






下面我们将延续着LangChain的课程,来为大家讲述一下这门在DeepLearning.AI上的经典课程——“LangChain for LLM Application Development”,来让我们学习一下如何来基于LangChain来进一步进行我们大模型的开发工作。
由于同属于LangChain这个框架的学习与应用,因此课程的内容可能会与上一门课程有些许的重合,因此这里我们将选择性的跳过部分重合的内容,尽可能将主要的功能向大家进行展示。另外,在官方课程中,主要选用的模型都是OpenAI系列的模型,由于某些特殊的原因,我们暂时无法使用这些模型,那么我也会选择一些可替代的模型来为大家进行演示,所以话不多说,我们赶快来开始我们的课程吧!
内容简介
在这们课程中,将会重点讲述以下部分的内容:
1. Models(模型):
课程将介绍多种模型的整合与应用,其中包括支持超过20种整合的LLMs(大语言模型)、聊天模型以及支持10余种整合的文本嵌入模型。这些模型为实现不同任务提供了基础支持,帮助学生深入理解模型的能力和适用场景。
2. Prompts(提示):
重点学习提示的设计和优化,包括提示模板的创建和使用。课程还将涵盖输出解析器的实现(超过5种),并特别介绍如何通过重试和逻辑修复来改进解析。此外,还会探索示例选择器的多种实现,帮助学员掌握提示与任务对接的技巧。
3. Indexes(索引):
学员将学习文档加载器的多种实现(超过50种)以及文本分割技术(超过10种实现)。课程还将介绍向量存储整合(10余种)以及检索器的实现(超过5种),以提升大规模数据处理的效率。
4. Chains(链):
课程将讲解如何将提示、大语言模型和输出解析组合成完整的处理链,并将其作为构建更长链条的基础模块。同时,还会介绍20多种特定应用场景的处理链,帮助学员掌握在复杂场景下的链式处理方法。
5. Agents(代理):
代理部分涵盖5种以上的代理类型以及大语言模型使用工具的算法。此外,课程还涉及代理工具包的设计与实现(超过10种),帮助学员学习如何为特定应用场景配备合适的工具,打造高效的自动化代理。
通过以上内容,大家将系统掌握模型、提示、索引、链与代理的核心知识与应用技能,为未来的实践和研究奠定坚实基础。

1.用LangChain打造专属于你的LLM应用:模型、提示词与结构化输出全解析
1.1. 大模型应用简介
对于LLM应用的开发而言,其中必不可少的就是要有一个适合你任务场景的大模型了。这个大模型不限于说是你自己本地运行的,还是说自己部署在服务器上调用的,甚至是说单纯通过api去调用的,这些都是ok没问题的。虽然我们国内很难直接用Claude、ChatGPT、Gemini等最先进的大模型,但是我们本土公司所制作的模型对于绝大部分的应用场景其实都是够用的,并且其中文能力也可能相对而言会强一些。比如说国内的公司像通义千问、书生浦语、百川、天工、豆包等等大模型都已经有很强的能力了,我们都可以尝试来进行使用。
那使用的方式呢其实也有很多种,一种方法是直接去这些官网申请api_key然后学习他们的调用方式一个个来进行调用。还有一种更简便的方法其实就是说在一些大模型整合的平台上去使用,这种方法的好处在于我们只需要修改一下调用模型的名称就可以进行调用了,而不需要说我要更换模型的时候我再申请key再学习接口调用的方法,这能够极大地减轻初始的学习成本。
但是到后期稳定使用的时候,就会出现一些问题,比如说这些平台会限速,就是说相比于你直接调用官方的api,使用平台上的通用api的方式回复会相对慢一些。而对于效率至上的我们而言可能在上线实际操作的时候会比较难以接受。因此我觉得在前期测试的时候使用平台是非常好的事情,但是到了后期稳定使用的时候,最好还是通过官方的方式进行调用。
国内比较大的LLM调用平台其实就是“硅基流动”了,当然国外也有很多这样的平台,比如AWS、Arzue等等。我们在上面不仅仅能够获取到文本生成的模型,还能够调用到一些图片生成、代码生成向量与重排序模型以及多模态大模型。我们可以根据以下的链接去学习使用硅基流动的调用方式。
💡
快速上手 - SiliconFlow
那由于我们这节课是基于LangChain来讲述的,而硅基流动和LangChain官方目前还并未能够做到直接连通,我们就主要使用一些官方支持的模型进行测试使用,比如百川大模型、通义千问智谱的ChatGLM来进行演示。当然我们可以通过自己Custom LLM进行实现,比如在CSDN上的LJY_LU便发布了其封装好的代码,大家也可以点击下方的链接进行查询了解、
💡
Langchain如何调用Siliconflow的模型_langchain silicon-CSDN博客
那在课程正式开始之前,我们可以先了解学习一下,我们开发者是如何开始使用大模型的!
