






在线和离线对齐算法的性能差距根源何在?DeepMind实证剖析出炉
在 AI 对齐问题上,在线方法似乎总是优于离线方法,但为什么会这样呢?近日,Google DeepMind 一篇论文试图通过基于假设验证的实证研究给出解答。

根据人类反馈的强化学习(RLHF)随着大型语言模型(LLM)发展而日渐成为一种用于 AI 对齐的常用框架。不过近段时间,直接偏好优化(DPO)等离线方法异军突起 —— 无需主动式的在线交互,使用离线数据集就能直接对齐 LLM。这类方法的效率很高,也已经得到实证研究的证明。但这也引出了一个关键问题:
AI 对齐是否必需在线强化学习?
对于这个问题,人们希望既知道其理论上的答案,也希望明晰实验给出的解答。
从实证角度看,相比于大家常用的在线 RLHF(由偏好建模和从模型采样组成),离线算法实现起来要简单得多,成本也低得多。因此,收集有关离线算法的充分性的证据可让 AI 对齐变得更加简单。另一方面,如果能明晰常用在线 RLHF 的优势,也能让我们理解在线交互的基本作用,洞见离线对齐方法的某些关键挑战。
在线算法与离线算法的对比
要公平地比较在线和离线算法并非易事,因为它们存在许多实现和算法方面的差异。举个例子,在线算法所需的计算量往往大于离线算法,因为它需要采样和训练另一个模型。因此,为了比较公平,需要在衡量性能时对不同算法所耗费的预算进行一定的校准。
在 DeepMind 的这项研究中,研究团队在比较时并未将计算量作为一个优先考虑因素,而是采用了 Gao et al. (2023) 的论文《Scaling laws for reward model overoptimization》中的设置:使用 RLHF 策略和参考 SFT 策略之间的 KL 散度作为预算的衡量指标。
在不同的算法和超参数设置中,KL 散度是以一种统一的方式衡量 RLHF 策略与 SFT 策略的偏离程度,从而能以一种经过校准的方式对算法进行比较。
基于古德哈特定律比较在线和离线算法的性能
首先,该团队比较了在线和离线算法的过度优化(over-optimization)行为 —— 该行为可通过将古德哈特定律外推至 AI 对齐领域而预测得到。
简单总结起来,古德哈特定律(Goodhart’s law)可以表述成:一项指标一旦变成了目标,它将不再是个好指标。
