






BERT
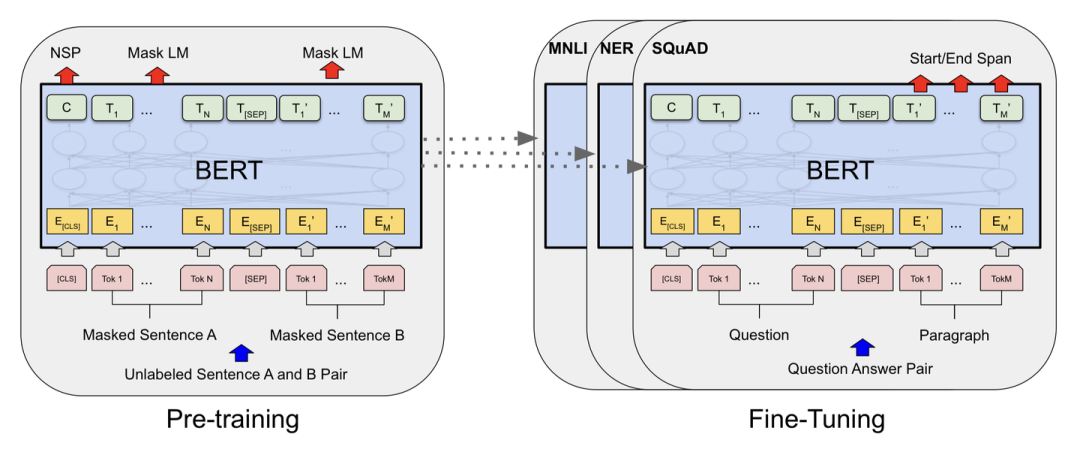
BERT是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。BERT论文发表时提及在11个NLP(Natural Language Processing,自然语言处理)任务中获得了新的state-of-the-art的结果,令人目瞪口呆。
结构
以往的预训练模型的结构会受到单向语言模型(从左到右或者从右到左)的限制,因而也限制了模型的表征能力,使其只能获取单方向的上下文信息。
而BERT利用MLM进行预训练并且采用深层的双向Transformer组件(单向的Transformer一般被称为Transformer decoder,其每一个token(符号)只会attend到目前往左的token。而双向的Transformer则被称为Transformer encoder,其每一个token会attend到所有的token。)来构建整个模型,因此最终生成能融合左右上下文信息的深层双向语言表征。