1.2. 通义千问大模型调用实战
1.2.1. api_key的获取
那对于任何一个大模型来说,我们假如是希望通过网络上直接进行调用,都必不可少的一个步骤就是申请一个api_key。那这个密钥类似于一把“钥匙”,只有持有者可以合法地调用该服务。其作用就是:
- 验证你的身份:告诉服务提供商你是谁。
- 控制访问权限:决定你能使用哪些功能,或者调用的次数是否受限。
- 计费依据:服务商会根据你的 API 调用量来收费,API Key 是用来追踪这些调用的。
那为了能够申请到一个通义千问的api_key,我们首先需要注册或登录阿里云百炼大模型服务平台(阿里云登录页)。在进入界面后我们需要点击上方的开通服务按钮。
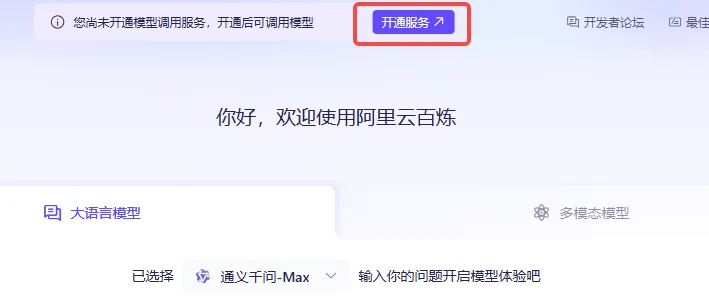
然后点击同意并确认开通即可。

假如弹出这个窗口就意味着我们的阿里云账户上一分钱都没有,那我们可能就需要先充值几块钱进去然后再进行调用。

比如说我就充了5块钱hhh。
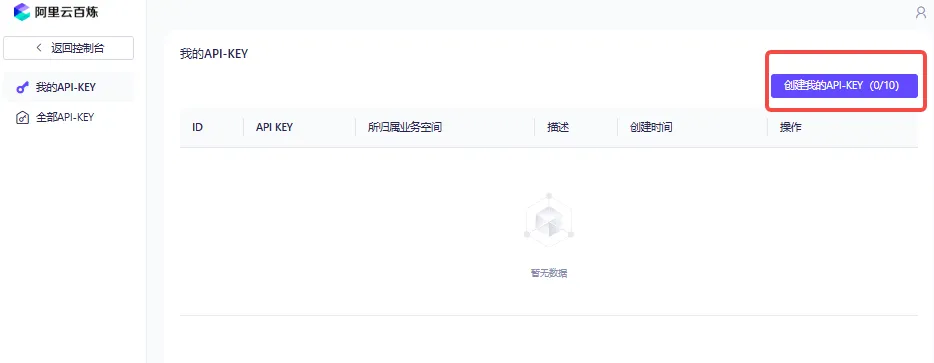
然后我们再次点击开通服务,便会显示开通成功的字样。接下来我们找到右上角的用户按钮,然后点击进入API-KEY。

点击创建我的API-KEY。
输入名称和归属业务空间等基本信息后。
便可点击查看并复制我们的API KEY了。

1.2.2. 开发环境准备
在获取了api_key后,接下来我们就需要着手来准备我们的一个开发环境。首先我们可能需要安装两个重要的东西,一个是Anaconda——环境管理工具,另外一个就是VSCode或者PyCharm这类代码编辑器。在开发过程中,Anaconda 是一个强大的环境管理工具,它可以帮助我们创建和管理多个独立的 Python 环境,避免因为不同项目依赖冲突而导致的问题,同时内置了常用的科学计算和机器学习库,方便快速配置开发环境。而 VSCode 或 PyCharm 是主流的代码编辑器/IDE,提供了强大的代码编写、调试、自动补全和插件扩展功能,能显著提高代码开发效率和质量。这两者结合,可以为我们提供一个高效、稳定且易用的开发环境。
那关于这些工具的安装方面,在B站上有大量的视频讲述两者的安装以及连接部分的内容,这里我就不进行演示了。大家从里面挑些免费的简单的学习即可。
大家只要能够通过以下的代码创建好一个环境并且能够在终端运行代码即为完成环境安装的条件。
conda create -n LangChain_Learning python=3.10 -y
conda activate LangChain_Learning
这样我们就可以从原本的base环境切换为LangChain_Learning这个环境了。

然后我们就可以往里面安装一些库了,那具体安装哪些库的话,我们可以回到阿里云百炼的主界面里点击上方的产品文档就能看到使用python的调用示例。

import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如何获取API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-plus", # 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '你是谁?'}
]
)
print(completion.choices[0].message.content)
从上面这个代码就可以看出,由于百炼兼容OpenAI接口规范,因此我们其实仅需要下载一个openai的库即可,那大家可以在下方输入以下代码(由于openai库也在更新当中,那为了后续的复现,这里我就设定了版本)。
pip install openai==1.58.1
过一段时间后,我们就可以看到环境已经安装好了,然后我们就可以在原路径上创建一个qwen_test.py文件并把代码进行写入。并将api_key=os.getenv("DASHSCOPE_API_KEY") 中后面的部分替换为你的api_key的内容,比如说api_key='sk-63f00f6776fd4f64b197e 这样。然后我们就可以在终端运行一下代码。
python qwen_test.py
然后我们就可以看到终端的回复。那这样我们就成功配置好环境可以运行大语言模型了!