该团队采用了与 Gao et al. (2023) 类似的设置,基于一组开源数据集进行了实验,结果表明:在同等的优化预算(相对于 SFT 策略的 KL 散度)下,在线算法的性能表现通常优于离线算法。
图 1 给出了在线和离线算法在四个不同的开源数据集上表现出的 KL 散度与策略性能之间的权衡。图中的每个数据点代表了在训练过程中某个特定检查点下,针对特定一组超参数的策略评估结果。
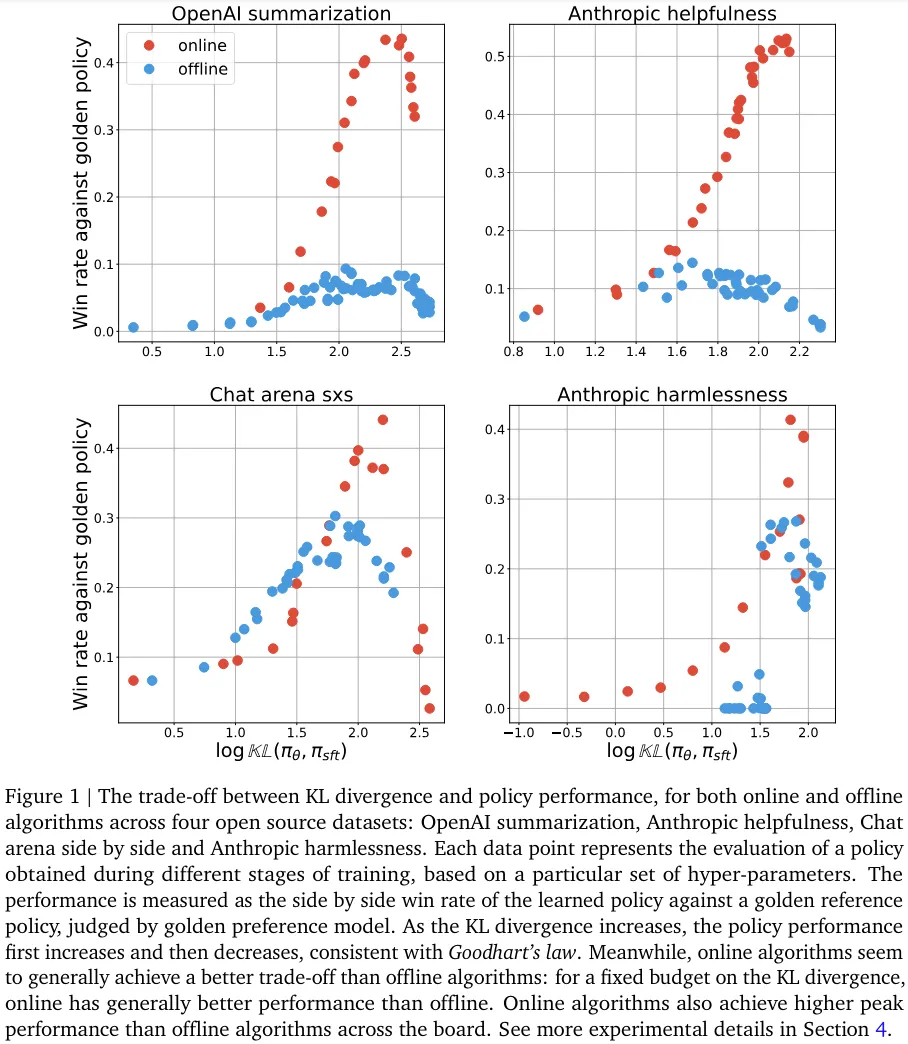
其中,对于在线算法,超参数并未被大量调整,而是始终使用一组固定的超参数;对于离线算法,则是将不同超参数的结果池化后得出。可以观察到如下结果:
-
符合古德哈特定律的过度优化。不管是在线还是离线算法,性能都会随 KL 散度先升后降。后期下降的原因是过度优化效应,这符合古德哈特定律的预测。
-
在线算法能比离线算法更高效地使用 KL 散度预算。相比于离线算法,在线算法似乎通常能实现更好的权衡。具体而言,在 KL 散度度量的预算一样时,在线算法得到的性能通常优于离线算法。在不同的 KL 散度层级上,在线算法在所有任务上的峰值性能都高于离线算法。其中,在 OpenAI 摘要和 Anthropic 辅助任务上的峰值性能差异显著,在另两个任务上的峰值差异较小。
总之,在线算法完全胜过离线算法,这也奠定了后续研究的基础。
对于在线和离线算法性能差异的假设
为了更好地理解在线和离线算法性能差异的根源,该团队通过假设验证的形式进行了研究。
也就是说首先提出一些假设,然后验证它是否正确。先来看看他们提出了怎样的假设。
假设 1:数据覆盖情况。在线算法更优的原因是其覆盖的数据比离线数据集更多样化(即随时间变化采样自不同的学习器策略)。
假设 2:次优的离线数据集。离线算法处于劣势,因为其初始的偏好数据集是由一个次优的策略生成的。如果使用有更高绝对质量的响应训练离线算法,则性能会更好。
假设 3:分类能力更好,则性能更好。离线算法通常是将策略作为分类器进行训练。但是,作为分类器,它们可能并不如代理偏好模型那样准确(因为对分类进行参数化的有效方式不同)。如果准确度提升,则其性能也会提升。
假设 4:非对比式损失函数。在这样的性能差异中,有多大部分可归因于对比式的损失函数,而不是离线的样本?