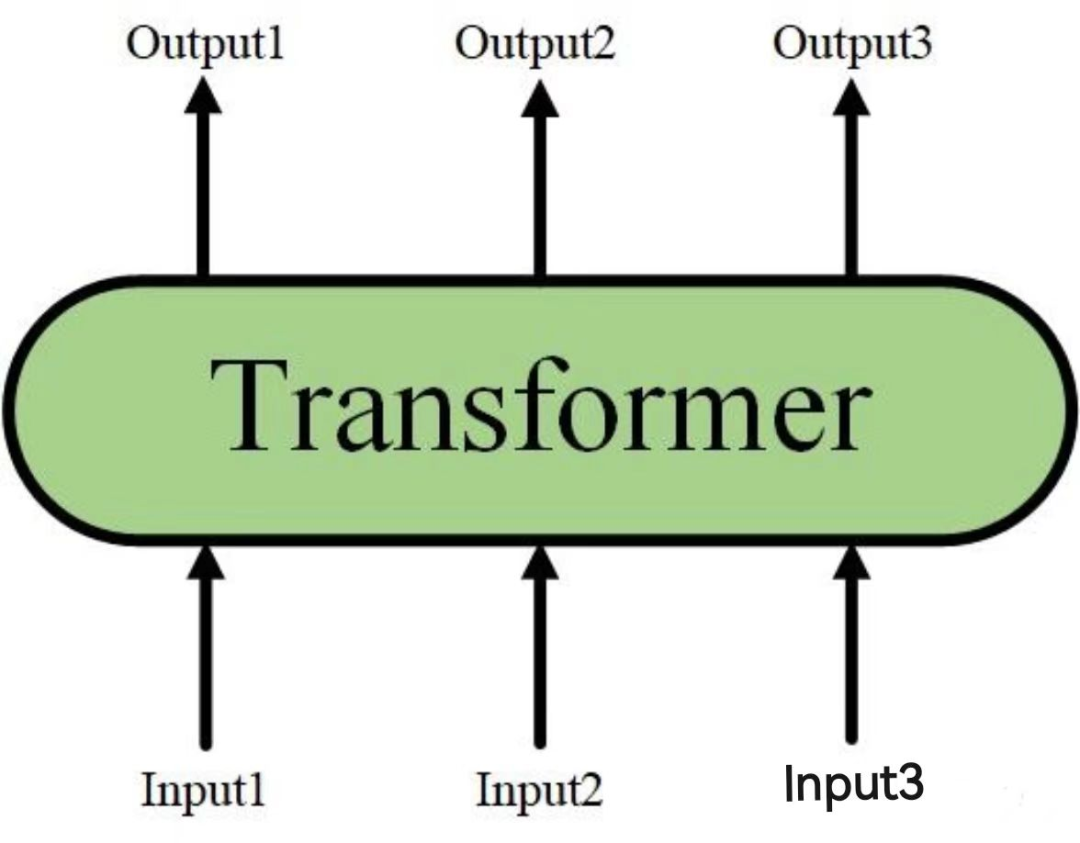
当隐藏了Transformer的详细结构后,我们就可以用一个只有输入和输出的黑盒子来表示它了:
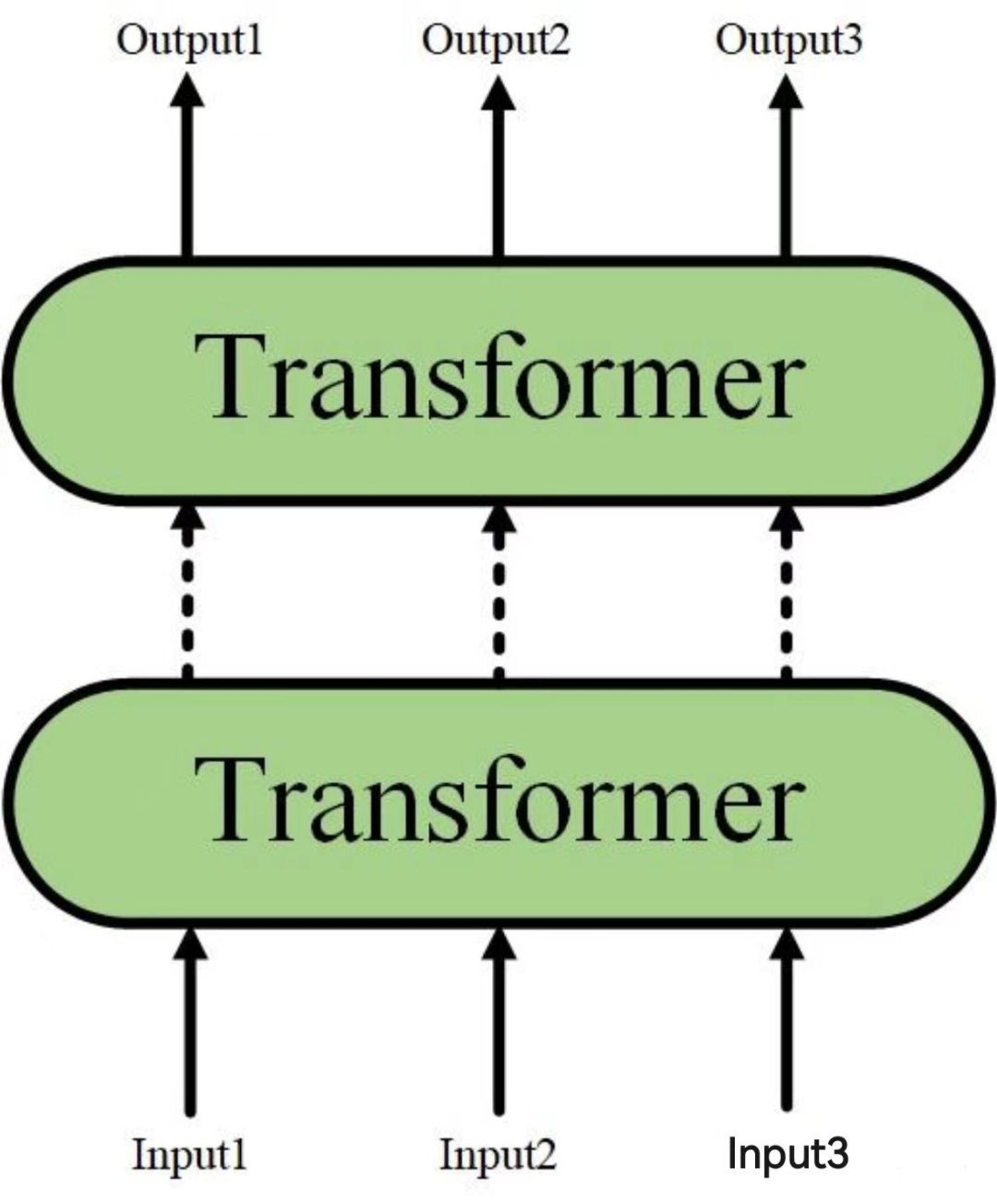
而Transformer结构又可以进行堆叠,形成一个更深的神经网络(这里也可以理解为将Transformer encoder进行堆叠):
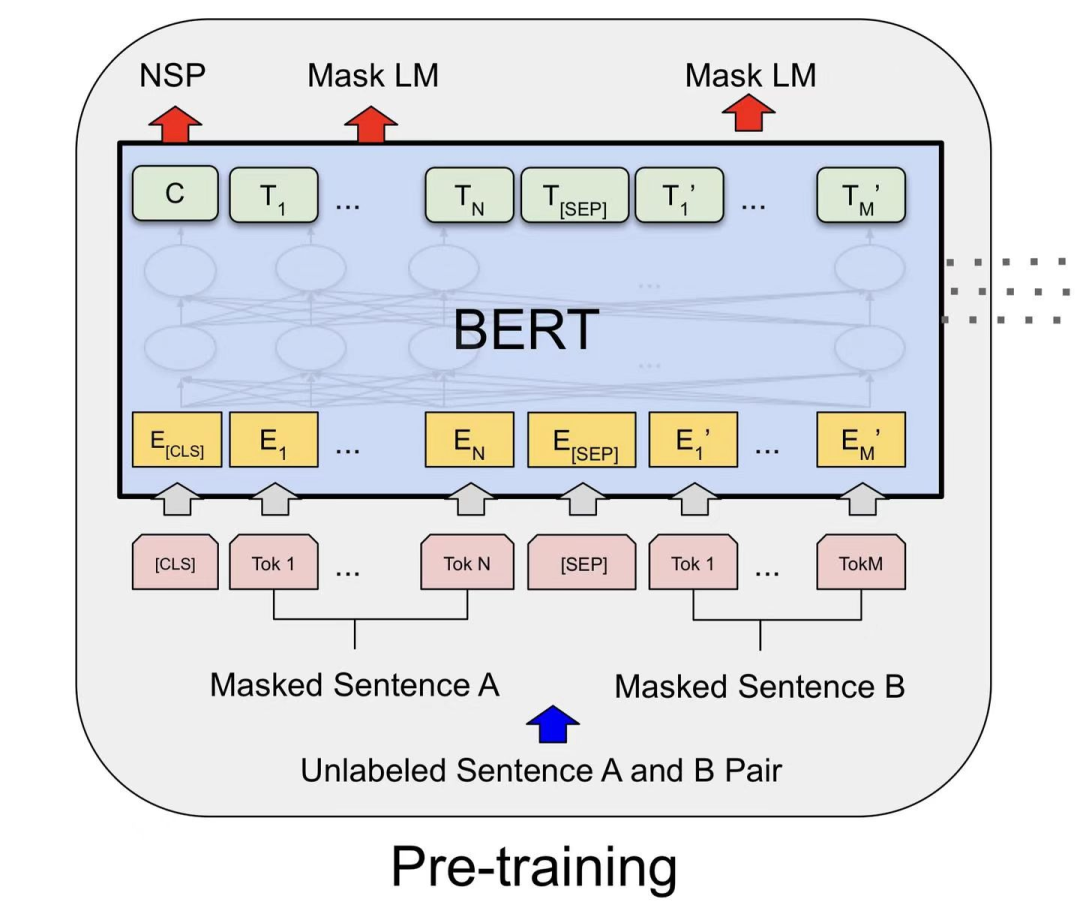
最终,经过多层Transformer结构的堆叠后,形成BERT的主体结构:
BERT的输入
BERT的输入为每一个token对应的表征(图中的粉红色块就是token,黄色块就是token对应的表征),并且单词字典是采用WordPiece算法来进行构建的。为了完成具体的分类任务,除了单词的token之外,作者还在输入的每一个序列开头都插入特定的分类token([CLS]),该分类token对应的最后一个Transformer层输出被用来起到聚集整个序列表征信息的作用。