1.2.3. 大语言模型系统分析
在运行成功后,我们可以详细解析其实现过程。首先,在 client 变量中传入自己的 api_key 和 url,完成了对接阿里云兼容模式的接口配置。接下来,通过调用 client.chat.completions.create() 方法,定义了大模型的角色和用户输入信息。在代码中,system 角色被设置为 “You are a helpful assistant”(你是一个有用的助手),而用户的输入内容是“你是谁”。这样,代码意在让大语言模型以“有用助手”的身份回答“你是谁”这个问题。最后,通过解析 completion.choices[0].message.content,可以提取模型的输出。从示例中可以看到,模型给出的回答为“我是阿里云开发的一款超大规模语言模型,我叫通义千问”,这正是对用户提问的具体响应。
import os
from openai import OpenAI
client = OpenAI(
api_key='sk-63f00f6776fd4f64b197ea', # 替换自己的api_key
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-plus",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '你是谁?'}
]
)
print(completion.choices[0].message.content)
从这里我们可以看出,如果希望基于大语言模型进行开发,有两件事是至关重要的:一是为大语言模型赋予合适的角色,二是明确用户输入的提示词。提示词这个概念大家可能已经比较熟悉了——我们日常与各种大语言模型互动时,输入的内容其实都可以归为提示词的一种。而 system 部分相对较少被直接接触,但它对大语言模型的输出影响却非常显著。例如,如果将 system 的内容从“你是一个有用的助手”改为“你是一个顽皮捣蛋的小助手”,在同样的“你是谁”问题下,模型的回答也会变成一个完全不同的风格。

由此可以看出,system 的设置在很大程度上决定了模型的认知状态及其回复风格。如果我们希望模型适用于严肃场景,就需要根据具体需求在 system 中进行相应的调整。
当然,除了在 system 中进行调整,我们也可以通过提示词来影响模型的认知。例如,将用户的输入改为“假设你是一个顽皮捣蛋的小助手,请你回答一下你是谁?”,那么模型的回复风格也会变得与之前截然不同,显得更加俏皮。这表明提示词在一定程度上也能够影响大模型的行为和表现。

总结来说,system 的设置更像是给大语言模型制定了“人格基调”,它对模型的认知改变是深层次和根本性的;而提示词更像是在与模型“对话”中试图说服它改变行为,影响相对表层但也能起到一定的作用。两者配合使用,才能让模型更好地适应不同场景的需求。
1.2.4. 提示词设置
虽然系统的设置很重要,但是提示词在大语言模型的开发中至关重要,它相当于用户与模型之间的“指令”,直接影响模型的输出质量和风格。通过设计明确而精准的提示词,开发者可以引导模型的回答方向、优化结果质量、激发模型潜能,并适配不同场景需求。相比于 system 的深层设置,提示词更加灵活,能够实时调整模型的表现,是调控和提升模型交互效果的高效手段。因此下面我们来讲讲我们该如何设计我们的提示词。
设置提示词的一个最关键的思想就是把问题讲清楚,比如说我希望把一篇文章转化成某种风格, 那我们就需要清晰直接明了的告诉大模型说——请把xxx内容修改为xxx格式这样。假如你自己都没想清楚自己要做成什么样子,那我的建议是你先找个牛点的大模型先对话对话,找他剖析一下你的内心到底真实的需求到底是什么样的,又或者是找个朋友聊聊看。只有把问题说清楚了,后续的工作才是有价值有意义的。
在代码层面,我们可以通过 Python 的 f-string 方法来分门别类并清晰表达信息。以下是一个示例:
customer_email = """
嗨,我非常生气,我的搅拌机盖子飞了出去,把我的厨房墙壁弄得都是奶昔!
