






近日,继去年5月发布首个泛自然资源行业多模态基础大模型“长城”后,数慧时空又重磅推出了超高时空分辨率气象AI大模型“微澜测天”,以强大的计算能力和智能化算法为基础,不仅拥有全球中长期气象预报能力,还基于先进的超分技术,中国区域更新最高可达到6分钟时间分辨率、1公里空间分辨率的气象数据预报,并在预报准确度、时效性和稳定性等方面表现卓越,可以更好地满足各行各业对精细化预报和微观气象的需求。
01、传统数值预报模式的局限性
目前,应对复杂的天气过程,过去几十年世界范围内主流的预测方法是借助“数值天气预报”,其主要原理是将天气的变化描述为一组偏微分方程组,利用科学家长期研究出的一套复杂数学物理模型和计算机模拟来预测未来天气情况的演变。然而,求解这些复杂方程通常速度较慢,业务上运行数值天气预报模型时需要高性能且大规模的CPU集群才能及时地产生预报结果,一些模拟甚至需要数千个节点运行几个小时才能完成。同时,这些数值模型通常包括各种物理过程的参数化,如辐射传输、云物理、地表过程等,会由于各种假设和简化不可避免地引入近似误差。
此外,要想实现高分辨率的区域性降水预报,传统的数值预报方法通常是对全球预报模式所获取的预报数据进行降尺度(类似于超分)来得到时空高分辨率的降水预报结果。这种方式除了所需计算资源多、推理速度慢以外,还有一个无法避开的问题:区域模式的启动需要进行内部计算的平衡(即spin-up),并且云也是由0开始积分,通常认为常见的区域天气预报模式需要3-6小时才能完成平衡过程,这也就导致这段时间内的降水是不太可靠的。
02、数据驱动的AI预报技术带来颠覆性变革,预报速度显著提升
近几年,AI预报技术的崛起为天气预报领域带来了颠覆性的变革,赋予了其全新的可能性。数慧时空气象AI大模型“微澜测天”紧跟这一趋势,积极融合人工智能技术,实现了从传统数值预报方法到深度学习领域的跨越。“微澜测天”大模型基于长达20年的ERA5全球再分析数据,广泛覆盖了包括温度、湿度、位势、经向风、纬向风在内的五种关键气象要素,在垂直高度上跨越了九个不同气压层,并涵盖了地球表面的海平面气压、近地面气温、风场及降水等多个方面,在大量历史气象数据中接受训练。同时,引入了三维Swin-Unet网络架构及多步损失微调策略,显著降低预报的累积误差。
当获取到最新气象数据时,模型能够迅速运用从历史数据中习得的知识进行高效预测。该过程的计算强度相对较小,即使在配置普通的GPU(图形计算单元)上,也只需要几分钟即可完成覆盖全球范围、分辨率为0.25经纬度(约25 km*25 km)的7天气象预报,预报速度相比传统数值预报得到了极大地提升。


