







在Go语言中,字节切片和字符串的转换非常丝滑。但是你有没有想过,在强制类型转换的过程中都发生了什么,有没有内存拷贝?本文将为你解开这两个问题的答案。

有没有发生内存拷贝是很容易证明的一件事,我们可以通过下面的代码来证明这一点。
func main() {
bs := []byte{'h', 'i'}
p1 := unsafe.Pointer(&bs)
ss := string(bs)
p2 := unsafe.Pointer(&ss)
fmt.Println(p1)
fmt.Println(p2)
h1 := (*reflect.SliceHeader)(p1)
h2 := (*reflect.SliceHeader)(p2)
fmt.Println(unsafe.Pointer(h1.Data))
fmt.Println(unsafe.Pointer(h2.Data))
}
输出如下:
0xc000098420
0xc0000881e0
0xc0000a2058
0xc0000a205a
观察输出我们可以发现,无论是Header还是底层数组都变了,在转换过程中无疑是发生了内存拷贝的。
底层实现
接下来我们来看看这一过程是如何发生的,不知从哪里开始,那就祭出汇编大杀器。先写一段简单的代码:
func main() {
bs := []byte{'h', 'i'}
_ = string(bs)
}
然后通过下面的命令输出汇编代码:
go tool compile -N -l -S main.go > _output.s
打开汇编代码,找到main函数中那两行代码的位置。
0x0024 00036 (main.go:5) MOVW $0, ""..autotmp_3+46(SP)
0x002b 00043 (main.go:5) LEAQ ""..autotmp_3+46(SP), AX
0x0030 00048 (main.go:5) MOVQ AX, ""..autotmp_1+80(SP)
0x0035 00053 (main.go:5) TESTB AL, (AX)
0x0037 00055 (main.go:5) MOVB $104, ""..autotmp_3+46(SP)
0x003c 00060 (main.go:5) MOVQ ""..autotmp_1+80(SP), AX
0x0041 00065 (main.go:5) TESTB AL, (AX)
0x0043 00067 (main.go:5) MOVB $105, 1(AX)
0x0047 00071 (main.go:5) MOVQ ""..autotmp_1+80(SP), AX
0x004c 00076 (main.go:5) TESTB AL, (AX)
0x004e 00078 (main.go:5) JMP 80
0x0050 00080 (main.go:5) MOVQ AX, "".bs+88(SP)
0x0055 00085 (main.go:5) MOVQ $2, "".bs+96(SP)
0x005e 00094 (main.go:5) MOVQ $2, "".bs+104(SP)
0x0067 00103 (main.go:6) LEAQ ""..autotmp_4+48(SP), AX
0x006c 00108 (main.go:6) MOVQ AX, (SP)
0x0070 00112 (main.go:6) MOVQ "".bs+88(SP), AX
0x0075 00117 (main.go:6) MOVQ AX, 8(SP)
0x007a 00122 (main.go:6) MOVQ $2, 16(SP)
0x0083 00131 (main.go:6) PCDATA $1, $0
0x0083 00131 (main.go:6) CALL runtime.slicebytetostring(SB)
$104就是h,$105就是i。观察最后一行,我们发现调用了runtime的slicebytetostring函数,去Go源码搜索一下这个函数,源码在src/runtime/string.go中。
// slicebytetostring将字节切片转换为字符串.
// 由编译器生成并插入到代码.
// ptr是指向切片第一个字节的指针;
// n是切片长度.
// Buf是固定大小的结果缓冲区,
// 如果结果不发生逃逸,Buf就不是nil.
func slicebytetostring(buf *tmpBuf, ptr *byte, n int) (str string) {
if n == 0 {
// 证实是相对常用的情况.