假设 5:扩展策略就足够了。要弥合在线和离线算法之间的差距,只需提升策略大小就足够了。
实验和结果
实验设置
为了验证上述假设,该团队进行了大量对照实验。
所有实验都使用 T5X 模型,并搭配了 T5X 数据和计算框架。为了较好地覆盖 RLHF 问题,他们研究了四种任务:OpenAI 摘要、Anthropic 辅助、聊天竞技场、Anthropic 无害性。
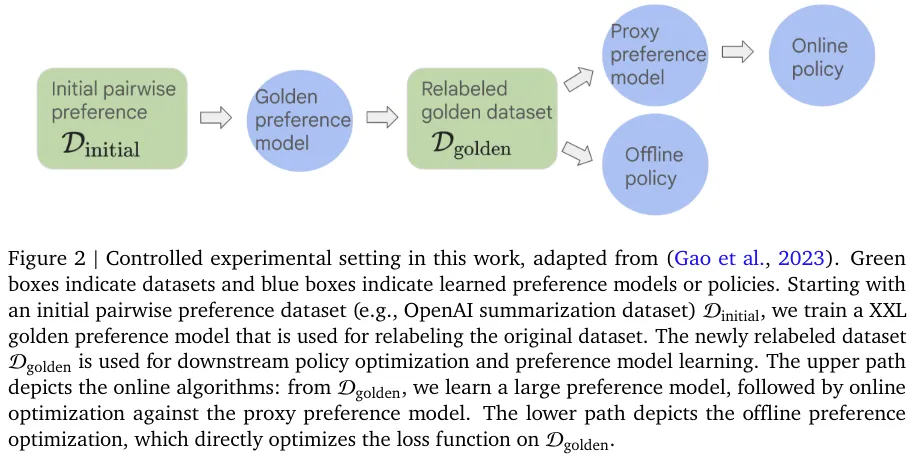
图 2 给出了这些对照实验的设置情况,其整体上基于 Gao et al., 2023。其中,绿框表示数据集,蓝框表示学习到的偏好模型或策略。
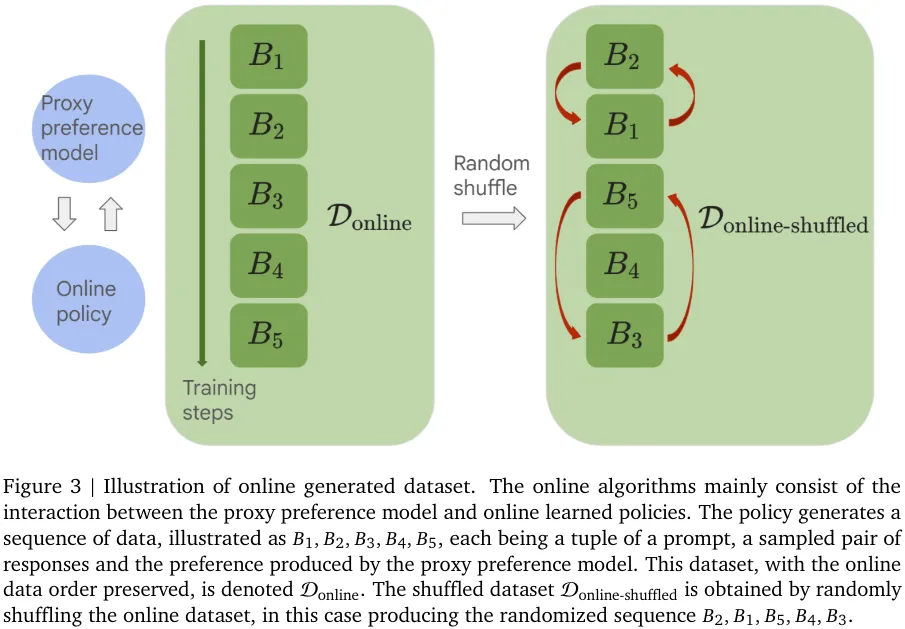
图 3 则给出了在线生成数据集的图示。这里的在线算法主要由代理偏好模型和在线学习的策略之间的交互组成。
