







1.Monitoring Errors and Alerts
这一节主要介绍如何监控Oracle的错误和警报,分2个方面讲述。
1.1Monitoring Errors with Trace Files and the Alert Log
所谓的Trace Files是用于记录进程的错误信息,每个Server和进程都会把其遇到的内部错误写进各自的Trace File里,Trace File的文件格式是:SID-ORA-PID。
Alert Logs是个按时间顺序记录消息和错误的日志,它包括以下方面:
1). 所有的内部错误(ORA-600), 块损坏(Block Corruption Error, ORA-1578),死锁(Deadlock Error, ORA-60)。
2). 管理操作(Administrative operations)
3). 由共享服务器和分发进程(Dispatcher Process)产生的信息或错误。
4). 实体化视图(Materialized View)自动刷新说产生的错误。
5). 在instance启动时,所有使用非默认值的参数都会被记下。
后台进程和共享服务器的Alert Log和Trace File都会写到自动诊断仓库(Automatic Diagnostic Repository)里,自动诊断仓库的存储位置由参数DIAGNOSTIC_DEST指定。
参数MAX_DUMP_FILE_SIZE是用来指定Trace File的最大值,包括Alert Log。
可以设SQL_TRACE = TRUE去追踪SQL的执行效率统计等信息,也可以只对某个Session进行统计,用语句:
ALTER SESSION SET SQL_TRACE TRUE;
为了帮助用户追踪trace file 的信息,oracle还提供了一个工具:trcsess。没用过。。
1.2Monitoring Database Operations with Server-Generated Alerts
只有比较严重的Alert Message可以有幸被送到预设的Alert_Que 队列中,这个队列是属于SYS用户的。其他的都会被写到Alert Log里。
可以通过参数设定Alert的不同阈值,当某个参数超过阈值就产生Alert. 看下面的实例:
DBMS_SERVER_ALERT.SET_THRESHOLD(
DBMS_SERVER_ALERT.CPU_TIME_PER_CALL, DBMS_SERVER_ALERT.OPERATOR_GE, '8000',
DBMS_SERVER_ALERT.OPERATOR_GE, '10000', 1, 2, 'inst1',
DBMS_SERVER_ALERT.OBJECT_TYPE_SERVICE, 'main.regress.rdbms.dev.us.oracle.com');
该命令是当每个用户调用的CPU使用时间超过8000微秒是就产生一条Warning Alert, 超过10000微秒产生一条Critical Alert。
可以用GET_THRESHOLD存储过程去获得阈值信息。这个东东太长,现在先不研究。
最简单的查看Alert信息的是用Enterprise Manager,也可以自己预订Alert_Que去查看,比较麻烦。
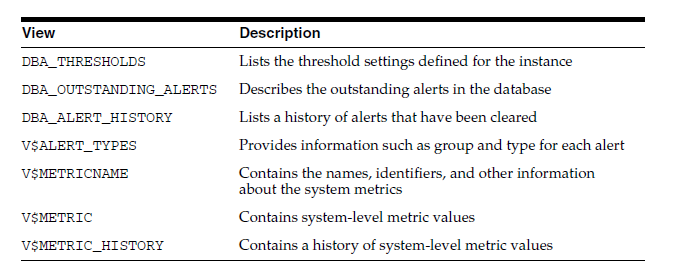
表1. Server-Generated Alerts Data Dictionary Views
2.Monitoring Performance
2.1Monitoring Locks
Oracle提供了2个Script去监控,首先使用catblock.sql, 再使用utllockt.sql。utllockt.sql是用来显示当前session那些在等待locks和那些locks他们在等待,而前面那个scripts是用来建立utllockts.sql所需的views的,所以要先运行。
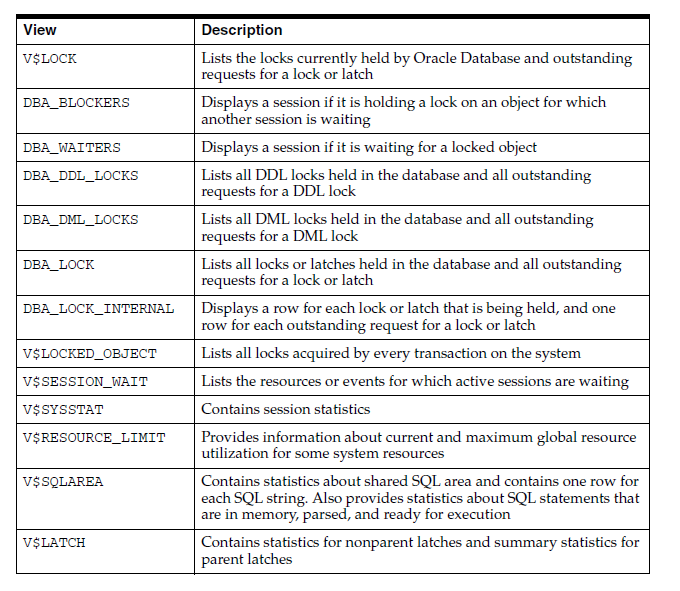
表2. Performance Monitoring Data Dictionary Views















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









