







一、什么是反爬虫
网络爬虫,是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。但是当网络爬虫被滥用后,互联网上就出现太多同质的东西,原创得不到保护。于是,很多网站开始反网络爬虫,想方设法保护自己的内容。
他们根据ip访问频率,浏览网页速度,账户登录,输入验证码,flash封装,ajax混淆,js加密,图片,css混淆等五花八门的技术,来对反网络爬虫。
防的一方不惜工本,迫使抓的一方在考虑成本效益后放弃,抓的一方不惜工本,防的一方在考虑用户流失后放弃. 【百度百科】
二、反爬虫的原因
1. 爬虫占总PV(PV是指页面的访问次数,每打开或刷新一次页面,就算做一个pv)比例较高,服务器的压力上升,能力下降。
2018年2月24日晚,卓见云某客户网站公网出流量突然爆发性增长,导致带宽被占满,事故发现后紧急提升了SLB的带宽,但提升后的带宽仍然被流量占满(原带宽15M,提升至35M)。由于事故发生在非黄金访问时段,正常流量不会这么大,加上其他现象,怀疑是遭到了网络攻击。
再比如某节某动为了快速发展搜索业务派出爬虫四处暴力抓取网站内容,部分配置较低的网站已经直接瘫痪,给中小网站主们造成了很大的损失和困扰,严重影响了网站正常的用户访问。
某中小网站今年7月份,他突然发现公司的网站经常性打不开,网页加载极其缓慢,有时甚至直接瘫痪。经过一系列排查后,在服务器日志上发现了bytespider爬虫的痕迹。该爬虫抓取的频率每天达几百万次,高则上千万次,服务器带宽负载飙至100%,而且该爬虫在抓取时完全不遵守网站的robots协议。
有小网站主抱怨表示:某节某动的爬虫“一上午对网站发出46万次请求”,网站都瘫痪了,度娘也没有这么折腾的!
可能原因分析:
\1) 商业对手,出于竞争需要,采用爬虫获取信息。
\2) 搜素引擎抽风。
3)“三月份爬虫”,应届毕业生为交论文常在这个时间点在网上爬取数据,此类爬虫通常简单粗暴,不管服务器压力。
4)近期做的推广活动带来访问压力增加。
2. 公司可免费查询的资源被批量抓走,丧失竞争力。
数据可以在非登录状态下直接被查询,比如下方的招聘信息
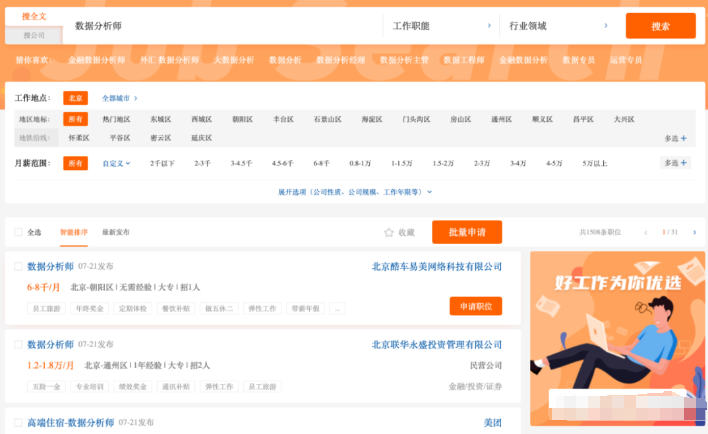
也有网站想获取信息必须强制登陆,如果没有登陆是看不到任何信息的。但是如果不强制对方登录,争对手可以轻松批量抓到更多的信息,企业的竞争力就会大大减少。
3. 状告爬虫成功的几率小
爬虫在国内还是个擦边球,就是有可能可以起诉成功,也可能完全无效。近期引发关注的是淘宝被非法爬取案件,这是成功的案例,还有很多没有成功的案例。

所以还是需要用技术手段来做最后的保障。
三、反什么样的爬虫
新手兴趣爱好者或者是应届毕业生
新手兴趣爱好者、应届毕业生的爬虫通常简单粗暴,根本不管服务器压力,加上人数不可预测,很容易把站点弄挂。
创业小公司
