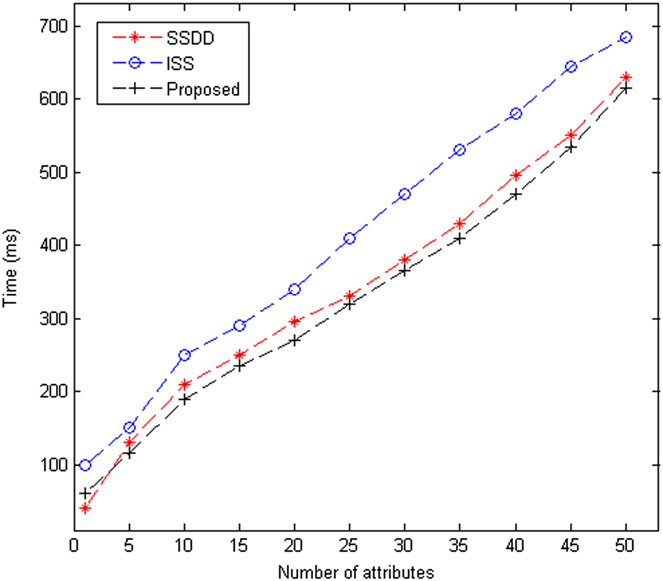
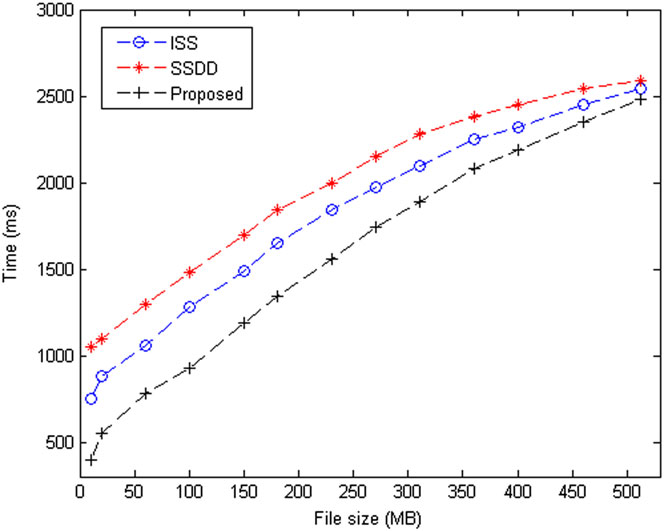
图3和图4展示了ISS、SSDD和所提出的方案在不同属性数量下的加密和解密时间结果。加密和解密时间以毫秒为单位,属性数量在1到50的范围内变化。ISS和所提出的方案均具有加密解密密钥的特性,导致两种方案的图形呈线性增长。SSDD获得的图形相较于ISS具有相对较低的加密和解密时间。图5和图6展示了针对不同文件大小的加密和解密时间结果。在加密时间方面,图形在开始时上升,随后随着文件尺寸增大呈现稳定增长。对于解密时间,也获得了相同的图形模式。公钥密码学的使用导致了这种类型的图形。
8 | 结论
本文提出了一种新颖且安全高效的方案,用于云计算环境中的资源与知识共享。所提出的方案提供了细粒度数据访问控制,并能够抵御云环境中的多种攻击。在该方案中,数据拥有者隐藏了所有属性,从而提升了云环境的安全性。此外,采用IDTRE算法对解密密钥进行加密。安全分析表明,所提出的方案可有效防御多种攻击。最后,通过使用PBC库对所提出方案的性能进行了评估。实验结果表明,所提出的方案比现有方案更加有效。然而,在该方案中,数据或资源在其预期发布时间之前无法被访问,并且在预定义的过期时间之后数据会自动销毁。因此,用户不能按自身意愿访问数据,而必须依赖数据拥有者来进行数据访问。该方案在物联网(IoT)中具有重要影响,其中大量计算设备通过网络相互连接。未来,可以将所提出的方案与其他智能技术相结合,为物联网提供高效的数据通信服务。此外,还有很大的研究空间用于开发新型授权方案,以进一步提升所提出方案的安全性。

















 2748
2748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