更糟糕的是,保修不包括清理厨房的费用。我现在需要你的帮助,伙计!
"""
style = "语气平和且尊重"
prompt = f"""将以下用三重反引号括起来的文本翻译成另外一种风格为{style}的文本用于投诉。
文本: ```{customer_email}```
"""
print(prompt)
通过 f-string,将 customer_email 和 style 组合在一起生成完整的提示词,并将其赋值给变量 prompt。随后,我们将其传递给 user 的内容中:
import os
from openai import OpenAI
customer_email = """
嗨,我非常生气,我的搅拌机盖子飞了出去,把我的厨房墙壁弄得都是奶昔!
更糟糕的是,保修不包括清理厨房的费用。我现在需要你的帮助,伙计!
"""
style = "语气平和且尊重"
prompt = f"""将以下用三重反引号括起来的文本翻译成另外一种风格为{style}的文本用于投诉。
文本: ```{customer_email}```
"""
client = OpenAI(
api_key='sk-63f00f6ed5edf197ea',
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-plus",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': prompt} # 传入提示词
]
)
print(completion.choices[0].message.content)
最终,我们可以生成一封平和且清晰的投诉信,内容如下:
您好,尊敬的客服团队:
您好,
我最近在使用搅拌机时遇到了一些问题,盖子意外飞出,导致厨房墙壁上溅上了奶昔。此外,我发现保修条款中并未涵盖清理费用。希望您能理解这一情况给我带来的不便,因此我想请求您的帮助,寻求一个合理的解决方案。
感谢您的关注和支持。
此致
敬礼
从这里我们可以看出,通过合理设计提示词,我们可以高效地引导模型生成符合预期的结果。这种方法不仅可以动态调整模型的行为,还能够提升交互的灵活性和效果。提示词的设计不仅仅是简单的输入,而是一门结合语言表达与技术实现的艺术,值得开发者深入探索和实践。
1.3. 基于LangChain的大模型应用实践
既然我们仅仅基于通义千问官方的api结合开源的openai库就能够实现模型的输入及回复,相信大家可能会有一个疑问,那就是LangChain本身给我们带来了什么价值呢?那下面我们就带着大家来回答一下,为什么我们需要LangChain来进行开发工作呢?
1.3.1. 环境安装
那在开始讲述LangChain的用处之前,最基本的还是把LangChain给安装上。我们可以通过在终端输入以下代码进行LangChain的下载。
pip install --upgrade langchain
1.3.2. 模型调用
当我们有了LangChain以后,我们会发现我们不再需要官方这种繁琐且复杂的调用方式了,我们只需要载入根据Tongyi Qwen在LangChain(Tongyi Qwen | 🦜️🔗 LangChain)的官方文档要求进行调用即可。
那首先第一步就是安装相关的库。
# Install the package
pip install --upgrade --quiet langchain-community dashscope
接下来,只需设置 api_key,即可直接调用模型,非常简洁高效:
import os
from langchain_community.llms import Tongyi
os.environ["DASHSCOPE_API_KEY"] = 'sk-63f00fedf197ea'
print(Tongyi().invoke("你是谁?"))
或者说以下面更简洁的方式进行调用:
from langchain_community.llms import Tongyi
print(Tongyi(api_key='sk-63f00fed5edf197ea').invoke('你是谁?'))
运行上述代码后,模型会正确返回回复:

通过对比可见,相较于之前需要二十多行代码才能完成调用的繁琐方式,使用 LangChain 后仅需几行代码即可完成相同的任务。由此可见,LangChain 带来的第一个显著价值就是 显著简化调用流程,提高开发效率。它让复杂的集成过程变得直观高效,为开发者节省了大量时间和精力。
想要更进一步学习了解Tongyi()内部构造的话,我们可以进入官方文档langchain_community.llms.tongyi.Tongyi — 🦜🔗 LangChain 0.2.17进行查阅。
但是使用这个方式有一个小问题,就是通过 langchain_community.llms 导入的 Tongyi 模型是 LangChain 针对通义千问(Qwen)作为语言模型(LLM)的封装,主要用于处理独立的文本输入和生成任务。它非常适合单一文本输入和输出的场景,例如文章生成、文本补全等静态任务。
然而如果我们需要与模型进行多轮交互,则需要使用 langchain_community.chat_models.tongyi 中的 ChatTongyi。ChatTongyi 是 LangChain 针对通义千问作为**聊天模型(Chat Model)**的封装,其相比于上面的方法支持上下文交互和多轮对话功能,非常适合用于需要持续对话的场景,例如客服机器人、多轮问答以及复杂的情景模拟任务。
具体的使用方式如下代码所示:
import os
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage
# 设置 API 密钥
os.environ["DASHSCOPE_API_KEY"] = 'sk-63f4f64beb06ed5edf197ea'
# 初始化 ChatTongyi 模型
chat_model = ChatTongyi()
# 创建用户消息
user_message = [
SystemMessage(content='你是一个友好的助手'),
HumanMessage(content="你是谁?")