该团队的实验研究涉及多个维度,其得到的主要结果如下。
数据
该团队提出的一些假设涉及到离线数据集的性质。其中包括假设离线数据集的覆盖情况比在线生成的数据集差;假设离线算法对离线数据集更敏感,而离线数据集中响应的绝对质量要差一些。(图 4 和图 5 分别证否了这两个假设)。
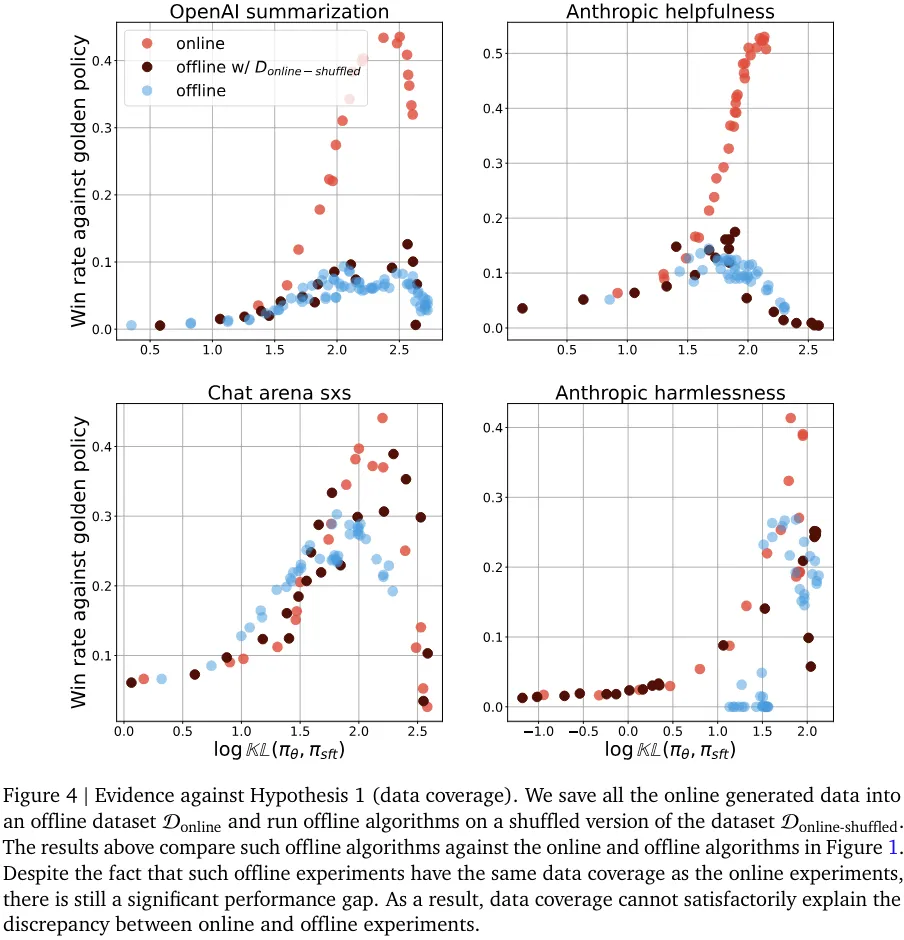
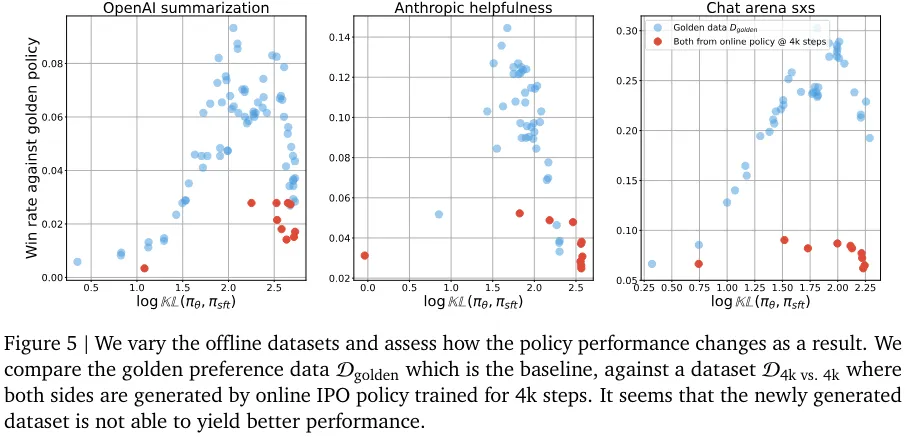
尽管这些假设听上去似乎是对的,但实验结果表明它们无法可信地解释在线和离线算法的性能差距。
他们通过消融研究发现,提升离线优化的一种有效方法是生成分布上接近起始 RLHF 策略(这里就刚好是 SFT 策略)的数据,这本质上就模仿了在线算法的起始阶段。
优化性质
该团队发现判别能力和生成能力之间存在一种有趣的相互作用:尽管离线策略的分类能力胜过在线策略,但离线策略生成的响应却更差(见图 6、7、8)。
