










环境配置:
Scala:2.11.12(看上篇,原本是2.12.1)
Spark:2.4.4
Hbase:2.2.3
前言:
上一篇没报错,后来改动了一下,就报错了,这个错是版本的问题,而且让我十分疑惑,所以有了下篇,好像也没啥人看,随便写写吧就😂
代码:
先上代码
import java.util.Date
import org.apache.hadoop.hbase.client.{Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.{SparkConf, SparkContext}
object sparkHbaseWrite {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
val sc = new SparkContext(sparkConf)
val tablename = "test"
// hbase 的连接设置
val hconf = sc.hadoopConfiguration
hconf.set("hbase.zookeeper.property.clientPort","2181")
hconf.set("zookeeper.znode.parent","/hbase-unsecure")
hconf.set("hbase.zookeeper.quorum","192.168.0.111")
hconf.set(TableOutputFormat.OUTPUT_TABLE,tablename)
val job = Job.getInstance(hconf)
job.setOutputKeyClass(classOf[ImmutableBytesWritable])
job.setOutputValueClass(classOf[Result])
job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
val gpsRDD = sc.textFile("file:///home/data/demodata").map(_.split("\\|"))
val now = new Date()
val timeStr = now.getTime + ""
val gpsRDD1 = gpsRDD.map{arr=>{
val put = new Put(Bytes.toBytes(timeStr + arr(2))) //行健的值 本来想自定义一个,还没设计好,就随便拼一个先,反正能写进去先才是第一步
put.addColumn(Bytes.toBytes("car_info"),Bytes.toBytes("PLA"), Bytes.toBytes(arr(0)))
put.addColumn(Bytes.toBytes("car_info"),Bytes.toBytes("DATE_TIME"),Bytes.toBytes(arr(1)))
put.addColumn(Bytes.toBytes("car_info"),Bytes.toBytes("KKJ"),Bytes.toBytes(arr(2)))
put.addColumn(Bytes.toBytes("car_info"),Bytes.toBytes("KKW"),Bytes.toBytes(arr(3)))
put.addColumn(Bytes.toBytes("car_info"),Bytes.toBytes("SPEED"),Bytes.toBytes(arr(4)))
put.addColumn(Bytes.toBytes("car_info"),Bytes.toBytes("SPEED_EX"),Bytes.toBytes(arr(5)))
put.addColumn(Bytes.toBytes("car_info"),Bytes.toBytes("ALTITUDE"),Bytes.toBytes(arr(6)))
put.addColumn(Bytes.toBytes("car_info"),Bytes.toBytes("STATUS"),Bytes.toBytes(arr(7)))
put.addColumn(Bytes.toBytes("car_info"),Bytes.toBytes("COLOUR"),Bytes.toBytes(arr(8)))
put.addColumn(Bytes.toBytes("car_info"),Bytes.toBytes("MILEAGE"),Bytes.toBytes(arr(9)))
put.addColumn(Bytes.toBytes("car_info"),Bytes.toBytes("WAY"),Bytes.toBytes(arr(10)))
(new ImmutableBytesWritable, put)
}}
gpsRDD1.saveAsNewAPIHadoopDataset(job.getConfiguration)
sc.stop()
}
}
打包好然后报了个错:
scala.Predef$.refArrayOps([Ljava/lang/Object;)Lscala/collection/mutable/ArrayOps;
报错的是这一行:
val gpsRDD = sc.textFile("file:///home/data/demodata").map(_.split("\\|"))
首先语法是肯定没错的,排除代码原因。
然后报错意思说我版本对不上,可是我idea和集群环境是一样的啊,不可能是编译的语言版本不一致导致的,所以排除这个原因。
然后再百度了一下,网上说是因为我们使用的spark-core_2.11是使用scala 2.11编译的,所以,如果我们使用其他版本的scala编译我们的代码就有可能报这样的错。
查了一下,包的名字是写明了版本的例如:spark-core_2.11-2.4.4.jar ,2.11指的是scala的版本,2.4.4指的是spark的版本。
所以为了想知道哪个版本最适合spark2.4.4,我就去官网查查看,结果看的我一愣一愣的(下面的内容使用了谷歌翻译)

所以是只有spark2.4.2用了scala2.12?再看看

那为啥我用scala2.12会冲突。。。再看看那些包

在我去掉原本spark中的scala环境,用默认环境打开spark-shell,看到这个

所以我把scala版本换了重新编译(pom配置上篇文章有,我改个版本而已)
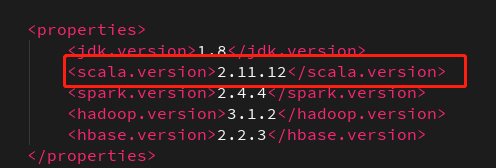
就跑通了。。。所以上面官网的提示是啥意思?😥















 4272
4272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