]
# 获取模型回复
response = chat_model.invoke(user_message) # 直接传递消息列表
# 输出回复内容
print(response.content)
这个方法与我们直接调用千问模型的方式非常相似。ChatTongyi 支持通过 SystemMessage 定义系统角色(类似于前面的system),同时通过 HumanMessage 定义用户输入内容(类似于前面的user)。该灵活设计使得开发者可以在多轮交互中更好地控制对话逻辑和上下文。
当然我们也可以进入官方文档(ChatTongyi — 🦜🔗 LangChain documentation)中了解更多关于ChatTongyi方面的信息。由于本课程涉及多轮对话相关内容,后续我们会使用 ChatTongyi 替代 OpenAI 的模型来进行演示,以便更直观地展示其在复杂对话场景中的优势和应用。
1.3.3. 提示词模版
除了模型调用更加方便以外,LangChain还提供了一个很重要的功能就是提示词模版。通过提示词模版,我们可以动态生成适配不同场景和需求的提示文本,从而极大地提升开发效率和文本生成的灵活性。

下面我们以代码为例,详细讲解如何使用提示词模版。
prompt = f"""将以下用三重反引号括起来的文本翻译成另外一种风格为{style}的文本用于投诉。
文本: ```{customer_email}```"""
上面这个前面提到过的代码片段通过f-string插值的方式,定义了一个简单的提示词。虽然可以满足基本需求,但如果需要在多个场景复用或动态调整提示内容,这种方式显得不够灵活。为了解决这个问题,我们可以利用LangChain提供的 ChatPromptTemplate。
- 使用
ChatPromptTemplate创建动态提示词模版
在LangChain中,ChatPromptTemplate 是用于创建结构化提示词的工具。它支持我们定义带有占位符的模版,并在需要时动态替换这些占位符。简而言之就是把我们原本f-string里的变量名称都转为一个列表,然后我们后续只需要按顺序传入信息即可。
以下是一个使用 ChatPromptTemplate 的示例:
from langchain.prompts import ChatPromptTemplate
# 定义提示词模版字符串
template_string = """将以下用三重反引号括起来的文本翻译成风格为 {style} 的文本。\\n文本: ```{text}```"""
# 创建 ChatPromptTemplate 实例
prompt_template = ChatPromptTemplate.from_template(template_string)
# 查看模版中的输入变量
print(prompt_template.messages[0].prompt.input_variables) # 输出: ['style', 'text']
上述代码通过 from_template 方法生成了一个带有两个占位符 style 和 text 的模版字符串。这个模版能够动态替换占位符,从而实现提示词的高度定制化。使用提示词模版,我们可以通过 format_messages 方法动态替换模版中的占位符,并生成适配具体需求的消息。例如:
# 定义客户的投诉风格和文本
customer_style = """语气平和且尊重"""
customer_email = """
啊,我的搅拌机盖子飞了出去,把我的厨房墙壁弄得满是奶昔!更糟糕的是,保修不包括清理厨房的费用。我现在需要你的帮助,伙计!
"""
# 使用模版格式化消息
customer_messages = prompt_template.format_messages(
style=customer_style,
text=customer_email
)
# 打印生成的消息类型和内容
print(type(customer_messages)) # 输出: <class 'list'>
print(type(customer_messages[0])) # 输出: <class 'langchain.schema.HumanMessage'>
在上述代码中,format_messages 方法将 customer_style 和 customer_email 填充到模版中的 style 和 text 占位符中,生成了一个包含格式化内容的消息列表。同时我们也可以看到说这个customer_messages[0]打印出来的类型是HumanMessage的类型,因此我们其实也可以在此基础上将其与SystemMessage进行整合然后整体的进行使用。比如说下面这个例子:
customer_messages = prompt_template.format_messages(
style=customer_style,
text=customer_email
)
user_message = [
SystemMessage(content='你是一个友好的助手'),
customer_messages[0]
]
我们可以随时修改SystemMessage的content以及customer_sytle和customer_email的内容和信息并得到个性化的回复。
- 调用语言模型处理消息
最后,生成的消息可以直接传递给语言模型(LLM)进行处理。当然这个在此之前,我们先需要按照上面的步骤进行chat_model的设置。模型会根据生成的提示词返回对应风格的翻译结果。
# 调用LLM翻译客户消息
customer_response = chat_model(customer_messages)
print(customer_response.content) # 输出翻译后的文本
最终完整的代码如下所示:
import os
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage
from langchain.prompts import ChatPromptTemplate
# 设置 API 密钥
os.environ["DASHSCOPE_API_KEY"] = 'sk-63f00f6776fd5edf197ea'
# 初始化 ChatTongyi 模型
chat_model = ChatTongyi()
# 定义提示词模版字符串
template_string = """将以下用三重反引号括起来的文本翻译成风格为 {style} 的文本。\\n文本: ```{text}```"""
# 创建 ChatPromptTemplate 实例
prompt_template = ChatPromptTemplate.from_template(template_string)
# 查看模版中的输入变量
print(prompt_template.messages[0].prompt.input_variables) # 输出: ['style', 'text']
print(type(customer_messages[0])) # 输出: <class 'langchain.schema.HumanMessage'>
# 定义客户的投诉风格和文本
customer_style = """语气平和且尊重"""
customer_email = """
啊,我的搅拌机盖子飞了出去,把我的厨房墙壁弄得满是奶昔!更糟糕的是,保修不包括清理厨房的费用。我现在需要你的帮助,伙计!