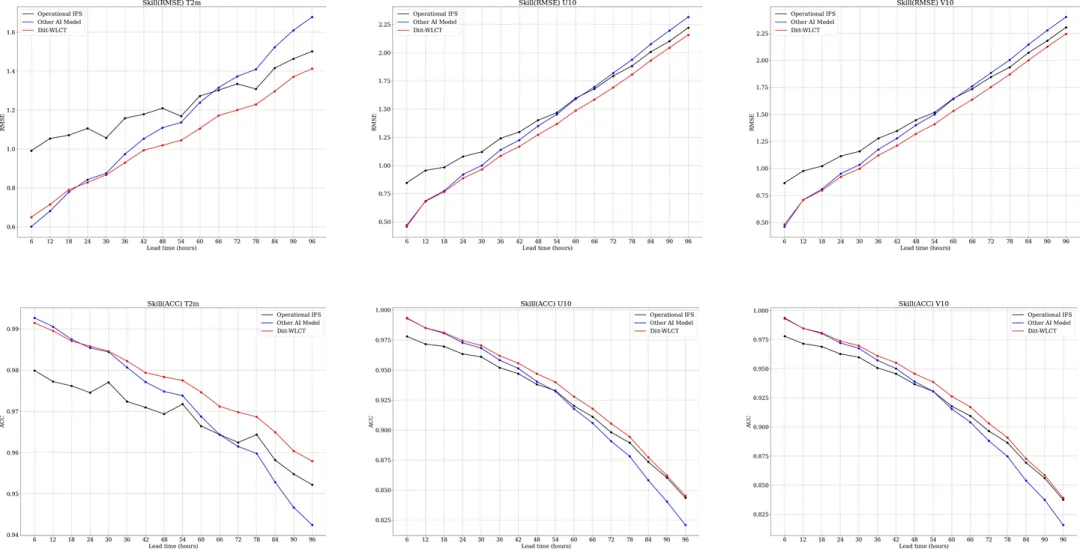
Diit-WLCT均方根误差和异常相关系数与其他模型的对比
"与市面现有的几家气象大模型相比,数慧时空’微澜测天’气象AI大模型在多个方面展现出卓越的性能。它不仅拥有全球中长期降雨预测能力,还将中国区域的预报结果提升至6分钟、1公里的超高时空分辨率,其在空间分辨率相比其他模型提高了25倍以上。同时,在推理速度上同样表现出色,以短临降水预报为例,'微澜测天’大模型在单张A10 显存22G配置条件下,可以稳定且快速预测未来三小时全国降水产品,更新频率为6分钟一次,每生产一次全国的降水产品仅需30秒。”数慧时空气象AI大模型负责人表示。

三小时短临降水预报
03、多场景切入,不断推进大模型应用落地和迭代升级
当前,数慧时空“微澜测天”气象AI大模型正从农业生产、农业保险和应急管理等多个应用场景入手,开展大模型的部署应用和进一步迭代升级。
以农业生产领域农作物生长期及其长势预测为例,系统基于输入的遥感影像,运用解译多模态大模型自动化识别提取该地区作物图斑分布,并计算NDVI、LAI等指数属性。基于产品标签推送数据服务,结合本地知识库,综合作物标签、影像时间、物候期、植被指数等信息,选取气象数据分析得到有效积温、累计降水等关键因子,并叠加后续一段时间内的温度、降水预测数据,在以天为单位的时间维度上对作物生长发育状况进行分析,挖掘关键气象因子与作物生长间的相关性,构建植物生长发育预测模型,判断生长期并评估作物长势。针对作物气象敏感生育期,结合气象数据智能化提供高/低温、大风、暴雨、霜冻等预警信号,帮助提前应对,减少产量损失。当作物临近成熟期,结合气象短期预报可为农户推荐合适的收割期。此外,气象模型还可以应用于农业保险、病虫害预警、森林草原火情监测、环境保护、应急灾害管理等场景。
同时,短临降水预报大模型可以应用于城市内涝、山体滑坡、未来出行建议等场景。以山体滑坡为例,未来三小时的降水产品与基于卫星遥感观测数据的目标解译产品相结合,可识别出易出现山体滑坡的地点,做到灾前预警、灾中监测、灾后评估等一系列防灾减灾工作。
未来展望:精细化气象服务赋能千行百业
数慧时空“微澜测天”气象AI大模型紧跟现代气象科技的前沿,以其卓越的性能和广泛的应用领域,致力于为用户提供前所未有的高精度微观气象服务。未来,随着深度学习技术的持续革新和进步,以及全球范围内气象历史数据的不断累积和丰富,“微澜测天”大模型将迎来新的发展机遇。它将能够更加准确地捕捉和预测复杂多变的气象现象,进一步提升预报的准确度和时效性。同时,该模型还将能够根据用户的特定需求,提供个性化的定制化气象服务,有望在农业、交通、能源等多个领域发挥重要作用,满足不同行业和领域的精准气象需求,助力用户在复杂多变的气象环境下做出更明智的决策,从而提升生产效率、降低风险,实现可持续发展。
如何学习AI大模型?
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