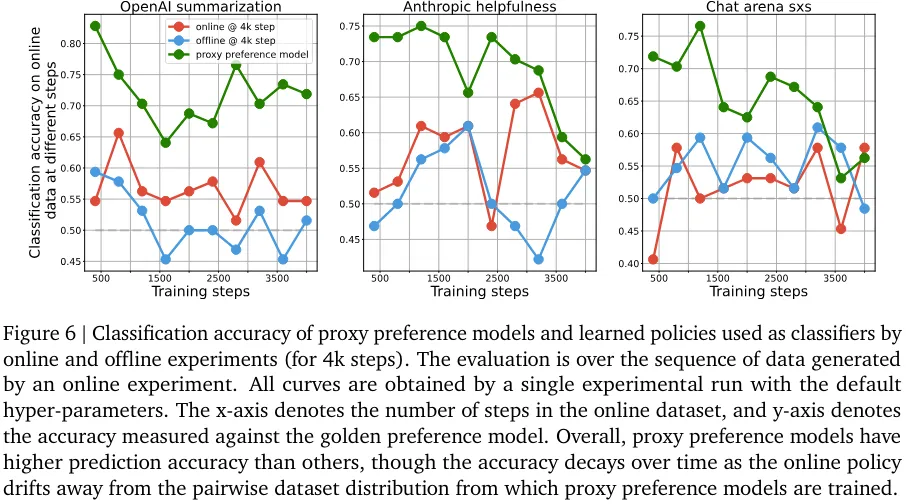
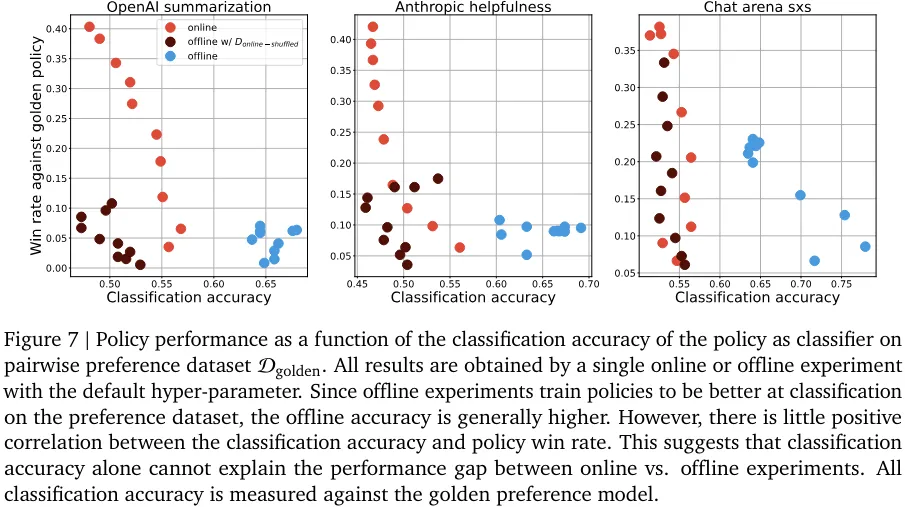
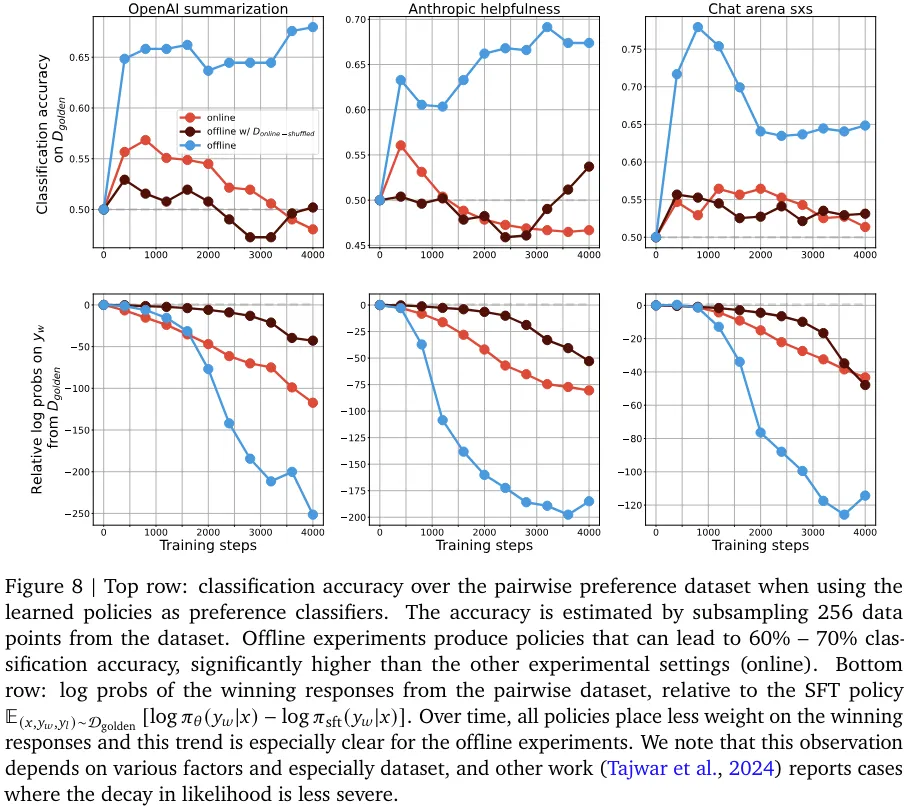
不管是类间分类还是类内分类实验,分类性能和生成性能之间的关联似乎都不大。尽管离线和在线采样都是针对一个判别目标优化的,但离线采样是提升在一个静态数据集上的分类准确度,而在线采样则是通过不断改变采样分布来提升生成质量。实验表明,离线策略的生成性能提升不如在线策略的直接。
损失函数与扩展
为了确保所得结果更普适,他们还研究了用于 RLHF 的对比式和非对比式损失函数。
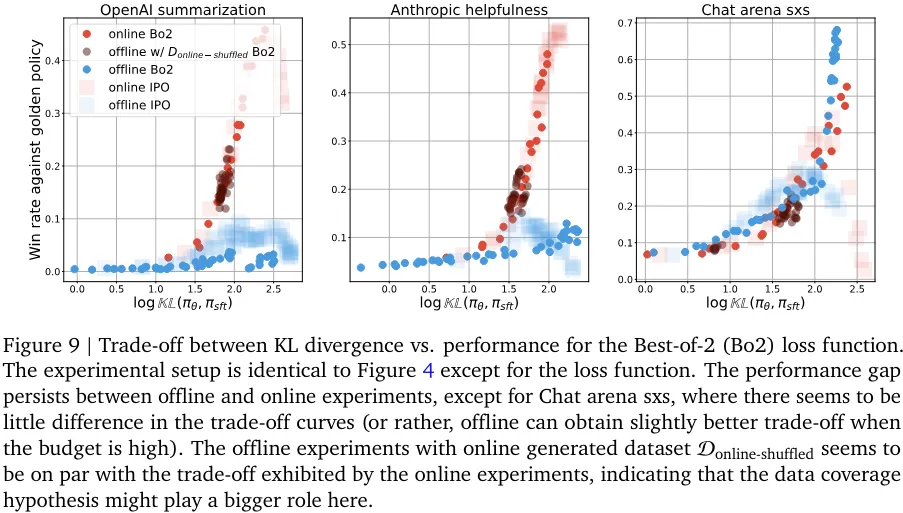