"""
# 使用模版格式化消息
customer_messages = prompt_template.format_messages(
style=customer_style,
text=customer_email
)
user_message = [
SystemMessage(content='你是一个友好的助手'),
customer_messages[0]
]
# 调用LLM翻译客户消息
customer_response = chat_model.invoke(customer_messages)
print(customer_response.content) # 输出翻译后的文本
总的来说,提示词模版的使用让自然语言生成系统在可维护性、灵活性和扩展性上得到了极大的提升,特别适合需要频繁调整提示词或支持多样化输出的项目。通过结合LangChain的其他组件,提示词模版成为构建高效、模块化语言生成系统的核心工具。
1.3.4. 结构化输出
在自然语言处理任务中,如何将语言模型(LLM)的非结构化输出转换为结构化数据是一个关键问题。因为只有结构化的数据才有后续进行进一步处理的价值,假如数据都是杂乱无章的话,那其实后续很难真正的被应用起来。就像建筑行业里有大量的数据,包括文本以及各类人与人交互的信息,但是这些数据假如不通过一个平台进行收集整合,是很难被真正应用起来。
而LangChain 提供了一个结构化输出工具(Structured Output),这个工具可以高效解析模型生成的文本并转化为易于使用的字典或 JSON 格式,便于后续处理。换句话说,我们可以把大语言模型作为一个平台,我们只需要输出我们常用的日常语言,其就能够输出一系列的结构化数据供后续进行进一步使用和处理。
比如说,在日常生活中,用户的评论中常常包含大量有价值的信息,例如购买意图、物流体验以及对商品的价格评价等。假设我们有一段用户评论,描述了他们对某款叶吹机的使用感受,其中包含了以下几点关键信息:
- 是否作为礼物购买(
gift):例如用户提到这款产品是作为礼物送给配偶或朋友,需要判断是否有这种购买目的。 - 产品到货所需的天数(
delivery_days):用户评论中可能会提到实际的物流时间,帮助分析配送效率。 - 对价格或价值的评价(
price_value):一些评论会涉及产品的性价比或具体价格评价,比如“稍微贵一些,但功能丰富”。
通过从这些评论中提取结构化信息,我们可以更高效地进行数据分析、用户行为研究以及改善用户体验。接下来,我们将通过代码示例展示如何实现这一目标。
- 初始提示模版的构建
我们首先可以尝试先定义一个简单的提示模版,让模型提取以上信息,并以 JSON 格式返回:
review_template = """
请从以下文本中提取以下信息:
1. 是否作为礼物购买(gift):如果是礼物,请回答True;如果不是或未知,请回答False。
2. 到货天数(delivery_days):提取产品到货所需的天数,如果信息不存在,请输出-1。
3. 价格或价值的评价(price_value):提取任何与价格或价值相关的句子,并以逗号分隔的Python列表形式输出。
请以JSON格式输出,键包括:
- gift
- delivery_days
- price_value
文本:{text}
"""
这个模版明确了我们想要提取的三个信息点,并规定了输出的 JSON 格式。这样的清晰的提示词能够让大模型给出更加准确的回复。
- 创建
ChatPromptTemplate实例并输出
接下来我们可以使用 ChatPromptTemplate 将上述模版转化为动态模板实例,支持后续填充内容。
from langchain.prompts import ChatPromptTemplate
# 创建 ChatPromptTemplate 实例
prompt_template = ChatPromptTemplate.from_template(review_template)
# 示例用户评论
customer_review = """
这款叶吹机非常棒!它有四个设置:蜡烛吹风、微风、风城和龙卷风模式。
它在两天内送达,正好赶上我妻子的周年纪念礼物。
我觉得它稍微比其他叶吹机贵一些,但多出来的功能让我觉得物有所值。
"""
# 格式化提示
messages = prompt_template.format_messages(text=customer_review)
在这里,format_messages 方法会将 customer_review 填充到 review_template 中的 {text} 占位符中,生成最终的提示内容。
然后通过调用语言模型(LLM),我们可以生成所需的输出。
import os
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage
# 设置 API 密钥
os.environ["DASHSCOPE_API_KEY"] = 'sk-63f00f67b06ed5edf197ea'
# 初始化 ChatTongyi 模型
chat_model = ChatTongyi()
# 调用语言模型
response = chat_model.invoke(messages)
print(response.content)
模型返回的结果如下所示:
{
"gift": true,
"delivery_days": 2,
"price_value": ["我觉得它稍微比其他叶吹机贵一些,但多出来的功能让我觉得物有所值。"]}
但是我们会发现,尽管模型返回了 JSON 格式的字符串,但直接将其作为字典操作会报错。这是因为 response.content 的类型是字符串,而非字典。所以我们需要进一步的方法去使其转化为真正的格式化数据。
- 解决方案:使用