现在的创业公司越来越多,觉得大数据比较热,就开始做大数据。发现自己手头没有数据。怎么办?只能通过写爬虫获取更多的数据。于是就有了不计其数的小爬虫,出于公司生死存亡的考虑,不断爬取数据维持公司的生计。
失控小爬虫
有些网站已经做了相应的反爬,但是爬虫依然孜孜不倦地爬取。虽然他们根本爬不到任何数据,或者一切数据都是不对的,可是爬虫依然不停止。😓这个很可能就是一些托管在某些服务器上的小爬虫,已经无人认领了,依然在辛勤地工作着。
成型的商业对手
这个是最大的对手,他们有技术,有钱,要什么有什么,如果和你死磕,你就只能硬着头皮和他死磕。否则法律手段解决。
抽风的搜索引擎
大家不要以为搜索引擎都是好人,他们也有抽风的时候,而且一抽风就会导致服务器性能下降,请求量跟网络攻击没什么区别。
四、常见的反扒手段
反扒的手段,基本是基于以下三种:
- 基于身份识别进行反爬
- 基于爬虫行为进行反爬
- 基于数据加密进行反爬
身份识别的反爬:
1. 通过headers字段来反扒
headers知识补充:
host:提供了主机名及端口号
Referer 提供给服务器客户端从那个页面链接过来的信息(有些网站会据此来反爬)
Origin:Origin字段里只包含是谁发起的请求,并没有其他信息.(仅存于post请求)
User agent: 发送请求的应用程序名(一些网站会根据UA访问的频率间隔时间进行反爬)
proxies:代理,一些网站会根据ip访问的频率次数等选择封ip.
cookie:特定的标记信息,一般可以直接复制,对于一些变化的可以选择构造.
2. 通过请求参数来反爬
常见的有:
\1) 通过headers中的User-Agent字段来反爬、通过referer字段或者是其他字段来反爬。如果Python写的爬虫不加入User-Agent,在后台服务器是可以看到服务器的类型pySpider。
\2) 通过cookie限制抓取信息,比如我们模拟登陆之后,想拿到登陆之后某页面信息,千万不要以为模拟登陆之后就所有页面都可以抓了,有时候还需要请求一些中间页面拿到特定cookie,然后才可以抓到我们需要的页面。
\3) 最为经典的反爬虫策略当属“验证码”了。最普通的是文字验证码,因为是图片用户登录时只需输入一次便可录成功,而我们程序抓取数据过程中,需要不断的登录,手动输入验证码是不现实的,所以验证码的出现难倒了一大批人。当然还有滑块的,点触的的(比如12306的点触验证等)。

\4) 另一种比较常见的反爬虫模式当属采用JS渲染页面了。就是返回的页面并不是直接请求得到,而是有一部分由JS操作DOM得到,所以那部分数据我们也拿不到咯。
基于爬虫行为进行反爬
\1) 基于请求频率或总请求数量的反扒,这是一种比较恶心又比较常见的反爬虫策略当属封ip和封账号,当你抓取频率过快时,ip或者账号被检测出异常会被封禁。被封的结果就是浏览器都无法登陆了,但是换成ip代理就没有问题。
爬虫如何避免被封IP呢?