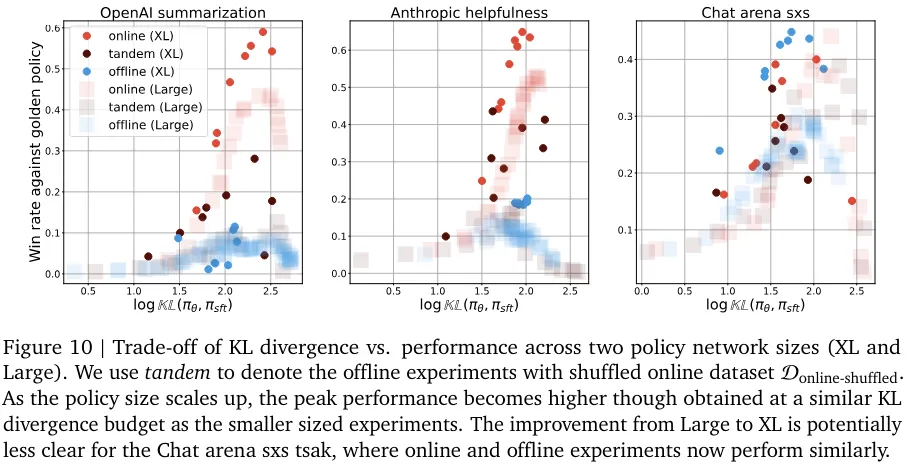
在线与离线性能之间的差距似乎总体上持续存在,尽管这种差异的根本原因可能与算法有关。他们也研究了性能差距随策略网络规模扩展的变化情况(见图 10 和 11)。性能差距一直存在这一事实说明:只是扩展模型规模可能无法解决采样问题。
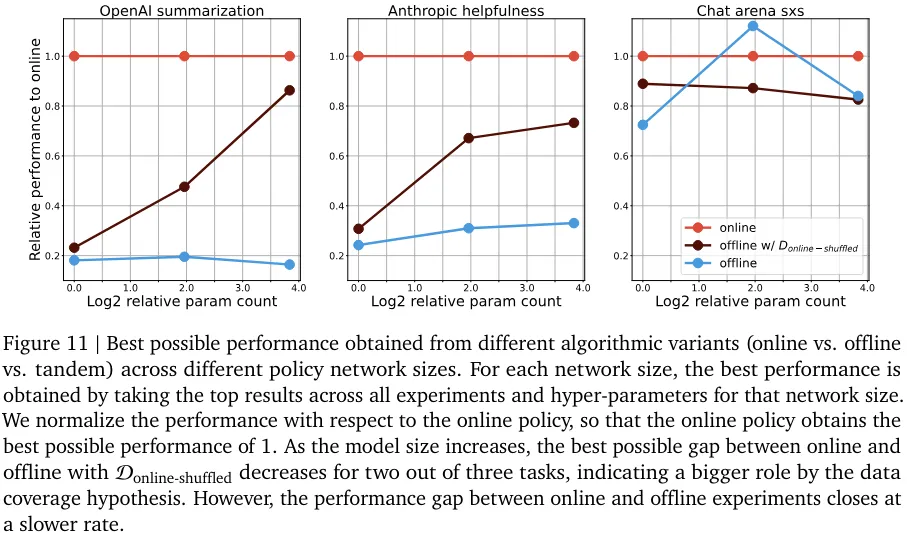
尽管实验结果暗示了在策略采样对模型对齐的根本重要性,但这些结果也许有助于揭示离线对齐算法的实验内部工作原理,并揭示性能差异的根源。总而言之,这些发现为 RLHF 实践者提供了有趣的见解和挑战,并为更有效的 AI 对齐实践铺平了道路。
根据现有的强化学习研究成果,在线比离线更好似乎是显而易见的结论。在线和离线强化学习算法之间的性能差距也已经被多项研究发现,所以这项研究给出了什么不一样的结论呢?
最重要的是,在线 RLHF 算法依赖于一个学习后的奖励模型,该奖励模型是使用与离线 RLHF 算法一样的成对偏好数据集训练得到的。这与常规强化学习设置存在根本性差异 —— 常规强化学习假设能以在线方式获取基本真值奖励,在这种情况下,在线强化学习的优势明显。假设 RLHF 受到奖励信号的瓶颈限制,我们就不清楚在线与离线的差距是否还会这样显著。
从更技术性的角度来看,许多 RLHF 算法采用了上下文赌博机的设计形式,并针对参考策略应用了正则化。这样的算法细节让 RLHF 偏离了常规的强化学习设置,这可能会影响离策略学习问题的严重程度。
如何学习AI大模型?
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

四、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