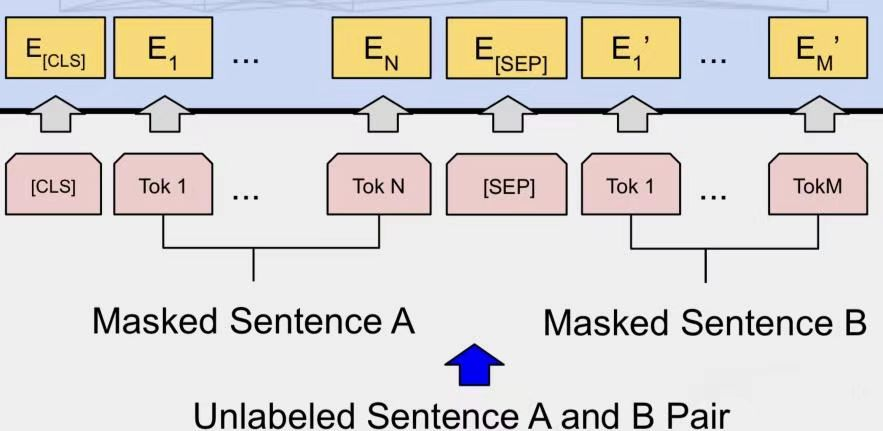
由于BERT是一个预训练模型,其必须要适应各种各样的自然语言任务,因此模型所输入的序列必须有能力包含一句话(文本情感分类,序列标注任务)或者两句话以上(文本摘要,自然语言推断,问答任务)。
那么如何令模型有能力去分辨哪个范围是属于句子A,哪个范围是属于句子B呢?BERT采用了两种方法去解决:
1.在序列tokens中把分割token([SEP])插入到每个句子后,以分开不同的句子tokens。
2.为每一个token表征都添加一个可学习的分割embedding来指示其属于句子A还是句子B。
因此最后模型的输入序列tokens为下图(如果输入序列只包含一个句子的话,则没有[SEP]及之后的token):
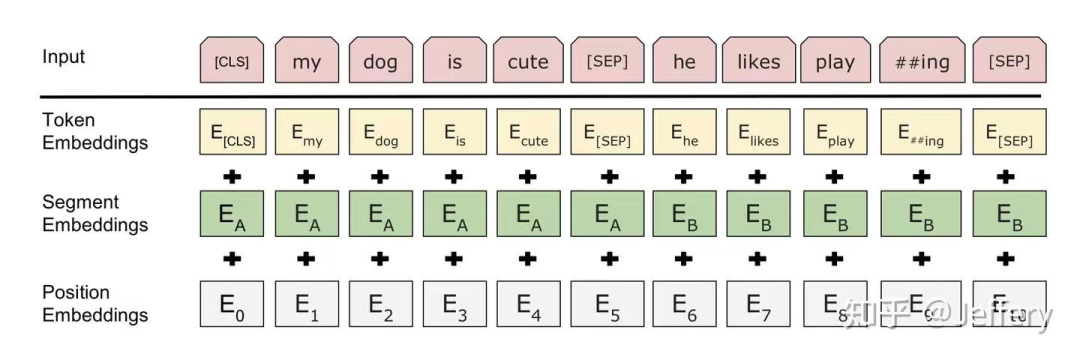
上面提到了BERT的输入为每一个token对应的表征,实际上该表征是由三部分组成的,分别是对应的token,分割和位置 embeddings(位置embeddings的详细解释可参见Attention Is All You Need 或 The Illustrated Transformer),如下图:
到此为止,BERT的输入已经介绍完毕,可以看到其设计的思路十分简洁而且有效。
BERT的输出
介绍完BERT的输入,实际上BERT的输出也就呼之欲出了,因为Transformer的特点就是有多少个输入就有多少个对应的输出,如下图:

C为分类token([CLS])对应最后一个Transformer的输出,Ti则代表其他token对应最后一个Transformer的输出。对于一些token级别的任务(如,序列标注和问答任务),就把Ti 输入到额外的输出层中进行预测。对于一些句子级别的任务(如,自然语言推断和情感分类任务),就把C输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 7333
7333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