StructuredOutputParser
为了将模型返回的 JSON 字符串解析为字典格式,我们可以借助 LangChain 提供的 StructuredOutputParser 工具。
-
ResponseSchema:用于描述每个字段的名称和预期含义。例如: -
gift_schema描述字段gift,用于判断商品是否作为礼物购买。delivery_days_schema描述字段delivery_days,表示到货所需天数。price_value_schema描述字段price_value,提取与价格或价值相关的句子。
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
# 定义每个字段的输出模式
gift_schema = ResponseSchema(name="gift", description="是否作为礼物购买")
delivery_days_schema = ResponseSchema(name="delivery_days", description="产品到货天数")
price_value_schema = ResponseSchema(name="price_value", description="价格或价值的评价")
# 将所有模式组合成一个列表
response_schemas = [gift_schema, delivery_days_schema, price_value_schema]
# 使用模式列表初始化输出解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
其具体运行的逻辑是,首先ResponseSchema 为每个字段定义了一种规范。然后StructuredOutputParser.from_response_schemas 创建了一个结构化输出解析器,该解析器会验证模型返回的 JSON 是否符合这些规范。通过这种方式,可以确保模型输出符合预期的结构,有助于提高数据解析的可靠性和精确性。
- 生成格式化指令并更新模版
通过 StructuredOutputParser 的 get_format_instructions 方法,我们可以生成解析指令,确保模型输出符合规范。get_format_instructions() 方法会根据之前定义的 ResponseSchema 自动生成包含字段描述的格式化指令。这些指令会嵌入提示词模版中,引导模型返回符合规范的 JSON 格式。
format_instructions = output_parser.get_ format_instructions()
# 将解析指令嵌入提示模版
review_template_with_format = """
请从以下文本中提取以下信息:
1. 是否作为礼物购买(gift):如果是礼物,请回答True;如果不是或未知,请回答False。
2. 到货天数(delivery_days):提取产品到货所需的天数,如果信息不存在,请输出-1。
3. 价格或价值的评价(price_value):提取任何与价格或价值相关的句子,并以逗号分隔的Python列表形式输出。
{format_instructions}
文本:{text}
"""
在这里,format_instructions 会生成类似以下内容:
格式输出应为一个以 JSON 格式的 Markdown 代码段,包含以下键:
"gift" // 是否作为礼物购买。
"delivery_days" // 产品到货所需天数。
"price_value" // 提取价格或价值相关句子。
然后利用 format_messages() 方法将用户评论和格式化指令整合到提示词中。之后调用语言模型(LLM)生成结果。最终我们将使用 StructuredOutputParser 将 LLM 的输出从字符串解析为标准化字典。
# 格式化消息
messages = prompt_template.format_messages(text=customer_review, format_instructions=format_instructions)
response = chat_model.invoke(messages)
# 解析模型输出
output_dict = output_parser.parse(response.content)
print(output_dict)
最终输出结果如下所示:
{'gift': True, 'delivery_days': 2, 'price_value': ['我觉得它稍微比其他叶吹机贵一些,但多出来的功能让我觉得物有所值。']}
此时,返回的内容是一个标准化的字典,可以直接通过键值对访问具体信息。
print(output_dict.get('delivery_days')) # 输出: 2
- 优势总结
总的来说,利用LangChain进行结构化输出有以下几个优势。
- 标准化输出:通过
StructuredOutputParser,模型的输出被严格限制在预定义的格式范围内。例如,在本案例中,返回的 JSON 包括gift、delivery_days和price_value三个字段,确保了模型不会遗漏或多输出信息。 - 高可读性:解析结果直接转换为 Python 字典或 JSON 格式,使得开发者可以快速提取数据并进行处理,例如
output_dict.get('delivery_days')直接返回天数。 - 灵活性强:通过
ResponseSchema,开发者可以灵活定义新字段和输出模式。例如,如果需要新增字段“用户满意度”,只需在response_schemas中增加相应的ResponseSchema,便可快速扩展解析功能。