// 假设你想解析出"foo()bar"的括号内的数据,
// 你找到了下标并将切片转换成字符串.
return ""
}
if raceenabled {
racereadrangepc(unsafe.Pointer(ptr),
uintptr(n),
getcallerpc(),
funcPC(slicebytetostring))
}
if msanenabled {
msanread(unsafe.Pointer(ptr), uintptr(n))
}
if n == 1 {
p := unsafe.Pointer(&staticuint64s[*ptr])
if sys.BigEndian {
p = add(p, 7)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
if buf != nil && n <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(n), nil, false)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = n
memmove(p, unsafe.Pointer(ptr), uintptr(n))
return
}
这个函数并不复杂,我们稍微分析下。
在这之前我们先处理掉if raceenabled和if msanenabled这两个分支。raceenabled和msanenabled是runtime包的两个常量,并且值都是false,因此这两个分支的代码并不会执行。
slicebytetostring函数整体分为三个部分,分别是切片长度为0、1和大于1这三种情况。
长度为0
切片长度为0的情况直接返回空字符串。
长度为1
切片长度为1的情况也是分两步,首先拿到指向字符串的指针,然后填充string结构的内容。在获取指向字符串指针的时候,是从一个数组里面获取的,避免频繁的进行小内存分配,staticuint64s定义如下:
// staticuint64s is used to avoid allocating in convTx for small integer values.
var staticuint64s = [...]uint64{
0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07,
0x08, 0x09, 0x0a, 0x0b, 0x0c, 0x0d, 0x0e, 0x0f,
0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x16, 0x17,
0x18, 0x19, 0x1a, 0x1b, 0x1c, 0x1d, 0x1e, 0x1f,
0x20, 0x21, 0x22, 0x23, 0x24, 0x25, 0x26, 0x27,
0x28, 0x29, 0x2a, 0x2b, 0x2c, 0x2d, 0x2e, 0x2f,
0x30, 0x31, 0x32, 0x33, 0x34, 0x35, 0x36, 0x37,
0x38, 0x39, 0x3a, 0x3b, 0x3c, 0x3d, 0x3e, 0x3f,
0x40, 0x41, 0x42, 0x43, 0x44, 0x45, 0x46, 0x47,
0x48, 0x49, 0x4a, 0x4b, 0x4c, 0x4d, 0x4e, 0x4f,
0x50, 0x51, 0x52, 0x53, 0x54, 0x55, 0x56, 0x57,
0x58, 0x59, 0x5a, 0x5b, 0x5c, 0x5d, 0x5e, 0x5f,
0x60, 0x61, 0x62, 0x63, 0x64, 0x65, 0x66, 0x67,
0x68, 0x69, 0x6a, 0x6b, 0x6c, 0x6d, 0x6e, 0x6f,
0x70, 0x71, 0x72, 0x73, 0x74, 0x75, 0x76, 0x77,
0x78, 0x79, 0x7a, 0x7b, 0x7c, 0x7d, 0x7e, 0x7f,
0x80, 0x81, 0x82, 0x83, 0x84, 0x85, 0x86, 0x87,
0x88, 0x89, 0x8a, 0x8b, 0x8c, 0x8d, 0x8e, 0x8f,
0x90, 0x91, 0x92, 0x93, 0x94, 0x95, 0x96, 0x97,
0x98, 0x99, 0x9a, 0x9b, 0x9c, 0x9d, 0x9e, 0x9f,
0xa0, 0xa1, 0xa2, 0xa3, 0xa4, 0xa5, 0xa6, 0xa7,
0xa8, 0xa9, 0xaa, 0xab, 0xac, 0xad, 0xae, 0xaf,
0xb0, 0xb1, 0xb2, 0xb3, 0xb4, 0xb5, 0xb6, 0xb7,
0xb8, 0xb9, 0xba, 0xbb, 0xbc, 0xbd, 0xbe, 0xbf,
0xc0, 0xc1, 0xc2, 0xc3, 0xc4, 0xc5, 0xc6, 0xc7,
0xc8, 0xc9, 0xca, 0xcb, 0xcc, 0xcd, 0xce, 0xcf,
0xd0, 0xd1, 0xd2, 0xd3, 0xd4, 0xd5, 0xd6, 0xd7,
0xd8, 0xd9, 0xda, 0xdb, 0xdc, 0xdd, 0xde, 0xdf,
0xe0, 0xe1, 0xe2, 0xe3, 0xe4, 0xe5, 0xe6, 0xe7,
0xe8, 0xe9, 0xea, 0xeb, 0xec, 0xed, 0xee, 0xef,