1. 降低访问频率
反爬虫一般是在规定时间内IP访问次数进行的限制,可以限制每天抓取的页面数量和时间间隔。既能满足采集速度,也能不被限制IP。
2.多线程采集
采集大批量的数据的时候,可以使用多线程。它可以同步完成多项任务,每个线程采集不同的任务,提高采集数量。
3.使用代理IP
想要突破网站的反爬虫机制,需要使用代理IP,通过换IP的方法进行多次访问。采用多线程采集时,也需要大量的IP,优先使用高匿名代理,否则目标网站检测到你的真实IP,也会影响到工作的进行。
4.对IP进行伪装
虽然大多网站都有反爬虫,但有一些网站对这方便比较忽略,这样就可以对IP进行伪装,修改X-Forwarded-for就可以避过。但如果想频发抓取,还是需要多IP。
\2) 通过js实现跳转来反爬,js实现页面跳转,无法在源码中获取下一页url,需要多次抓包获取条状url,分析规律。
\3) 通过蜜罐(陷阱)获取爬虫ip(或者代理ip),进行反爬。蜜罐的原理:在爬虫获取链接进行请求的过程中,爬虫会根据正则,xpath,css等方式进行后续链接的提取,此时服务器端可以设置一个陷阱url,会被提取规则获取,但是正常用户无法获取,这样就能有效的区分爬虫和正常用户
\4) 通过假数据反爬,向返回的响应中添加假数据污染数据库,通常假数据不会被正常用户看到。
基于数据加密进行反爬
\1) 对响应中含有的数据进行特殊化处理
通常的特殊化处理主要指的就是css数据偏移/自定义字体/数据加密/数据图片/特殊编码格式等
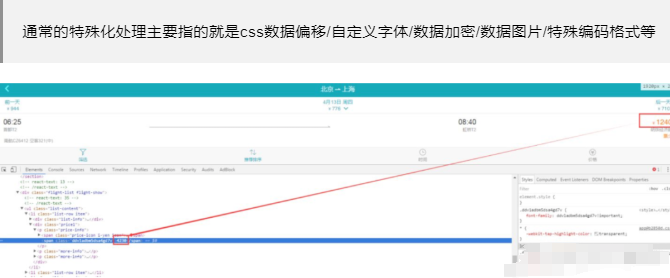
根据css你会发现他们用了一个字体,打开你就发现了一件事
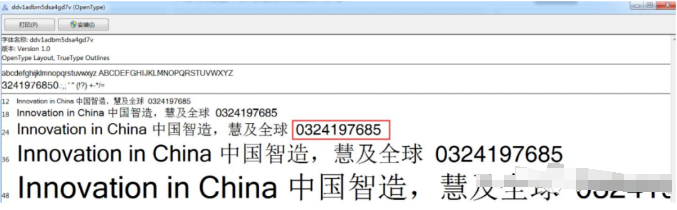
正常字体是0123456789,在去哪儿官方的字体里被替换成了图片里的
另外还有这种情况的字体反爬
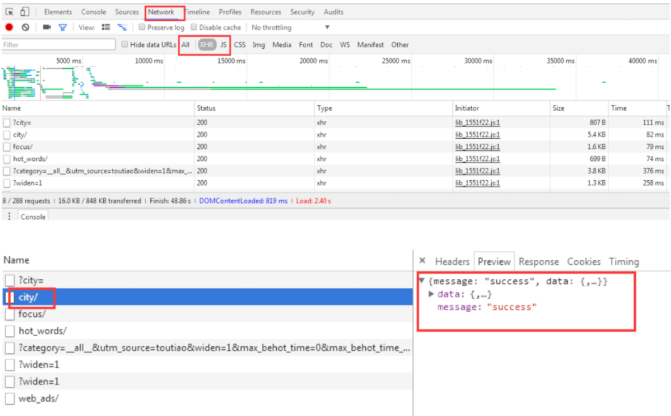
\2) 有一些网站的内容由前端的JS动态生成,由于呈现在网页上的内容是由JS生成而来,我们能够在浏览器上看得到,但是在HTML源码中却发现不了。这就需要解析关键js,获得数据生成流程,模拟生成数据。一般获取的数据是通过AJAX获取的,返回的结果是Json,然后解析Json获取数据。
\3) 通过编码格式进行反爬,不适用默认编码格式,在获取响应之后通常爬虫使用utf-8格式进行解码,此时解码结果将会是乱码或者报错。解决思路:根据源码进行多格式解码,或者真正的解码格式
五、知己知彼:编写爬虫
简单爬虫
要想做反爬虫,我们首先需要知道如何写个简单的爬虫。
通常编写爬虫需要经过这么几个过程:
- 分析页面请求格式
- 创建合适的http请求
- 批量发送http请求,获取数据
举个例子,直接查看携程生产url。在详情页点击“确定”按钮,会加载价格。假设价格是你想要的,那么抓出网络请求之后,哪个请求才是你想要的结果呢?你只需要用根据网络传输数据量进行倒序排列即可。因为其他的迷惑性的url再多再复杂,开发人员也不会舍得加数据量给他。

代码:
import requests
def download_page(url):
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url,headers=headers)
return data
if __name__ == '__main__':
url = 'https://m.ctrip.com/restapi/soa2/21881/json/HotelSearch?testab=5b9a651b08c1069815c5af78f8b2bf6df9dd42a6129be5784bb096315494619a'