LangChain 提供的结构化输出工具不仅提升了开发效率,还显著增强了模型输出的可靠性和可控性,尤其适用于需要标准化数据的复杂自然语言处理任务。本小节完整的代码如下所示:
import os
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage
from langchain.prompts import ChatPromptTemplate
# 设置 API 密钥
os.environ["DASHSCOPE_API_KEY"] = 'sk-63f00f67b06ed5edf197ea'
# 初始化 ChatTongyi 模型
chat_model = ChatTongyi()
review_template = """
请从以下文本中提取以下信息:
1. 是否作为礼物购买(gift):如果是礼物,请回答True;如果不是或未知,请回答False。
2. 到货天数(delivery_days):提取产品到货所需的天数,如果信息不存在,请输出-1。
3. 价格或价值的评价(price_value):提取任何与价格或价值相关的句子,并以逗号分隔的Python列表形式输出。
请以JSON格式输出,键包括:
- gift
- delivery_days
- price_value
文本:{text}
"""
# 创建 ChatPromptTemplate 实例
prompt_template = ChatPromptTemplate.from_template(review_template)
# 示例用户评论
customer_review = """
这款叶吹机非常棒!它有四个设置:蜡烛吹风、微风、风城和龙卷风模式。
它在两天内送达,正好赶上我妻子的周年纪念礼物。
我觉得它稍微比其他叶吹机贵一些,但多出来的功能让我觉得物有所值。
"""
# 格式化提示
messages = prompt_template.format_messages(text=customer_review)
# 调用语言模型
response = chat_model.invoke(messages)
print(response.content) # 字符串而非字典
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
# 定义每个字段的输出模式
gift_schema = ResponseSchema(name="gift", description="是否作为礼物购买")
delivery_days_schema = ResponseSchema(name="delivery_days", description="产品到货天数")
price_value_schema = ResponseSchema(name="price_value", description="价格或价值的评价")
# 将所有模式组合成一个列表
response_schemas = [gift_schema, delivery_days_schema, price_value_schema]
# 使用模式列表初始化输出解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
# 将解析指令嵌入提示模版
review_template_with_format = """
请从以下文本中提取以下信息:
1. 是否作为礼物购买(gift):如果是礼物,请回答True;如果不是或未知,请回答False。
2. 到货天数(delivery_days):提取产品到货所需的天数,如果信息不存在,请输出-1。
3. 价格或价值的评价(price_value):提取任何与价格或价值相关的句子,并以逗号分隔的Python列表形式输出。
{format_instructions}
文本:{text}
"""
# 格式化消息
messages = prompt_template.format_messages(text=customer_review, format_instructions=format_instructions)
response = chat_model.invoke(messages)
# 解析模型输出
output_dict = output_parser.parse(response.content)
print(output_dict)
print(output_dict.get('delivery_days')) # 输出 2
1.4. 总结
在本次课程中,我们深入探讨了如何使用LangChain开发大语言模型应用,从基础的模型调用到复杂的结构化输出。通过LangChain,模型调用流程大幅简化,只需几行代码即可完成复杂操作,同时借助提示词模版和结构化输出工具,开发者能够以模块化、高灵活性的方式实现动态交互和数据提取。此外,我们还展示了如何设计提示词以精准引导模型生成高质量结果,以及通过StructuredOutputParser将模型输出标准化为结构化数据,从而提高解析的可靠性和数据利用效率。这些内容为构建高效的大模型应用奠定了坚实的技术基础。
但是有一个很重要的点我们需要思考的是,由于LangChain并不是通过中文构建起来的,因此其底层的很多提示词很多都是中文,很多时候我们调用会出现莫名奇怪的英文的原因就在此。因此假如一些专业化程度的场景下,使用中文化的提示词去重构其实非常必要。
那在下节课,我们将一同探讨归于LangChain或者大语言模型中很重要的一个内容——Memory,也就是我们常说的记忆力或者上下文。我们如何把之前的对话传入,有没有方法能够让传入的信息密度更高,有没有可能降低过长的聊天记录导致的幻觉以及费用。那我们就下节课一起来探讨吧!拜拜!
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