0xf0, 0xf1, 0xf2, 0xf3, 0xf4, 0xf5, 0xf6, 0xf7,
0xf8, 0xf9, 0xfa, 0xfb, 0xfc, 0xfd, 0xfe, 0xff,
}
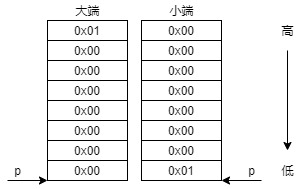
如果是大端序系统,还要对p进行偏移,因为通过staticuint64s拿到的是uint64类型,在大端序系统上,p指向的是高位字节,偏移7位后才是我们想要的字节。add函数只是将unsafe.Pointer转换成uintptr做加法,然后再转回unsafe.Pointer类型,这也是Go语言做指针运算的通用方式。关于大端序和小端序的理解,可以参考大端,小端,go这篇文章。我们以0x01为例,内存布局如下。
stringStructOf函数将指针转化成*runtime.stringStruct结构体指针,stringStruct就是字符串的底层表示,结构如下。
type stringStruct struct {
str unsafe.Pointer
len int
}
注意它和reflect.StringHeader的区别,这一点很重要。
长度大于1
长度大于1的情况会用到新分配的空间buf,如果buf空间不够,就会通过mallocgc再去申请内存。然后会填充字符串结构体,最后通过memmove函数将切片的内容拷贝到新的内存。
0内存转换
通过以上的分析,我们可以确定Go语言内置的类型转换在将字节切片转成string类型时是会发生内存拷贝的。出于性能的考虑,有时我们希望转换的过程中不要发生内存拷贝,下面我们就来实现0内存拷贝的转换。
错误示范
首先我们来看一个直觉上可行但实际是错误的实现,我们主要是要弄明白它为什么是错误的。
func slicebyte2string_wrong(bs []byte) string {
h := (*reflect.SliceHeader)(unsafe.Pointer(&bs))
s := reflect.StringHeader{
Data: h.Data,
Len: h.Len,
}
return *(*string)(unsafe.Pointer(&s))
}
为了证明它是不对的,我们写一段验证函数。
func main() {
ss := testByteSliceToString()
runtime.GC()
println(ss)
}
func testByteSliceToString() string {
bs := []byte{'h', 'i'}
return slicebyte2string_wrong(bs)
}
观察输出看不到任何内容,因为bs的内存被GC回收了,究其原因,其实和reflect.StringHeader的结构有关。
type StringHeader struct {
Data uintptr
Len int
}
注意和前面的runtime.stringStruct结构进行对比,区别就在于Data字段的类型。uintptr本质上是数字类型,它的特殊之处在于可以和unsafe.Pointer类型互相转换。因此GC并不会将uintptr类型当作指针处理。
正确示范
下面是正确示范,虽然我们没法直接使用runtime.stringStruct结构体,但是我们可以定义string类型变量间接拿到这个结构体。
func slicebyte2string(bs []byte) (ss string) {
h := (*reflect.SliceHeader)(unsafe.Pointer(&bs))
sh := (*reflect.StringHeader)(unsafe.Pointer(&ss))
sh.Data = h.Data
sh.Len = h.Len
return
}
还是使用上面的测试代码,这次就能看到hi被打印出来了。
func main() {
ss := testByteSliceToString()
runtime.GC()
println(ss)
}
func testByteSliceToString() string {
bs := []byte{'h', 'i'}
return slicebyte2string(bs)
}
性能测试
我们以1K字节的切片做一个简单的Benchmark。
package main
import (
"testing"
)
var bs = []byte{1024: 'a'}
func BenchmarkBuiltinSlicebytetostring(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = string(bs)
}
}
func BenchmarkSlicebyte2string(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = slicebyte2string(bs)
}
}
结果如下:
goos: windows
goarch: amd64
pkg: slice2string
BenchmarkBuiltinSlicebytetostring-12 6468879 189 ns/op
BenchmarkSlicebyte2string-12 1000000000 0.235 ns/op
PASS
ok slice2string 2.175s
















 1029
1029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