download_page(url)
高级爬虫
那么爬虫进阶应该如何做呢?通常所谓的进阶有以下几种:
1.分布式爬虫
Python默认情况下,我们使用scrapy框架进行爬虫时使用的是单机爬虫,就是说它只能在一台电脑上运行,因为爬虫调度器当中的队列queue去重和set集合都只能在本机上创建的,其他电脑无法访问另外一台电脑上的内存和内容。
分布式爬虫实现了多台电脑使用一个共同的爬虫程序,它可以同时将爬虫任务部署到多台电脑上运行,这样可以提高爬虫速度,实现分布式爬虫。首先就需要配置安装redis和scrapy-redis,而scrapy-redis是一个基于redis数据库的scrapy组件,它提供了四种组件,通过它,可以快速实现简单分布式爬虫程序。
四种scrapy-redis组件:
1.Scheduler(调度):Scrapy改造了python本来的collection.deque(双向队列)形成了自己Scrapy queue,而scrapy-redis 的解决是把这个Scrapy queue换成redis数据库,从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。Scheduler负责对新的request进行入列操作(加入Scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。
\2. Duplication Filter(去重):Scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。
\3. Item Pipline(管道):引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue 。
\4. Base Spider(爬虫):不再使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
工作原理:
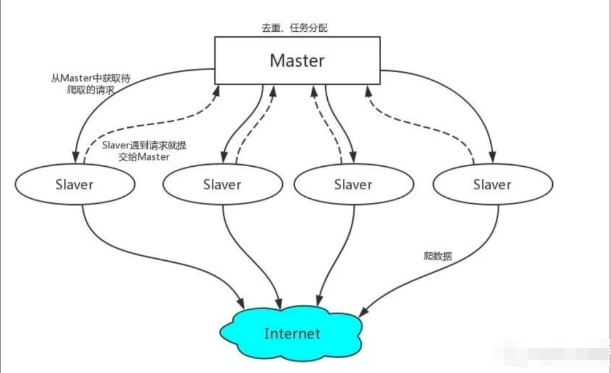
1)首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
2)Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
\2. 模拟JavaScript
模拟javascript,抓取动态网页,是进阶技巧。但是其实这只是个很简单的功能。因为,如果对方没有反爬虫,你完全可以直接抓ajax本身,而无需关心js怎么处理的。如果对方有反爬虫,那么javascript必然十分复杂,重点在于分析,而不仅仅是简单的模拟。
\3. PhantomJs或者selenium
以上的用来做自动测试的,结果因为效果很好,很多人拿来做爬虫。但是这个东西有个硬伤,就是:效率。占用资源比较多,但是爬取效果很好。
六、总结
越是低级的爬虫,越容易被封锁,但是性能好,成本低。越是高级的爬虫,越难被封锁,但是性能低,成本也越高。
当成本高到一定程度,我们就可以无需再对爬虫进行封锁。经济学上有个词叫边际效应。付出成本高到一定程度,收益就不是很多了。
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】















 1047
1047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









